[NLP] TF-IDF (Term Frequency - Inverse Document Frequency)
Deep Learning (TF, Keras, PyTorch)/Natural Language Processing 2022. 4. 10. 23:22이번 포스팅에서는 텍스트를 컴퓨터가 이해할 수 있도록 재표현해주는 text representation 방법 중에서 vectorization approaches 의 하나로서 TF-IDF (Term Frequency - Inverse Document Frequency) 의 개념, 수식에 대해서 알아보고, 간단한 예제 텍스트를 사용해서 설명을 해보겠습니다. 그리고 Python 의 Scikit-Learn 모듈을 사용해서 분석을 해보겠습니다.
(1) TF-IDF (Term Frequency - Inverse Document Frequency) 개념 및 예시
(2) Python scikit-learn 모듈을 사용한 실습
(1) TF-IDF (Term Frequency - Inverse Document Frequency) 개념 및 예시
vectorization apporached 의 text representation 방법으로는
- One-Hot Encoding
- Bag of Words (BoW)
- Bag of N-Grams (BoN)
- Term Frequency - Inverse Document Frequency (TF-IDF)
등이 있습니다.
이중에서 One-Hot Encoding, Bag of Words (BoW), Bag of N-Grams (BoN) 의 방법은 텍스트 안의 모든 단어를 동일하게 중요하다고 간주합니다. 반면에, TF-IDF 는 문서와 말뭉치에서 어떤 단어가 주어졌을 때 다른 단어 대비 상대적인 중요도를 측정한다는 차이가 있습니다.
만약 어떤 단어 w 가 문서 Di 에서 자주 나타나지만, 다른 문서 Dj 에서는 별로 나타나지 않을 때, 단어 w 는 문서 Di 에서 매우 중요하다고 볼 수 있습니다.
