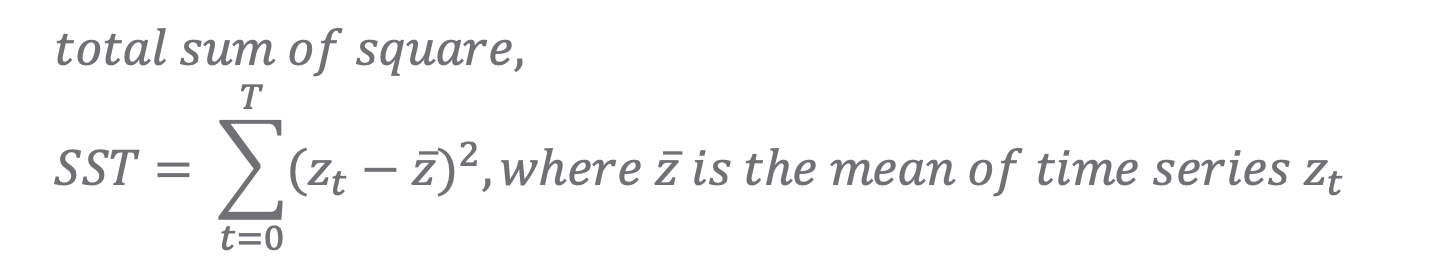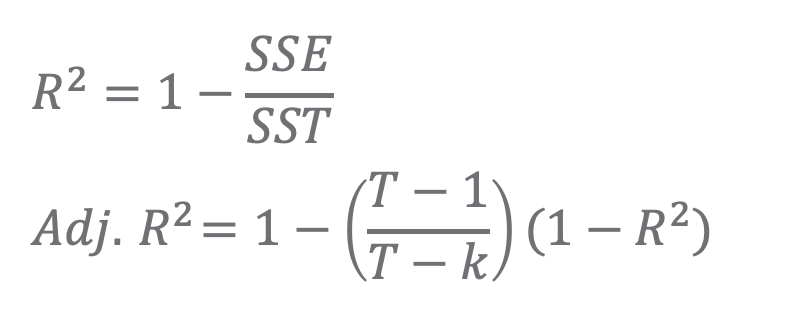이전 포스팅에서 시계열 데이터를 예측하는 분석 방법 중의 하나로서 지수평활법(exponential smoothing)을 소개하였습니다. 지수평활법은 통계적인 이론 배경이 있다기 보다는 경험적으로 해보니 예측이 잘 맞더라는 경험에 기반한 분석기법으로서, 데이터가 어떤 확률과정(stochastic process)을 따라야 한다는 가정사항이 없습니다.
반면에, ARIMA (AutoRegressive Integreated Moving Average) 모형은 확률모형을 기반으로 한 시계열 분석 기법으로서, 정상확률과정(Stationary Process)을 가정합니다. 만약 시계열 데이터가 정상성(stationarity) 가정을 만족하지 않을 경우 데이터 전처리를 통해서 정상시계열(stationary time series)로 변환해 준 다음에야 ARIMA 모형을 적용할 수 있습니다.
이번 포스팅에서는
(1) 백색잡음과정 (White Noise Process)
(2) 확률보행과정 (Random Walk Process)
(3) 정상확률과정 (Stationary Process)
에 대해서 소개하겠습니다. 특히, 백색잡음과정, 확률보행과정과 비교해서, ARIMA 모형이 가정하는 "정상확률과정"에 대해서 유심히 살펴보시기 바랍니다.
[ 백색잡음과정(white noise) vs. 확률보행과정 (random walk) vs. 정상확률과정 (stationary process) ]
white noise vs. random walk vs. stationary process
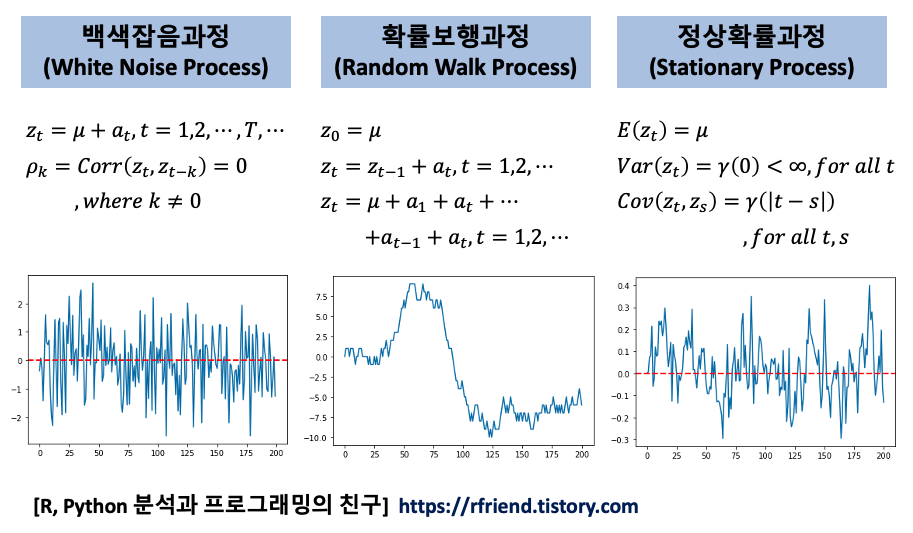
(1) 백색잡음과정 (White Noise Process)
신호처리 분야에서 백색잡음(white noise)은 다른 주파수에서 동일한 강도를 가지고, 항상 일정한 스펙트럼 밀도를 발생시키는 무작위한 신호를 의미합니다. 백색잡음 개념은 물리학, 음향공학, 통신, 통계 예측 등 다양한 과학과 기술 분야에서 광범윟게 사용되고 있습니다.
시계열 데이터 통계 분석에서 백색잡음과정(white noise process)은 평균이 0, 분산은 유한한 상수(sigma^2)인 확률분포(random variables)로 부터 서로 상관되지 않게(uncorrelated) 무작위로 샘플을 추출한 이산 신호(discrete signal)를 말합니다.
white noise process
특히, 평균이 0 인 동일한 정규분포로부터 서로 독립적으로 샘플을 추출한 백색잡음을 가법 백색 가우시언 잡음(additive white Gaussian noise) 라고 합니다. 아래 Python 코드는 평균이 0, 분산이 1인 정규분포로부터 200개의 백색잡음 샘플을 추출하고 시각화 해본 것입니다.
import numpy as np
import matplotlib.pyplot as plt
## generating white noise from normal distribution
x1 = np.random.normal(0, 1, 200) # additive white Gaussian noise
plt.plot(x1, linestyle='-') # marker='o'
## addidng horizontal line at mean '0'
plt.axhline(0, 0, 200, color='red', linestyle='--', linewidth=2)
plt.show()
white Gaussian noise
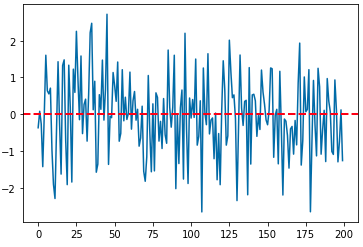
(2) 확률보행과정 (Random Walk Process)
수학에서 확률보행과정(random walk process)은 어떤 수학적인 공간 (예: 정수)에서 연속적인 무작위 스텝의 이동경로를 묘사하는 수학적인 객체를 말합니다.
가장 기본적인 확률보행과정의 예를 들자면, 동전을 던져서 앞면이 나오면(0.5의 확률) 위(up)로 +1 계단을 올라가고, 동전의 뒷면이 나오면(0.5의 확률) 아래(down)로 -1 계단을 내려가는 보행과정을 생각해 볼 수 있습니다. 액체나 기체 속에서 분자가 이동하는 경로를 추적한 브라운 운동(Brownian motion), 수렵채집을 하는 동물의 탐색경로, 요동치는 주식의 가격, 도박꾼의 재무상태 등을 확률보행과정으로 설명할 수 있습니다.
아래의 Python 코드는 위로(up)로 0.3의 확률, 아래(down)로 0.7의 발생확률을 가지고 계단을 오르락 내리락 하는 확률보행과정을 만들어보고, 이를 시각화해 본 것입니다. 마치 잠깐 상승하다가 하락장으로 돌아선 주식시장 차트 같이 생기지 않았나요?
# Probability to move up or down
prob = [0.3, 0.7]
# starting position
start = 0
rand_walks = [start]
# creating the random points
rr = np.random.random(200)
downp = rr < prob[0]
upp = rr >= prob[1]
# random walk process
# z(t) = z(t-1) + a(t), where a(t) is white noise
for idown, iup in zip(downp, upp):
rand_walks.append(rand_walks[-1] - idown + iup)
# plot
plt.plot(rand_walks)
plt.show()
random walk process (example)
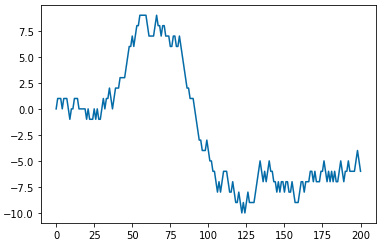
(3) 정상확률과정 (Stationary Process)
서두에서 ARIMA 시계열 통계모형은 시계열 데이터의 정상성(stationarity) 조건을 만족하는 경우에 사용할 수 있다고 했습니다. 정상확률과정은 다음의 세 조건을 만족하는 확률과정을 말합니다.
[ 정상시계열의 조건 (conditions for stationary time series)]
(a) 평균이 일정하다.
(b) 분산이 존재하며 상수이다.
(c) 두 시점 사이의 자기공분산은 시차(time lag)에만 의존한다.
만약 추세(trend)가 있거나 시간이 갈 수록 분산이 커지거나 작아지는 시계열 데이터라면 정상확률과정 시계열이 아닙니다. 추세가 있거나 분산이 달라지게 되면 ARIMA 모형을 적합하기 전에, 먼저 추세를 없애 주고 분산을 안정화 시켜주는 변환을 통해 정상확률과정으로 만들어주어야 합니다.
stationary process 정상확률과정
정상확률과정 중에서 대표적인 모수적 확률모형은 ARMA(p, q) 로 표기되는 자기회귀이동평균과정(AutoRegressive Moving Average Process) 입니다. 아래의 Python 코드는 AR(1) 인 자기회귀과정을 생성해서 시각화해본 것입니다.
AR(1) 과정: z(t) = Phi * z(t-1) + a(t)
(이때 Phi 는 절대값이 1 미만이고, a(t) 는 평균이 0이고 분산이 sigma^2 인 백색잡음과정임.)
## Stationary Process
## exmaple: AR(1) process
z_0 = 0
rho = 0.65 # correlation b/w z(t) and z(t-1)
z_all = [z_0]
for i in range(200):
z_t = rho*z_all[i] + np.random.normal(0, 0.1, 1)
z_all.append(z_t)
## plotting
plt.plot(z_all)
## adding horizonal line at mean position 0
plt.axhline(0, 0, 200, color='red', linestyle='--', linewidth=2)
plt.show()
stationary process plot (example)
위의 1번의 백색잡음과정과 3번의 정상확률과정이 눈으로만 봐서는 구분이 잘 안가지요?
백색잡음과정, 확률보행과정, 정상확률과장이 서로 관련이 있고, 얼핏 봐서는 비슷하기도 해서 참 헷갈립니다. 정확하게 이 셋을 구분해서 이해하시기 바래요.
이번 포스팅에서는 주기성을 가지는 센서 시계열 데이터, 음향 데이터, 신호 처리 데이터 등에서 많이 사용되는 스펙트럼 분석 (spectral analysis) 에 대해서 소개하겠습니다.
많은 시계열 데이터는 주기적인 패턴 (periodic behavior) 을 보입니다. 스펙트럼 분석 은 시계열 데이터에 내재되어 있는 주기성(periodicity) 을 찾아내는 분석기법으로서, spectral analysis, spectrum analysis, frequency domain analysis 등의 이름으로 불립니다.
스펙트럼 분석을 할 때 우리는 먼저 시계열 데이터를 시간 영역(time domain)에서 주파수 영역(frequency domain)로 변환을 합니다. 시계열의 공분산은 스펙트럼 확률밀도함수 (spectral density function) 로 알려진 함수로 재표현될 수 있습니다. 스펙트럼 밀도함수는 시계열과 다른 주파수의 사인/코사인 파동 간의 제곱 상관계수로 구하는 주기도(periodogram) 를 사용하여 추정할 수 있습니다. (Venables & Ripley, 2002)
아래의 그림은 시계열(time series)과 스펙트럼(spectrum, frequency) 간의 관계를 직관적으로 이해할 수 있게 도와줍니다.
[ Time Series vs. Spectrum/ Frequency, Fourier Transform(FT) vs. Inverse FT ]
time-series vs. spectrum
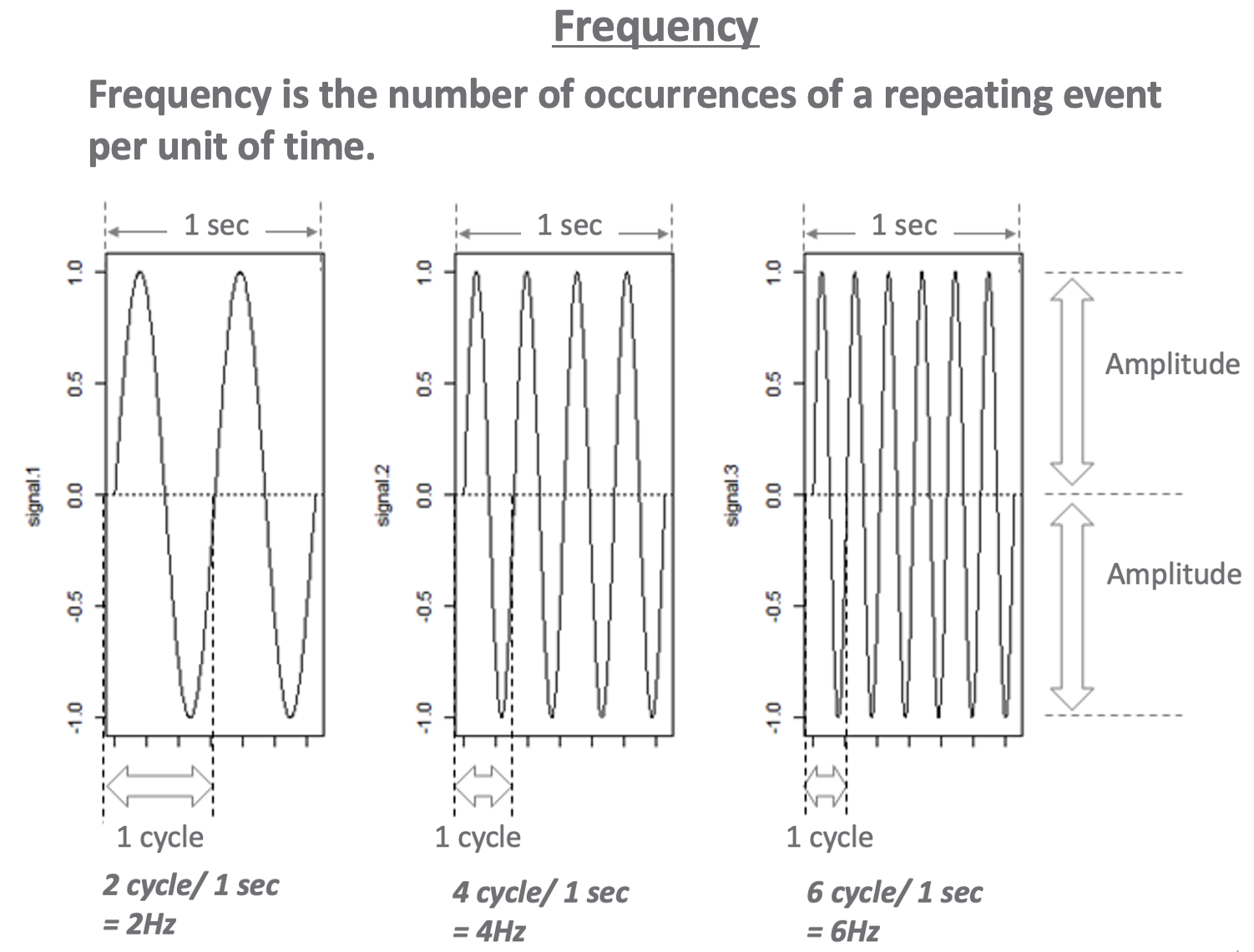
참고로, 주파수(frequency)는 단위 시간 당 반복되는 이벤트가 발생하는 회수를 의미합니다. 주파수를 측정하는데 사용되는 단위인 Hz (Hertz, 헤르쯔) 는 전자기파의 존재를 처음으로 증명한 Heinrich Rudolf Hertz 의 이름에서 따온 것인데요, 가령 2 Hz 는 1초에 2번의 반복 사이클이 발생하는 시계열의 경우, 4 Hz 는 1초에 4번의 반복 사이클이 발행하는 시계열의 주파수에 해당합니다. (아래 그림 예시 참조)
frequency (* https://rfriend.tistory.com)
주기성을 띠는 시계열 데이터나 공간 데이터로 부터 주파수 (spectrum, frequency) 를 계산하거나, 반대로 주파수로 부터 원래의 데이터로 변환할 때 고속 푸리에 변환 (Fast Fourier Transform, 줄여서 FFT) 알고리즘을 많이 사용합니다. 시계열을 주파수로 변환하는 과정 자체를 Fourier Transform 이라고 하며, 이산 푸리에 변환 (Discrete Fourier Transform, DFT) 은 시계열 값을 다른 주파수의 구성요소들로 분해함으로써 구할 수 있습니다. 지금까지 가장 널리 사용되는 고속 푸리에 변환 (FFT) 알고리즘은 Cooley-Tukey 알고리즘 입니다. 이것은 분할-정복 알고리즘 (divide-and-conqer algorithm) 으로서, 반복적으로(recursively) 원래의 시계열 데이터를 훨씬 적은 개수의 주파수로 분할합니다.
[ Fast Fourier Transform(FFT) vs. Inverse FFT]
FFT vs. Inverse FFT
이제 Python 의 spectrum 모듈을 사용해서 스펙트럼 분석을 해보겠습니다. 터미널에서 $ pip install spectrum 으로 먼저 spectrum 모듈을 설치해줍니다.
## installment of spectrum python library at a terminal
$ pip install spectrum
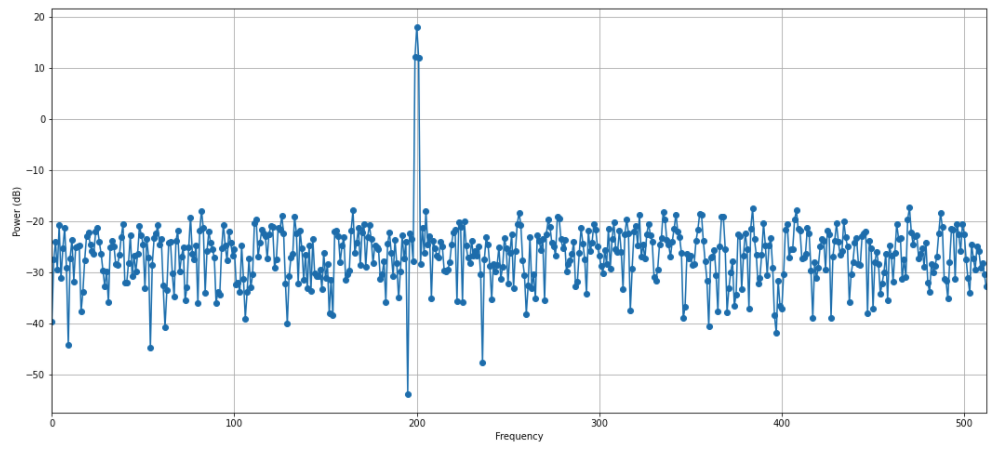
예제로 사용할 샘플데이터로서, data_cosine() 메소드를 사용해서 200 Hz 주파수 (freq=200) 의 주기성을 띠는 코사인 신호(cosine signal)에 백색 잡음 (amplitude 0.1) 도 포함되어 있는 이산형 샘플 데이터 1,024개 (N=1024, sampling=1024) 를 생성해보겠습니다.
## -- importing modules
from spectrum import Periodogram, data_cosine
## generating a toy data sets
## data contains a cosine signal with a frequency of 200Hz
## buried in white noise (amplitude 0.1).
## The data has a length of N=1024 and the sampling is 1024Hz.
data = data_cosine(N=1024, A=0.1, sampling=1024, freq=200)
## plotting the generated data
plt.rcParams['figure.figsize'] = [18, 8]
plt.plot(data)
plt.show()
위의 시계열 그래프가 1,024개 데이터 포인트가 모두 포함되다보니 코사인 신호의 주기성이 눈에 잘 안보이는데요, 앞 부분의 50개만 가져다가 시도표로 그려보면 아래처럼 코사인 파동 모양의 주기성을 띠는 데이터임을 눈으로 확인할 수 있습니다.
spectrum 모듈의 Periodogram() 메소드에 위에서 생성한 샘플 데이터를 적용해서 periodogram 객체를 만든 후에 run() 함수를 실행시켜서 스펙트럼을 추정할 수 있고, p.plot() 으로 간단하게 추정한 스펙트럼을 시각화할 수 있습니다.
## the Power Spectrum Estimation method provided in spectrum.
## creating an object Periodogram.
p = Periodogram(data, sampling=1024)
## running the spectrum estimation
p.run() # or p()
p.plot(marker='o')
스펙트럼 분석 결과 중 개수(N), 주파수의 세기 (power of spectrum dendity) 속성값을 확인할 수 있습니다.