- TF의 핵심 개념: 단어 w의 중요도는 문서 d(i) 에서 출현하는 빈도에 비례해서 증가.
- IDF의 핵심 개념: 반면에, 단어 w가 말뭉치의 중요도는 다른 문서 d(j) 에서의 출현 빈도에는 비례해서 감소.
TF-IDF 점수는 TF 점수와 IDF 점수를 곱해서 구합니다. (수식은 아래 참조)
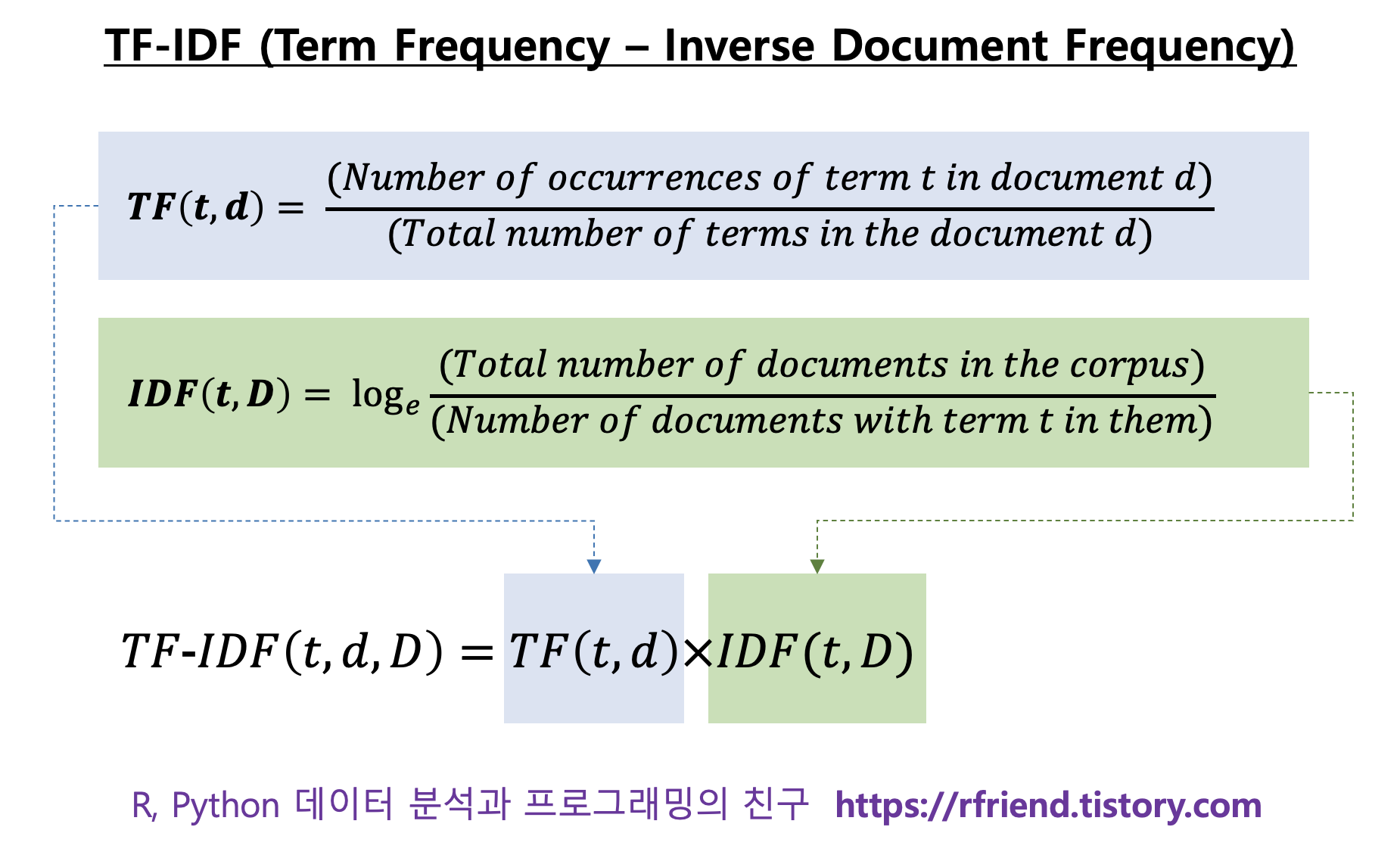
TF (Term Freqneucy) 는 문서(document)에서 주어진 단어(term t) 가 얼마나 자주 출현하는지를 측정합니다. 말뭉치(corpus) 안의 여러 문서들은 길이가 서로 다를텐데요, 아무래도 주어진 단어는 길이가 짧은 문서보다는 길이가 긴 문서에서 더 자주 출현할 가능성이 높습니다. 따라서 이런 문제를 해결하기 위해 문서 d(i)에서 단어 t (term t)의 출현 빈도를 문서 d(i)의 총 단어의 수로 나누어서 표준화를 해줍니다.
TF(t, d) = (문서 d 에서 단어 t 의 출현 빈도) / (문서 d 에서 총 단어의 수)
IDF (Inverse Document Frequency) 는 말뭉치(corpus)에서 단어 t 의 중요도를 측정합니다. 앞서 TF 를 계산할 때 모든 단어에는 동일한 중요도(가중치)가 부여되었습니다. 하지만 관사(a, the), be 동사(is, am, are) 등의 불용어(stop words)와 같이 문서에서 자주 출현하지만 별로 중요하지 않은 단어도 있습니다. 이런 문제를 해결하기 위해, IDF 는 말뭉치의 여러 문서에 공통적으로 출현하는 단어에 대해서는 중요도(가중치)를 낮추고, 반대로 말뭉치의 여러 문서 중에서 일부 문서에만 드물게 출현하는 단어에 대해서는 중요도(가중치)를 높입니다.
IDF(t, D) = log(말뭉치에서 총 문서의 개수 / 단어 t를 포함하는 문서의 개수)
TF-IDF score 는 위의 TF점수와 IDF 점수를 곱해주면 됩니다.