## some information are stored and can be retrieved later on.
p.N
[Out] 1024
p.psd
# [Out] array([1.06569152e-04, 1.74100855e-03, 3.93335837e-03, 1.10485152e-03,
# 8.28499278e-03, 7.64848301e-04, 2.94332240e-03, 7.35029918e-03,
# 1.21273520e-03, 3.72342384e-05, 1.87058542e-03, 4.35817479e-03,
# 6.60803332e-04, 3.01094523e-03, 3.14914528e-03, 3.40040266e-03,
# 1.70112710e-04, 4.04579597e-04, 1.73102721e-03, 5.17048610e-03,
# 5.89537834e-03, 3.43004928e-03, 2.60894164e-03, 2.29556960e-03,
# 6.23836725e-03, 7.35588289e-03, 3.88793797e-03, 2.25691304e-03,
# ... 중간 생략함 ...
# 2.57852156e-03, 1.23483225e-03, 1.49139300e-03, 9.09082081e-04,
# 5.24999741e-04])
우리가 위에서 data_cosine(N=1024, A=0.1, sampling=1024, freq=200) 메소드를 사용해서 200 Hz 의 데이터를 생성하였기 때문에, 이 샘플 데이터로부터 주파수를 분해하면 200 Hz 가 되어야 할텐데요, 스펙트럼 분석 결과도 역시 200 Hz 에서 스파이크가 엄청 높게 튀는군요.
이번 포스팅에서는 Python의 matplotlib 모듈을 사용하여, X축의 값은 동일하지만 Y축의 값은 척도가 다르고 값이 서로 크게 차이가 나는 2개의 Y값 데이터에 대해서 이중축 그래프 (plot with 2 axes for a dataset with different scales)를 그리는 방법을 소개하겠습니다.
먼저 간단한 예제 데이터셋을 만들어보겠습니다.
* x 축은 2021-10-01 ~ 2021-10-10 일까지의 10개 날짜로 만든 index 값을 동일하게 사용하겠습니다.
* y1 값은 0~9 까지 정수에 표준정규분포 Z~N(0, 1) 로 부터 생성한 난수를 더하여 만들었습니다.
다음으로 이를 해결하기 위한 방법 중의 하나로서 matplotlib을 사용해 2중축 그래프를 그려보겠습니다.
(* 참고로, 2중축 그래프 외에 서로 다른 척도(scale)의 두개 변수의 값을 표준화(standardization, scaling) 하여 두 변수의 척도를 비교할 수 있도록 변환해준 후에 하나의 축에 두 변수를 그리는 방법도 있습니다.)
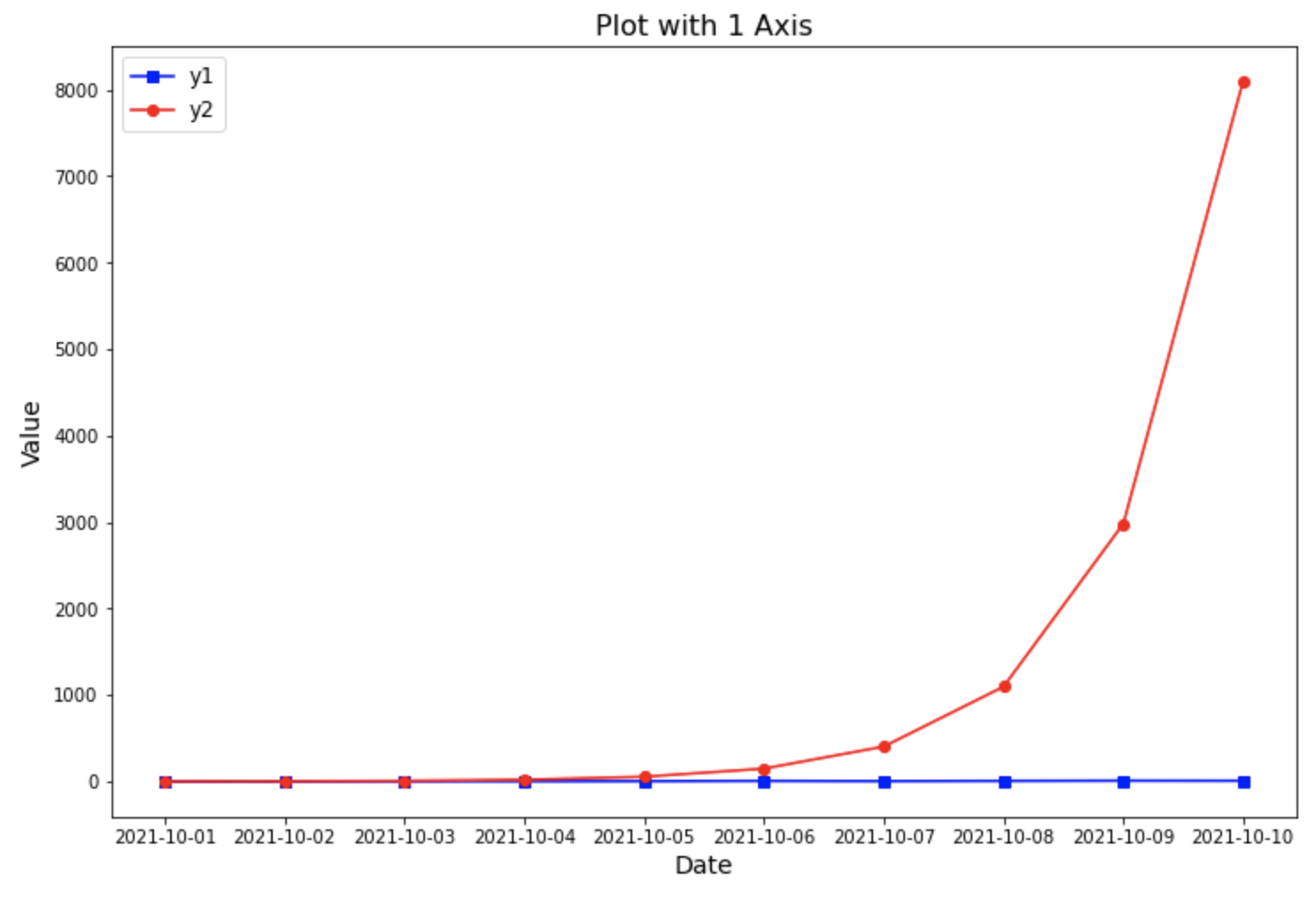
(1) 스케일이 다른 2개의 y값 변수를 1중축 그래프에 그렸을 때 문제점
==> 스케일이 작은 쪽의 y1 값이 스케일이 큰 쪽의 y2 값에 압도되어 y1 값의 패턴을 파악할 수 없음. (스케일이 작은 y1값의 시각화가 의미 없음)
## scale이 다른 데이터를 1개의 y축만을 사용해 그린 그래프
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot()
ax.plot(df.index, df.y1, marker='s', color='blue')
ax.plot(df.index, df.y2, marker='o', color='red')
plt.title('Plot with 1 Axis', fontsize=16)
plt.xlabel('Date', fontsize=14)
plt.ylabel('Value', fontsize=14)
plt.legend(['y1', 'y2'], fontsize=12, loc='best')
plt.show()
plot with 1 axis for a dataset with the different scales
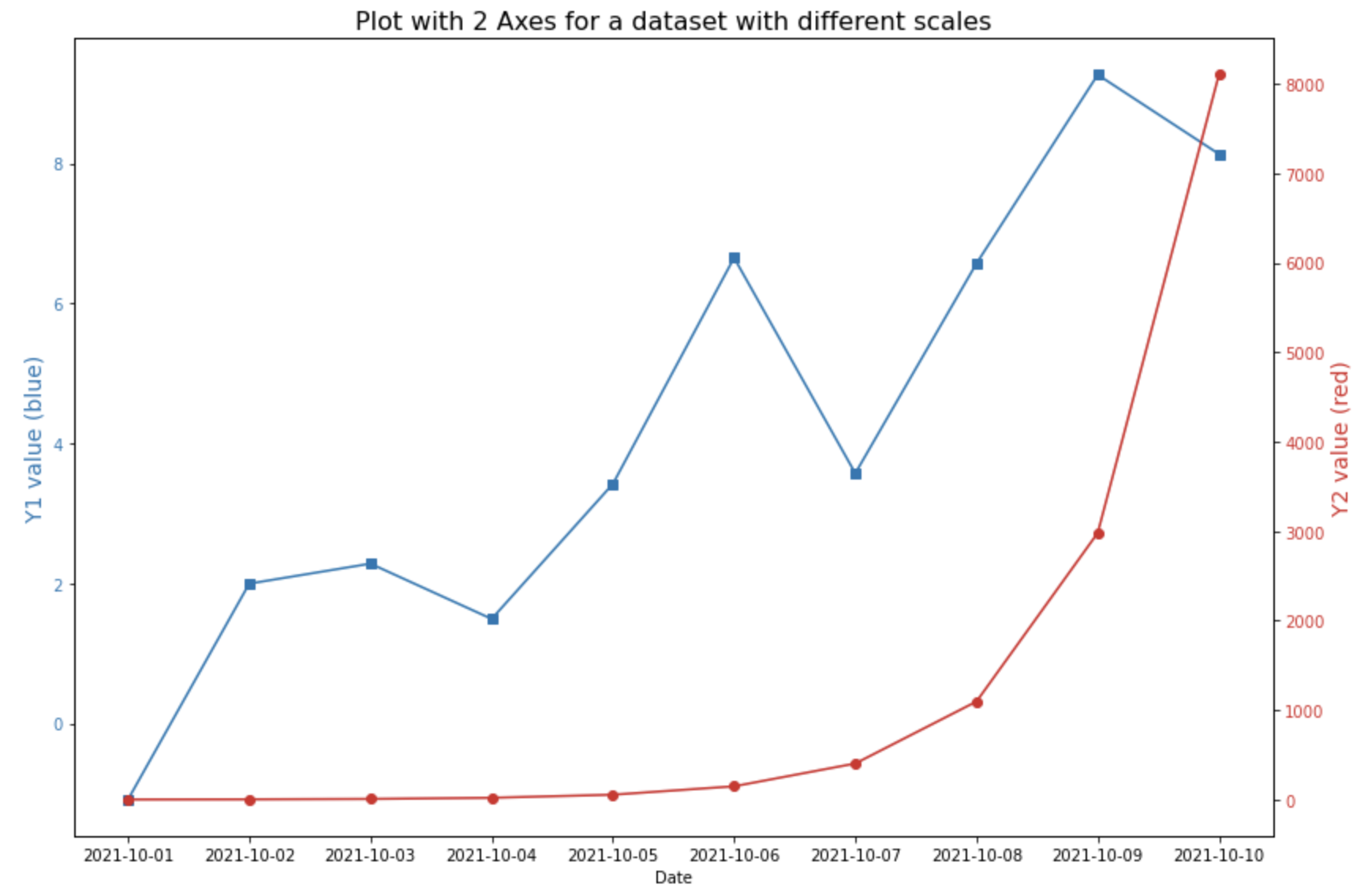
(2) 스케일이 다른 2개의 변수에 대해 2중축 그래프 그렸을 때
==> 각 y1, y2 변수별 스케일에 맞게 적절하게 Y축이 조정이 되어 두 변수 값의 패턴을 파악하기가 쉬움
이때, 가독성을 높이기 위해서 각 Y축의 색깔, Y축 tick의 색깔과 그래프의 색깔을 동일하게 지정해주었습니다. (color 옵션 사용)
## plot with 2 different axes for a dataset with different scales
# left side
fig, ax1 = plt.subplots()
color_1 = 'tab:blue'
ax1.set_title('Plot with 2 Axes for a dataset with different scales', fontsize=16)
ax1.set_xlabel('Date')
ax1.set_ylabel('Y1 value (blue)', fontsize=14, color=color_1)
ax1.plot(df.index, df.y1, marker='s', color=color_1)
ax1.tick_params(axis='y', labelcolor=color_1)
# right side with different scale
ax2 = ax1.twinx() # instantiate a second axes that shares the same x-axis
color_2 = 'tab:red'
ax2.set_ylabel('Y2 value (red)', fontsize=14, color=color_2)
ax2.plot(df.index, df.y2, marker='o', color=color_2)
ax2.tick_params(axis='y', labelcolor=color_2)
fig.tight_layout()
plt.show()
plot with 2 axes for a dataset with different scales
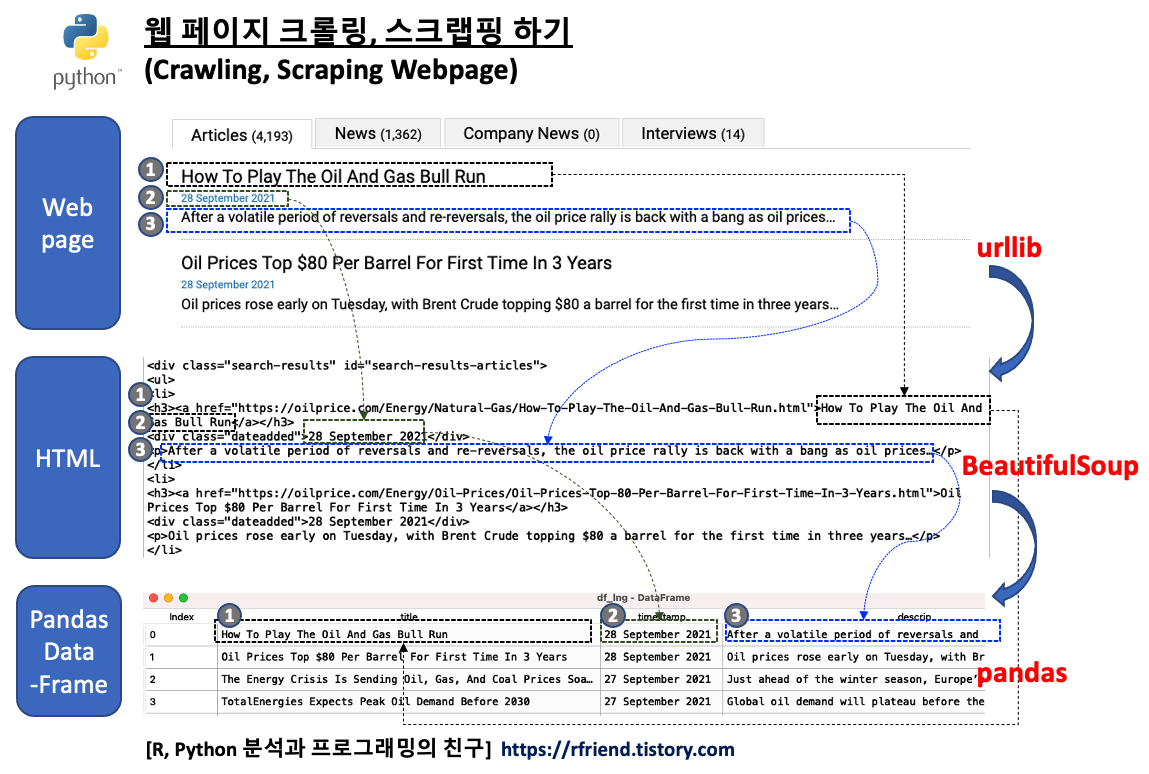
이번 포스팅에서는 Python의 urllib 과 BeautifulSoup 모듈을 사용해서 웹 페이지의 내용을 파싱하여 필요한 데이터만 크롤링, 스크래핑하는 방법을 소개하겠습니다.
urllilb 모듈은 웹페이지 URL 을 다룰 때 사용하는 Python 라이브러리입니다. 가령, urllib.request 는 URL을 열고 읽을 때 사용하며, urllib.parse 는 URL을 파싱할 때 사용합니다.
BeautifulSoup 모듈은 HTML 과 XML 파일로부터 데이터를 가져올 때 사용하는 Python 라이브러리입니다. 이 모듈은 사용자가 선호하는 파서(parser)와 잘 작동하여, parse tree 를 조회하고 검색하고 수정하는 자연스러운 방법을 제공합니다.
python urllib, BeautifulSoup module for web scraping
이번 예제에서는
(1) urllib.request 의 urlopen 메소드로 https://oilprice.com/ 웹페이지에서 'lng' 라는 키워드로 검색했을 때 나오는 총 20개의 페이지를 열어서 읽은 후
(2) BeautifulSoup 모듈을 사용해 기사들의 각 페이지내에 있는 20개의 개별 기사들의 '제목(title)', '기사 게재일(timestamp)', '기사에 대한 설명 (description)' 의 데이터를 파싱하고 수집하고,
(3) 이들 데이터를 모아서 pandas DataFrame 으로 만들어보겠습니다. (총 20개 페이지 * 각 페이지별 20개 기사 = 총 400 개 기사 스크랩핑)
webpage crawling, scraping using python urllib, BeautifulSoup, pandas
아래의 예시 코드는 파송송님께서 짜신 것이구요, 각 검색 페이지에 20개씩의 기사가 있는데 제일 위에 1개만 크롤링이 되는 문제를 해결하는 방법을 문의해주셔서, 그 문제를 해결한 후의 코드입니다.
##-- How to Scrape Data on the Web with BeautifulSoup and urllib
from bs4 import BeautifulSoup
from urllib.request import urlopen
import pandas as pd
from datetime import datetime
col_name = ['title', 'timestamp', 'descrip']
df_lng = pd.DataFrame(columns = col_name)
for j in range(20):
## open and read web page
url = 'https://oilprice.com/search/tab/articles/lng/Page-' + str(j+1) + '.html'
with urlopen(url) as response:
soup = BeautifulSoup(response, 'html.parser')
headlines = soup.find_all(
'div',
{'id':'search-results-articles'}
)[0]
## getting all 20 titles, timestamps, descriptions on each page
title = headlines.find_all('a')
timestamp = headlines.find_all(
'div',
{'class':'dateadded'}
)
descrip = headlines.find_all('p')
## getting data from each article in a page
for i in range(len(title)):
title_i = title[i].text
timestamp_i = timestamp[i].text
descrip_i = descrip[i].text
# appending to DataFrame
df_lng = df_lng.append({
'title': title_i,
'timestamp': timestamp_i,
'descrip': descrip_i},
ignore_index=True)
if j%10 == 0:
print(str(datetime.now()) + " now processing : j = " + str(j))
# remove temp variables
del [col_name, url, response, title, title_i, timestamp, timestamp_i, descrip, descrip_i, i, j]
시계열 데이터를 분석할 때 꼭 확인하고 처리해야 하게 있는데요, 바로 결측값 여부 확인과 결측값 처리입니다.
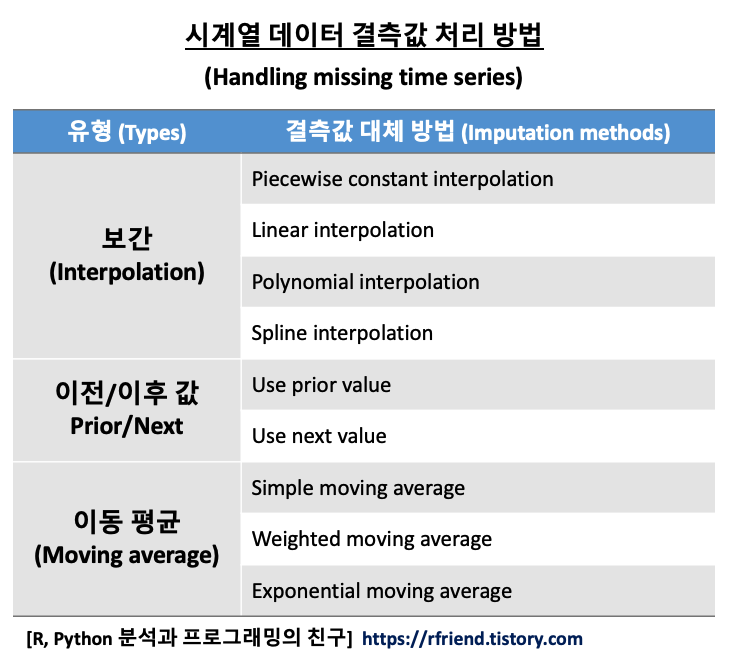
시계열 데이터의 결측값을 처리하는 방법에는
(1) 보간 (Interpolation)
(2) 이전 값 또는 다음 값 이용 (previous/next value)
(3) 이동 평균 (Moving average)
등의 여러가지 방법이 있습니다.
[ 시계열 데이터 결측값 처리 방법 (How to handle the time series missing data) ]
아래의 보간(Interpolation)에 대한 내용은 Wikipedia 의 내용을 번역하여 소개합니다.
데이터 분석의 수학 분야에서는 "보간법(Interpolation)을 이미 알려진 데이터 포인트들의 이산형 집합의 범위에 기반해서 새로운 데이터 포인트들을 만들거나 찾는 추정(estimation)의 한 유형"으로 봅니다.
공학과 과학 분야에서는 종종 샘플링이나 실험을 통해서 많은 수의 데이터 포인트들을 획득하는데요, 이들 데이터는 어떤 함수(a function)의 값이나 독립변수(independent variable)의 제한적인 수의 값을 표현한 것입니다. 종종 독립변수의 중간 사이의 값을 위한 함수의 값을 추정(estimate the value of that function for an intermediat value of the independent variable)하는 보간이 필요합니다.
밀접하게 관련된 문제로서 복잡한 함수를 간단한 함수로 근사하게 추정(the approximation of a complicated function by a simple function)하는 것이 있습니다. 어떤 주어진 함수의 공식이 알려져있지만, 너무 복잡해서 효율적으로 평가하기가 어렵다고 가정해봅시다. 원래의 함수로부터 적은 수의 새로운 데이터 포인트는 원래의 값과 상당히 근접한 간단한 함수를 생성해서 보간할 수 있습니다. 단순성(simplicity)으로부터 얻을 수 있는 이득이 보간에 의한 오차라는 손실보다 크고, 연산 프로세스면서도 더 좋은 성능(better performance in calculation process)을 낼 수도 있습니다.