TF-IDF(t, d, D) = TF(t, d) x IDF(t, D)
아래에는 4개의 문서에 나오는 단어를 추출하여 만든 말뭉치를 가지고 TF-IDF 점수를 계산해본 예제입니다.
"Practical Natural Language Processing" (Sowmya Vajjala, et.al. 저) 책의 예제를 사용했는데요, 원서의 계산이 틀렸길레 수정해서 올립니다. (원서에서는 dog와 man의 TF score 가 틀리게 계산됨. IDF score 계산할 때는 밑이 e 이 자연 log 가 아니라 밑이 2인 log를 사용해서 계산함. 암튼, 원서 계산 다 틀렸음)

Bag of Words(BoW)와 비슷하게 TF-IDF 벡터는 코사인 거리(cosine distance)나 유클리디언 거리(euclidean distance) 를 사용하여 두 텍스트의 유사성을 계산하는데 사용할 수 있습니다. TF-IDF 는 정보 추출(information retrieval) 이나 텍스트 분류(text classification)에 많이 사용되고 있습니다.
TF-IDF 는 단어 간의 관계를 파악하는데는 한계가 있습니다. 그리고 TF-IDF 는 텍스트를 희소하고 고차원(sparse and high-dimensional)의 행렬로 표현하므로 차원의 저주(curse of dimensionality) 문제가 있습니다. 또한 학습 데이터셋에 없는 단어에 대해서는 처리를 못하는 한계(Out of Vocabulary problem)가 있습니다.
(2) Python scikit-learn 모듈을 사용한 실습
먼저, 실습에 사용할 텍스트로서 4개 문서의 간단한 문장을 아래와 같이 리스트로 입력해주고, 대문자를 소문자로 변환하고 불용어(stop words)인 마침표(.)는 없애주는 텍스트 데이터 전처리를 해보겠습니다.
## TF-IDF (Term Freqneucy - Inverse Document Frequency)
## input: corpus, terms in documents
documents = ["Dog bites man.", "Man bites dog.", "Dog eats meat.", "Man eats food."]
processed_docs = [doc.lower().replace(".","") for doc in documents]
print(processed_docs)
#['dog bites man', 'man bites dog', 'dog eats meat', 'man eats food']
단어별 TF-IDF 점수 계산은 Python Scikit-Learn 모듈의 TfidfVectorizer 메소드를 사용해서 해보겠습니다.
앞에서 전처리한 텍스트 리스트를 TfidfVectorizer().fit_transform() 메소드를 사용하면 단어 추출과 TF-IDF 점수 계산이 한꺼번에 됩니다.
- tfidf.fit_transform() : 말뭉치 안의 단어 추출 및 TF-IDF 점수 계산
- tfidf.get_feature_names() : 말뭉치 안의 모든 단어 리스트
- sorted(tfidf.vocabulary_.items(), key=lambda x: x[1]) : 단어 사전을 index 기준으로 내림차순 정렬
- tfidf.idf_ : IDF score
##------------------------------
## TF-IDF using sklearn module
##------------------------------
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer()
bow_rep_tfidf = tfidf.fit_transform(processed_docs)
## All words in the vocabulary.
print(tfidf.get_feature_names())
#[Out] ['bites', 'dog', 'eats', 'food', 'man', 'meat']
## sorting vocabulary dict by values in ascending order
sorted(tfidf.vocabulary_.items(), key=lambda x: x[1])
#[Out] [('bites', 0), ('dog', 1), ('eats', 2), ('food', 3), ('man', 4), ('meat', 5)]
## IDF for all words in the vocabulary
print("IDF :",tfidf.idf_)
#[Out] IDF : [1.51082562 1.22314355 1.51082562 1.91629073 1.22314355 1.91629073]
본문 상단에 제시한 예제에서 손으로 계산한 TF-IDF 점수와 아래에 Scikit-learn 의 TfidfVedtorizer() 메소드로 계산한 TF-IDF 점수가 서로 다릅니다.