이번 포스팅에서는 Python scipy 모듈을 이용해서 시계열 데이터 결측값을 보간(Interpolation)하는 방법을 소개하겠습니다.
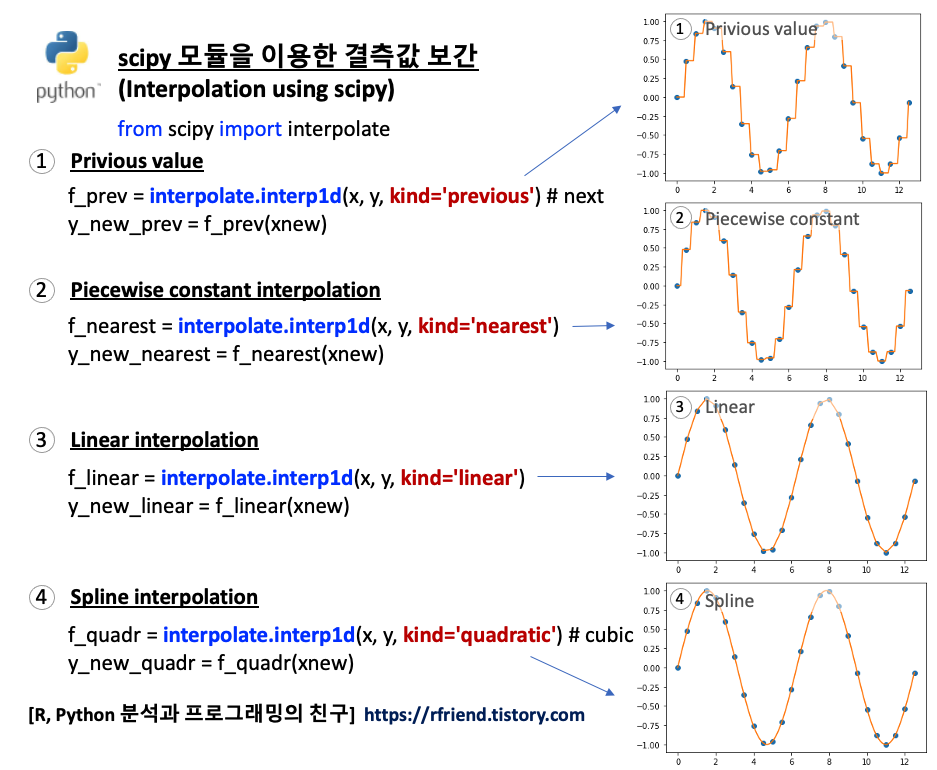
1. 이전 값/ 이후 값을 이용하여 결측값 채우기 (Imputation using the previous/next values)
2. Piecewise Constant Interpolation
3. 선형 보간법 (Linear Interpolation)
4. 스플라인 보간법 (Spline Interpolation)
[ Python scipy 모듈을 이용한 결측값 보간 (Interpolation using Python scipy module) ]
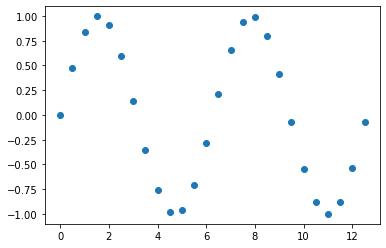
먼저 '0.5'로 동일한 간격을 가지는 x 값들에 대한 사인 함수 (sine function) 의 y값을 계산해서 예제 데이터로 사용하겠습니다. 아래 예졔의 점과 점 사이의 값들이 비어있는 결측값이라고 간주하고, 이들 값을 채워보겠습니다.
import numpy as np
from scipy import interpolate
import matplotlib.pyplot as plt
## generating the original data with missing values
x = np.arange(0, 4*np.pi, 0.5)
y = np.sin(x)
plt.plot(x, y, "o")
plt.show()
original data with missing values
1. 이전 값/ 다음 값을 이용하여 결측값 채우기 (Imputation using the previous/next values)
데이터 포인트 사이의 값을 채우는 가장 간단한 방법은 이전 값(previous value) 나 또는 다음 값(next value)을 이용하는 것입니다. 함수를 추정하는 절차가 필요없으므로 연산 상 부담이 적지만, 데이터 추정 오차는 단점이 될 수 있습니다.
## Interpolation using the previous value
f_prev = interpolate.interp1d(
x, y, kind='previous') # next
y_new_prev = f_prev(xnew)
plt.plot(x, y, "o", xnew, y_new_prev, '-')
plt.show()
interpolation using the previous value
2. Piecewise Constant Interpolation
위 1번의 이전 값 또는 다음 값을 이용한 사이값 채우기를 합쳐놓은 방법입니다. Piecewise Constant Interpolation은 특정 데이터 포인트를 기준으로 가장 가까운 값 (nearest value) 을 가져다가 사이값을 보간합니다. ("최근접 이웃 보간"이라고도 함)
간단한 문제에서는 아래 3번에서 소개하는 Linear Interpolation 이 주로 사용되고, Piecewise Constant Interpolation 은 잘 사용되지 않는 편입니다. 하지만 다차원의 다변량 보간 (in higher-dimensional multivariate interpolation)의 경우, 속도와 단순성(speed and simplicity) 측면에서 선호하는 선택이 될 수 있습니다.
## Piecewise Constant Interpolation
f_nearest = interpolate.interp1d(
x, y, kind='nearest')
y_new_nearest = f_nearest(xnew)
plt.plot(x, y, "o", xnew, y_new_nearest)
plt.show()
Piecewise constant interpolation
3. Linear Interpolation
선형 보간법은 가장 쉬운 보간법 중의 하나로서, 연산이 빠르고 쉽습니다. 하지만 추정값이 정확한 편은 아니며, 데이터 포인트 Xk 에서 미분 가능하지 않다는 단점도 있습니다.
일반적으로, 선형 보간법은 두 개의 데이터 포인트, 가령 (Xa, Ya)와 (Xb, Yb), 를 사용해서 다음의 공식으로 두 값 사이의 값을 보간합니다.
Y = Ya + (Yb - Ya) * (X - Xa) / (Xb- Xa) at the point (x, y)
## Linear Interpolation
f_linear = interpolate.interp1d(
x, y, kind='linear')
y_new_linear = f_linear(xnew)
plt.plot(x, y, "o", xnew, y_new_linear, '-')
plt.show()
Linear interpolation
4. Spline Interpolation
다항식 보간법(Polynomial Interpolation)은 선형 보간법을 일반화(generalization of linear interpolation)한 것입니다. 선형 보간법에서는 선형 함수를 사용했다면, 다항식 보간법에서는 더 높은 차수의 다항식 함수를 사용해서 보간하는 것으로 대체한 것입니다.
일반적으로, 만약 우리가 n개의 데이터 포인트를 가지고 있다면 모든 데이터 포인트를 통과하는 n-1 차수의 다차항 함수가 존재합니다. 보간 오차는 데이터 포인트 간의 거리의 n 차승에 비례(interpolation error is proportional to the distance between the data points to the power n)하며, 다차항 함수는 미분가능합니다. 따라서 선형 보간법의 대부분의 문제를 다항식 보간법은 극복합니다. 하지만 다항식 보간법은 선형 보간법에 비해 복잡하고 연산에 많은 비용이 소요됩니다. 그리고 끝 점(end point) 에서는 진동하면서 변동성이 큰 값을 추정하는 문제가 있습니다.
스플라인 보간법은 각 데이터 포인트 구간별로 낮은 수준의 다항식 보간을 사용 (Spline interpolation uses low-degree polynomials in each of the intervals) 합니다. 그리고 이들이 함께 부드럽게 연결되어서 적합될 수 있도록 다항식 항목을 선택(, and chooses the polynomial pieces such that they fit smoothly together)합니다. 이렇게 적합된 함수를 스플라인(Spline) 이라고 합니다.
스플라인 보간법(Spline Interpolation)은 다항식 보간법의 장점은 살리고 단점은 피해간 보간법입니다. 스플라인 보간법은 다항식 보간법처럼 선형 보간법보다 보간 오차가 더 작은 반면에, 고차항의 다항식 보간법보다는 보간 함수가 부드럽고 평가하기가 쉽습니다.
## Spline Interpolation
f_quadr = interpolate.interp1d(
x, y, kind='quadratic') # cubic
y_new_quadr = f_quadr(xnew)
plt.plot(x, y, "o", xnew, y_new_quadr)
plt.show()
Python pandas의 DataFrame은 특이하고 재미있게도 두 개 이상의 MultiIndex Column 을 가지는 DataFrame 도 지원합니다. R의 DataFrame 이나 DB의 Table 에서는 칼럼이라고 하면 당연히 1개 layer의 칼럼들만을 지원하기에, Python pandas의 2개 이상 layer의 칼럼들을 가진 DataFrame 이 처음에는 생소하고 재미있게 보였습니다.
이번 포스팅에서는 Python pandas DataFrame 중에서 두 개의 MultiIndex Column 을 가지는 DataFrame 에 대해서, 이중 한개 layer의 칼럼을 기준으로 Stacking을 해서 wide-format 을 long-format으로 DataFrame을 재구조화 해보겠습니다.
reshaping pandas DataFrame with MultiIndex Column by Stacking
(1) csv 파일을 읽어와서 MultiIndex Column을 가진 pandas DataFrame 으로 만들기
(2) MultiIndex Column 의 Level에 이름 부여하기
(3) MultiIndex Column DataFrame의 특정 Level을 Stacking 해서 Long-format 으로 재구조화 하기
(4) 재구조화한 DataFrame의 Index 를 칼럼으로 재설정하고 정렬하기
위의 순서대로 간단한 샘플 데이터를 가지고 예를 들어보겠습니다.
(1) csv 파일을 읽어와서 MultiIndex Column을 가진 pandas DataFrame 으로 만들기
아래에 첨부한 dataset.csv 파일을 pandas 의 read_csv() 메소드로 csv 파일을 읽어와서 DataFrame으로 만들 때 header=[0, 1] 옵션을 지정해줌으로써 ==> 첫번째와 두번째 행을 MultiIndex Column 으로 해서 DataFrame을 만들 수 있습니다.
(3) MultiIndex Column DataFrame의 특정 Level을 Stacking 해서 Long-format 으로 재구조화 하기
위의 (2)번에서 MultiIndex Column의 첫번째 Level 에 'grp_nm' 이라는 이름을 부여했는데요, 이번에는 'grp_nm' 이름의 Level 을 기준으로 stack() 메소드를 사용해서 wide-format 을 long-format 의 DataFrame으로 재구조화(reshaping) 해보겠습니다.
이렇게 stacking을 해서 재구조화하면 MultiIndex Column DataFrame 이 (우리가 익숙하게 사용하는) SingleIndex Column의 DataFrame으로 바뀌게 되며, ==> 이제 'grp_nm'은 Index 로 들어가 있습니다.