두가지 이유가 있는데요, 첫째 Scikit-learn 에서 사용한 IDF 수식이 조금 다릅니다. (소스코드 공식은 여기 참조). 분모가 '0' 일때 'Zero Division Error' 가 발생하지 않도록 분모에 '1'을 더해주었으며, 분자에도 log(0) 도 계산이 안되므로 에러가 발생하지 않도록 분자에도 '1' 을 더해주었고, 전체 값이 '1'을 더해주었습니다.
Scikit-Learn의 IDF 공식: IDF(t) = log((1+n) / (1+df(t))) + 1
Scikit-Learn의 TF-IDF score 가 원래 TF-IDF 결과와 다른 두번째 이유는 위의 Scikit-Learn 의 TF-IDF 점수 계산 결과를 유클리디언 거리를 사용해서 표준화를 해주기 때문입니다. (자세한 설명은 여기 참조)
## IDF for all words in the vocabulary
## “Sklearn’s TF-IDF” vs “Standard TF-IDF”
## : https://towardsdatascience.com/how-sklearns-tf-idf-is-different-from-the-standard-tf-idf-275fa582e73d
## Scikit-Learn's IDF: IDF(t) = log((1+n)/(1+df(t))) + 1
## normalization by the Euclidean norm
print("IDF :",tfidf.idf_)
#[Out] IDF : [1.51082562 1.22314355 1.51082562 1.91629073 1.22314355 1.91629073]
# IDF for 'dog' word
# number of documents, nN=4
# number of documents which include term t, df(t) = 3
import numpy as np
np.log((1+4)/(1+3)) + 1 # IDF(t) = log((1+n)/(1+df(t))) + 1
#[Out] 1.2231435513142097
- bow_rep_tfidf.toarray() : 말뭉치의 모든 문서 내 단어에 대한 TF-IDF 점수를 2차원 배열로 표현
## TF-IDF representation for all documents in our corpus
print("TF-IDF representation for all documents in our corpus\n", bow_rep_tfidf.toarray())
#[Out] TF-IDF representation for all documents in our corpus
# [[0.65782931 0.53256952 0. 0. 0.53256952 0. ]
# [0.65782931 0.53256952 0. 0. 0.53256952 0. ]
# [0. 0.44809973 0.55349232 0. 0. 0.70203482]
# [0. 0. 0.55349232 0.70203482 0.44809973 0. ]]
- tfidf.transform(new document) : 새로운 문서 내 단어에 대한 TF-IDF 점수 계산
## Get the TF-IDF score using this vocabulary, for a new text
temp = tfidf.transform(["dog and man are friends"])
print("Tfidf representation for 'dog and man are friends':\n", temp.toarray())
#[Out] Tfidf representation for 'dog and man are friends':
# [[0. 0.70710678 0. 0. 0.70710678 0. ]]
[Reference]
(1) Sowmya Vajjala, et.al., "Practical Natural Language Processing", O'Reilly
(2) Scikit-learn TfidfVectorizer methods
: https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html
(3) Scikit-learn TfidfTransformer (--> check out the formula of TF-IDF in sklearn module)
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)

'Deep Learning (TF, Keras, PyTorch) > Natural Language Processing' 카테고리의 다른 글
| OpenAI ChatGPT API 사용하는 방법 (0) | 2023.03.19 |
|---|---|
| [Python] 텍스트 데이터 전처리 및 토큰화 (Tokenization) (0) | 2022.08.01 |
| [NLP] 언어 구조의 구성 요소 (Building Blocks of Language Structure) (0) | 2022.02.20 |
| [NLP] 자연어 처리(NLP, Natural Language Processing)란 무엇이고, NLP 응용분야는 무엇이 있나? (0) | 2022.02.20 |
| [Python] 텍스트로부터 CSR 행렬을 이용하여 Term-Document 행렬 만들기 (0) | 2020.09.13 |