마지막으로, MultiIndex Column 의 첫번째 Level 을 Stacking 하고 난 후 Index로 사용된 'grp_nm' 을 reset_index() 메소드를 사용해서 칼럼으로 재설정하고, ==> 가시성을 높일 수 있도록 sort_values(by=['grp_nm'])을 사용해서 'grp_nm' 칼럼을 기준으로 오름차순 정렬을 해보겠습니다.
그럼, 실제로 다양한 지수평활법으로 위의 약 판매량 시계열 데이터에 대한 예측 모델을 만들어 예측을 해보고, 다양한 평가지표로 모델 간 비교를 해봐서 가장 우수한 모델이 무엇인지, 과연 앞서 말한 "Multiplicative Winters' method with Linear Trend" 모델이 가장 우수할 것인지 확인해보겠습니다. 보는게 믿는거 아니겠습니까!
이제 월 단위로 시간 순서대로 정렬된 시계열 데이터를 제일 뒤 (최근)의 12개월치는 시계열 예측 모델의 성능을 평가할 때 사용할 test set으로 따로 떼어놓고, 나머지 데이터는 시계열 예측모형 훈련에 사용할 training set 으로 분할 (splitting between the training and the test set)을 해보겠습니다.
## split between the training and the test data sets.
## The last 12 periods form the test data
df_train = df.iloc[:-12]
df_test = df.iloc[-12:]
(1) 지수평활법 기법으로 시계열 예측모형 적합하기 (training the exponential smoothing models in Python)
Python의 statsmodels 라이브러리는 시계열 데이터 분석을 위한 API를 제공합니다. 아래의 코드는 순서대로
statsmodels.tsa.api 메소드를 사용해서 적합한 시계열 데이터 예측 모델에 대해서는 model_object.summary() 메소드를 사용해서 적합 결과를 조회할 수 있습니다. 그리고 model_object.params['parameter_name'] 의 방식으로 지수평활법 시계열 적합 모델의 속성값(attributes of the fitted exponential smoothing results)에 대해서 조회할 수 있습니다.
## accessing the results of SimpleExpSmoothing Model
print(fit1.summary())
# SimpleExpSmoothing Model Results
# ==============================================================================
# Dep. Variable: value No. Observations: 192
# Model: SimpleExpSmoothing SSE 692.196
# Optimized: True AIC 250.216
# Trend: None BIC 256.731
# Seasonal: None AICC 250.430
# Seasonal Periods: None Date: Thu, 29 Jul 2021
# Box-Cox: False Time: 19:26:46
# Box-Cox Coeff.: None
# ==============================================================================
# coeff code optimized
# ------------------------------------------------------------------------------
# smoothing_level 0.3062819 alpha True
# initial_level 3.4872869 l.0 True
# ------------------------------------------------------------------------------
## getting all results by models
params = ['smoothing_level', 'smoothing_trend', 'damping_trend', 'initial_level', 'initial_trend']
results=pd.DataFrame(index=[r"$\alpha$",r"$\beta$",r"$\phi$",r"$l_0$","$b_0$","SSE"],
columns=['SES', "Holt's","Exponential", "Additive", "Multiplicative"])
results["SES"] = [fit1.params[p] for p in params] + [fit1.sse]
results["Holt's"] = [fit2.params[p] for p in params] + [fit2.sse]
results["Exponential"] = [fit3.params[p] for p in params] + [fit3.sse]
results["Additive"] = [fit4.params[p] for p in params] + [fit4.sse]
results["Multiplicative"] = [fit5.params[p] for p in params] + [fit5.sse]
results
# [Out]
# SES Holt's Exponential Additive Multiplicative
# 𝛼 0.306282 0.053290 1.655513e-08 0.064947 0.040053
# 𝛽 NaN 0.053290 1.187778e-08 0.064947 0.040053
# 𝜙 NaN NaN NaN 0.995000 0.995000
# 𝑙0 3.487287 3.279317 3.681273e+00 3.234974 3.382898
# 𝑏0 NaN 0.045952 1.009056e+00 0.052515 1.016242
# SSE 692.195826 631.551871 5.823167e+02 641.058197 621.344891
계절성(seasonality)을 포함한 지수평활법에 대해서는 statsmodels.tsa.holtwinters 내의 메소드를 사용해서 시계열 예측 모델을 적합해보겠습니다.
seasonal_periods 에는 계절 주기를 입력해주는데요, 이번 예제에서는 월 단위 집계 데이터에서 1년 단위로 계절성이 나타나고 있으므로 seasonal_periods = 12 를 입력해주었습니다.
trend = 'add' 로 일단 고정을 했으며, 대신에 계절성의 경우 (f) seasonal = 'add' (or 'additive'), (g) seasonal = 'mul' (or 'multiplicative') 로 구분해서 모델을 각각 적합해보았습니다.
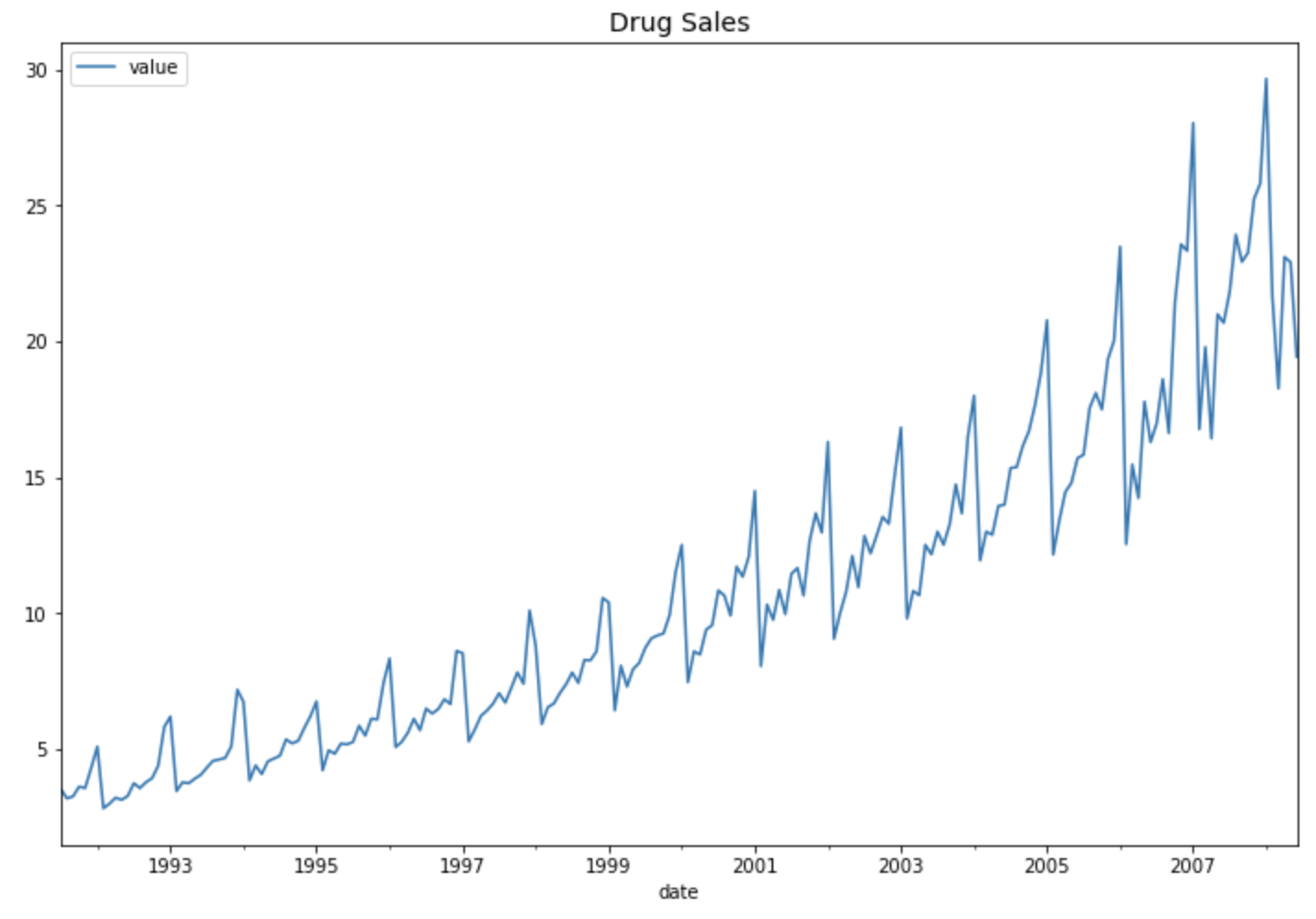
위의 시계열 시도표를 보면 시간이 흐름에 따라 분산이 점점 커지고 있으므로 seasonal = 'mul' (or 'multiplicative') 가 더 적합할 것이라고 우리는 예상할 수 있습니다. 실제 그런지 데이터로 확인해보겠습니다.
## Holt's Winters's method for time series data with Seasonality
from statsmodels.tsa.holtwinters import ExponentialSmoothing as HWES
# additive model for fixed seasonal variation
fit6 = HWES(df_train,
seasonal_periods=12,
trend='add',
seasonal='add').fit(optimized=True, use_brute=True)
# multiplicative model for increasing seasonal variation
fit7 = HWES(df_train,
seasonal_periods=12,
trend='add',
seasonal='mul').fit(optimized=True, use_brute=True)
(2) 지수평활법 적합 모델로 예측하여 모델 간 성능 평가/비교하고 최적 모델 선택하기
(forecasting using the exponential smoothing models, model evaluation/ model comparison and best model selection)
(2-1) 향후 12개월 약 판매량 예측하기 (forecasting the drug sales for the next 12 months)
forecast() 함수를 사용하며, 괄호 안에는 예측하고자 하는 기간을 정수로 입력해줍니다.
Python의 scikit-learn 라이브러리의 metrics 메소드에 이미 정의되어 있는 MSE, MAE 지표는 가져다가 쓰구요, 없는 지표는 모델 적합도 (goodness-of-fit of time series model)를 평가하는 지표 (https://rfriend.tistory.com/667) 포스팅에서 소개했던 수식대로 Python 사용자 정의 함수(User Defined Funtion)을 만들어서 사용하겠습니다.
아래의 모델 성능 평가 지표 중에서 AIC, SBC, APC, Adjsted-R2 지표는 모델 적합에 사용된 모수의 개수 (the number of parameters) 를 알아야지 계산할 수 있으며, 모수의 개수는 지수평활법 모델 종류별로 다르므로, 적합된 모델 객체로부터 모수 개수를 세는 사용자 정의함수를 먼저 정의해보겠습니다.
## UDF for counting the number of parameters in model
def num_params(model):
n_params = 0
for p in list(model.params.values()):
if isinstance(p, np.ndarray):
n_params += len(p)
#print(p)
elif p in [np.nan, False, None]:
pass
elif np.isnan(float(p)):
pass
else:
n_params += 1
#print(p)
return n_params
num_params(fit1)
[Out] 2
num_params(fit7)
[Out] 17
이제 각 지표별로 Python을 사용해서 지수평활법 모델별로 성능을 평가하는 사용자 정의함수를 정의해보겠습니다. MSE와 MAE는 scikit-learn.metrics 에 있는 메소드를 가져다가 사용하며, 나머지는 공식에 맞추어서 정의해주었습니다.
(혹시 sklearn 라이브러리에 모델 성능 평가 지표 추가로 더 있으면 그거 가져다 사용하시면 됩니다. 저는 sklearn 튜토리얼 찾아보고 없는거 같아서 아래처럼 정의해봤어요. 혹시 코드 잘못된거 있으면 댓글에 남겨주시면 감사하겠습니다.)
## number of observations in training set
T = df_train.shape[0]
print(T)
[Out] 192
## evaluation metrics
from sklearn.metrics import mean_squared_error as MSE
from sklearn.metrics import mean_absolute_error as MAE
# Mean Absolute Percentage Error
def SSE(y_test, y_pred):
y_test, y_pred = np.array(y_test), np.array(y_pred)
return np.sum((y_test - y_pred)**2)
def ME(y_test, y_pred):
y_test, y_pred = np.array(y_test), np.array(y_pred)
return np.mean(y_test - y_pred)
def RMSE(y_test, y_pred):
y_test, y_pred = np.array(y_test), np.array(y_pred)
return np.sqrt(np.mean((y_test - y_pred)**2))
#return np.sqrt(MSE(y_test - y_pred))
def MPE(y_test, y_pred):
y_test, y_pred = np.array(y_test), np.array(y_pred)
return np.mean((y_test - y_pred) / y_test) * 100
def MAPE(y_test, y_pred):
y_test, y_pred = np.array(y_test), np.array(y_pred)
return np.mean(np.abs((y_test - y_pred) / y_test)) * 100
def AIC(y_test, y_pred, T, model):
y_test, y_pred = np.array(y_test), np.array(y_pred)
sse = np.sum((y_test - y_pred)**2)
#T = len(y_train) # number of observations
k = num_params(model) # number of parameters
return T * np.log(sse/T) + 2*k
def SBC(y_test, y_pred, T, model):
y_test, y_pred = np.array(y_test), np.array(y_pred)
sse = np.sum((y_test - y_pred)**2)
#T = len(y_train) # number of observations
k = num_params(model) # number of parameters
return T * np.log(sse/T) + k * np.log(T)
def APC(y_test, y_pred, T, model):
y_test, y_pred = np.array(y_test), np.array(y_pred)
sse = np.sum((y_test - y_pred)**2)
#T = len(y_train) # number of observations
k = num_params(model) # number of parameters
return ((T+k)/(T-k)) * sse / T
def ADJ_R2(y_test, y_pred, T, model):
y_test, y_pred = np.array(y_test), np.array(y_pred)
sst = np.sum((y_test - np.mean(y_test))**2)
sse = np.sum((y_test - y_pred)**2)
#T = len(y_train) # number of observations
k = num_params(model) # number of parameters
r2 = 1 - sse/sst
return 1 - ((T - 1)/(T - k)) * (1 - r2)
## Combining all metrics together
def eval_all(y_test, y_pred, T, model):
sse = SSE(y_test, y_pred)
mse = MSE(y_test, y_pred)
rmse = RMSE(y_test, y_pred)
me = ME(y_test, y_pred)
mae = MAE(y_test, y_pred)
mpe = MPE(y_test, y_pred)
mape = MAPE(y_test, y_pred)
aic = AIC(y_test, y_pred, T, model)
sbc = SBC(y_test, y_pred, T, model)
apc = APC(y_test, y_pred, T, model)
adj_r2 = ADJ_R2(y_test, y_pred, T, model)
return [sse, mse, rmse, me, mae, mpe, mape, aic, sbc, apc, adj_r2]
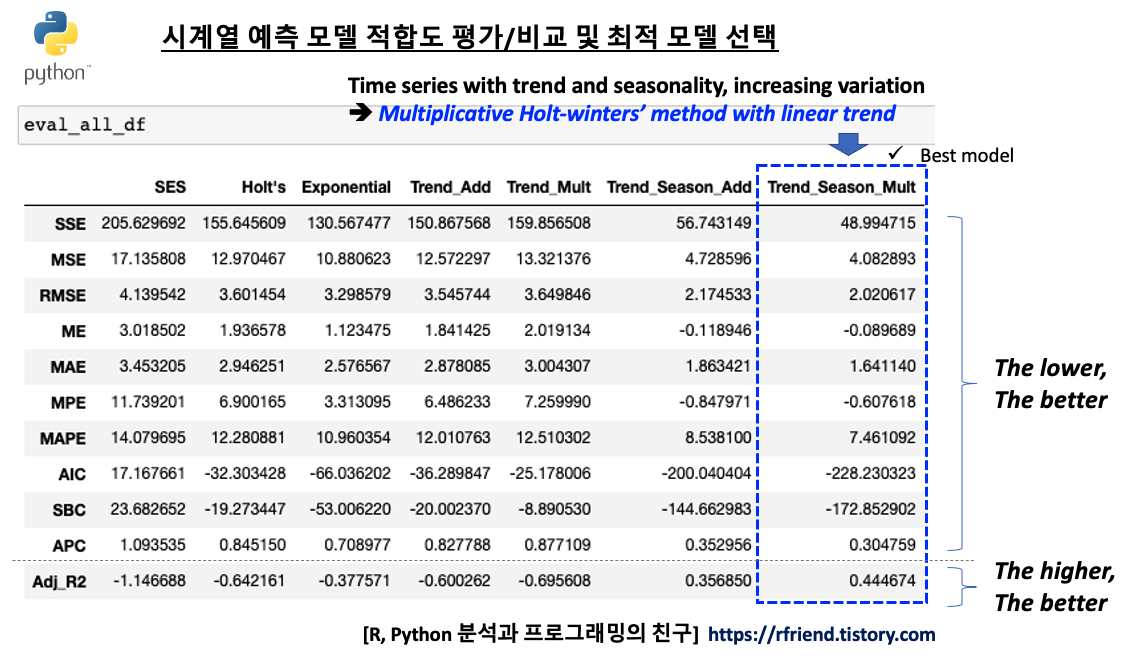
위에서 정의한 시계열 예측 모델 성능평가 지표 사용자 정의 함수를 모델 성능 평가를 위해 따로 떼어놓았던 'test set' 에 적용하여 각 지수평활법 모델별/ 모델 성능평가 지표 별로 비교를 해보겠습니다.
모델 성능평가 지표 중에서 실제값과 예측값의 차이인 잔차(residual)를 기반으로 한 MSE, RMSE, ME, MAE, MPE, MAPE, AIC, SBC, APC 는 낮을 수록 상대적으로 더 좋은 모델이라고 평가할 수 있으며, 실제값과 평균값의 차이 중에서 시계열 예측 모델이 설명할 수 있는 부분의 비중 (모델의 설명력) 을 나타내는 Adjusted-R2 는 값이 높을 수록 상대적으로 더 좋은 모델이라고 평가합니다. (Ajd.-R2 가 음수가 나온 값이 몇 개 보이는데요, 이는 예측 모델이 불량이어서 예측값이 실제값과 차이가 큼에 따라 SSE가 SST보다 크게 되었기 때문입니다.)
시계열 모델 성능 지표별로 보면 전반적으로 7번째 지수평활법 시계열 예측 모델인 "Multiplicative Winters' method with Linear Trend" 모델이 상대적으로 가장 우수함을 알 수 있습니다. 역시 시도표를 보고서 우리가 예상했던대로 결과가 나왔습니다.
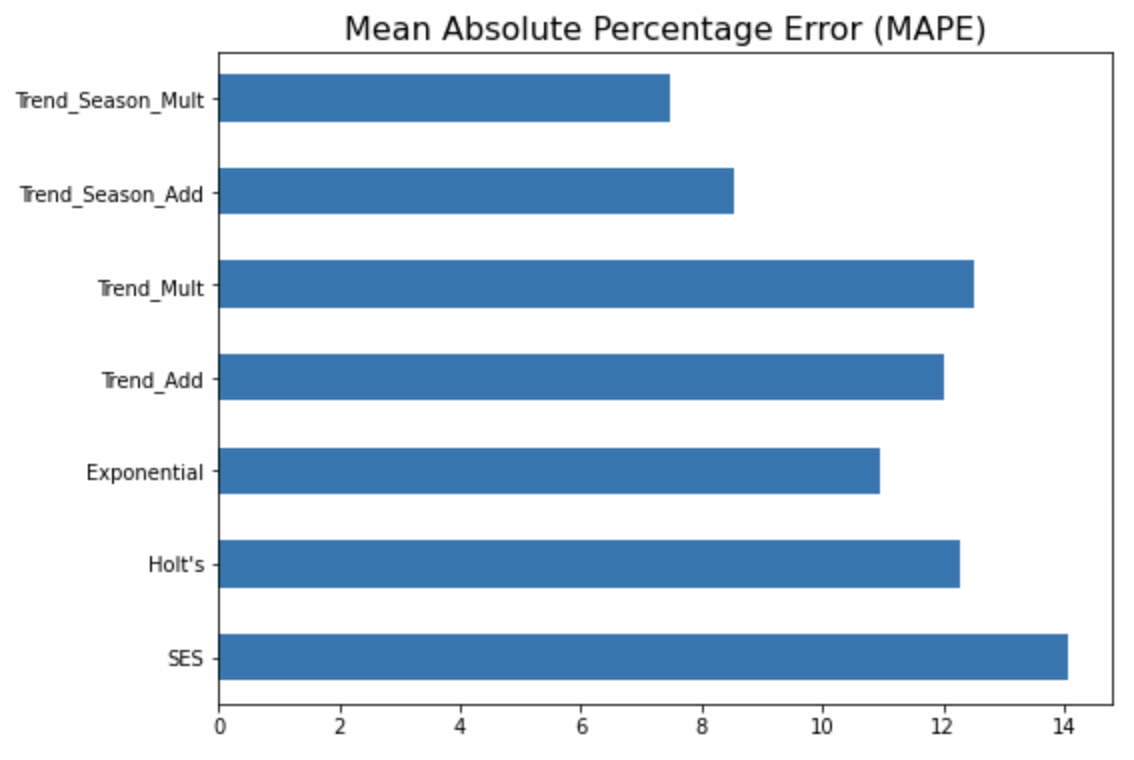
MAPE (Mean Absolute Percentage Error) 지표에 대해서만 옆으로 누운 막대그래프로 모델 간 성능을 비교해서 시각화를 해보면 아래와 같습니다. (MAPE 값이 작을수록 상대적으로 더 우수한 모델로 해석함.)
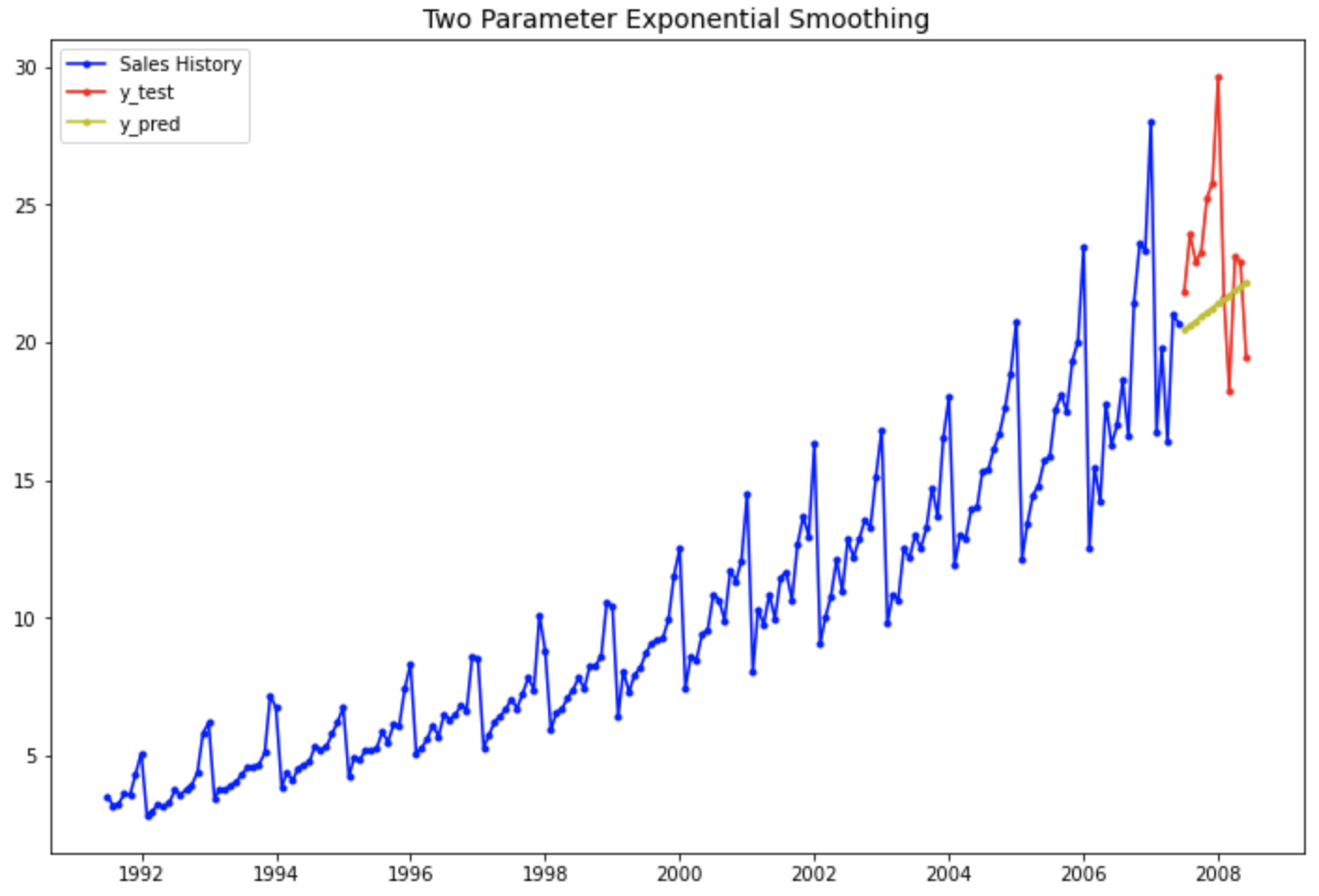
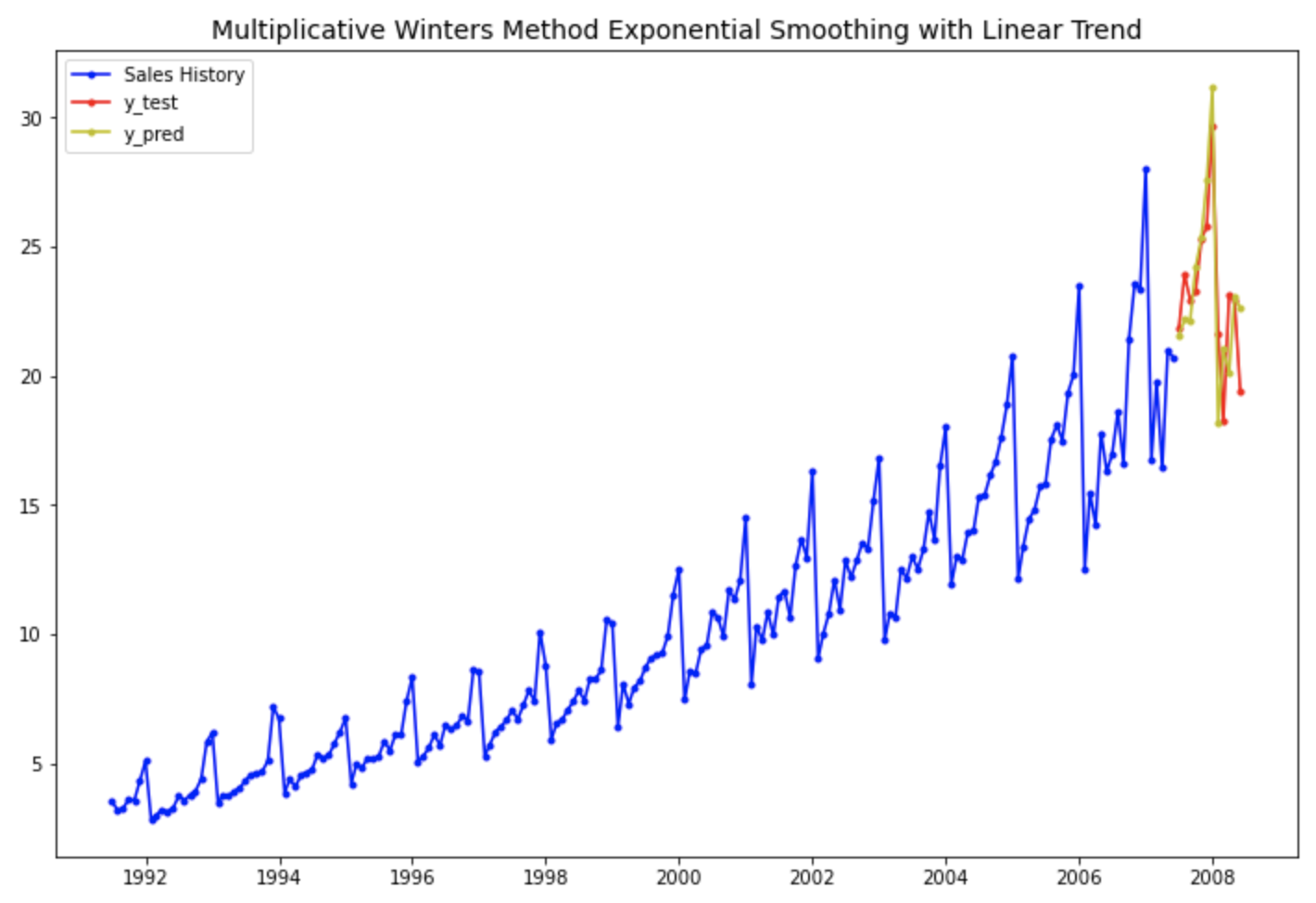
예상했던 대로 4번째의 "1차 선형 추세만 반영하고 계절성은 없는 이중 지수 평활법 모델" 보다는, 7번째의 "선형추세+계절성까지 반영한 multiplicative holt-winters method exponential smoothing with linear trend 지수평활법 모델" 이 더 실제값을 잘 모델링하여 근접하게 예측하고 있음을 눈으로 확인할 수 있습니다.
# 1차 선형 추세는 있고 계절성은 없는 이중 지수 평활법
plt.rcParams['figure.figsize']=[12, 8]
past, = plt.plot(df_train.index, df_train, 'b.-', label='Sales History')
test, = plt.plot(df_test.index, df_test, 'r.-', label='y_test')
pred, = plt.plot(df_test.index, forecast_4, 'y.-', label='y_pred')
plt.title('Two Parameter Exponential Smoothing', fontsize=14)
plt.legend(handles=[past, test, pred])
plt.show()
# 1차 선형 추세와 확산계절변동이 있는 승법 윈터스 지수평활법
plt.rcParams['figure.figsize']=[12, 8]
past, = plt.plot(df_train.index, df_train, 'b.-', label='Sales History')
test, = plt.plot(df_test.index, df_test, 'r.-', label='y_test')
pred, = plt.plot(df_test.index, forecast_7, 'y.-', label='y_pred')
plt.title('Multiplicative Winters Method Exponential Smoothing with Linear Trend', fontsize=14)
plt.legend(handles=[past, test, pred])
plt.show()
적합된 statsmodels.tsa 시계열 예측 모델에 대해 summary() 메소드를 사용해서 적합 결과를 조회할 수 있으며, model.params['param_name'] 으로 적합된 모델의 속성값에 접근할 수 있습니다.
이번 포스팅에서는 시계열 자료 예측 모형의 성능, 모델 적합도 (goodness-of-fit of the time series model) 를 평가할 수 있는 지표, 통계량을 알아보겠습니다.
아래의 모델 적합도 평가 지표들의 리스트를 살펴보시면 선형회귀모형의 모델 적합도 평가 지표와 유사하다는 것을 알 수 있습니다.(실제값과 예측값의 차이 또는 설명비율에 기반한 성능 평가라는 측면에서는 동일하며, 회귀모형은 종속변수와 독립변수간 상관관계에 기반한 반면에 시계열 모형은 종속변수와 자기자신의 과거 데이터와의 자기상관관계에 기반한 다는것이 다른점 입니다.)
아래 평가지표들 중에서 전체 분산 중에서 모델이 설명할 수 있는 비율을 나타내는 수정결정계수는 통계량 값이 높을 수록 좋은 모델이며, 나머지 오차에 기반한 평가 지표(통계량)들은 값이 낮을 수록 상대적으로 더 좋은 모델이라고 평가를 합니다. (단, SST는 제외)
이들 각 지표별로 좋은 모델 여부를 평가하는 절대 기준값(threshold)이 있는 것은 아니며, 여러개의 모델 간 성능을 상대적으로 비교 평가할 때 사용합니다.
- 전체제곱합 (SST, total sum of square)
- 오차제곱합 (SSE, error sum of square)
- 평균오차제곱합 (MSE, mean square error)
- 제곱근 평균오차제곱합 (RMSE, root mean square error)
- 평균오차 (ME, mean error)
- 평균절대오차 (MAE, mean absolute error)
- 평균비율오차 (MPE, mean percentage error)
- 평균절대비율오차 (MAPE, mean absolute percentage error)
- 수정결정계수 (Adj. R-square)
- AIC (Akaike's Information Criterion)
- SBC (Schwarz's Bayesian Criterion)
- APC (Amemiya's Prediction Criterion)
[ 시계열 데이터 예측 모형 적합도 평가 지표 (goodness-of-fit measures for time series prediction models) ]
goodness-of-fit measures for time series models
1. 전체제곱합 (SST, total sum of square)
total sum of square, SST
SST는 시계열 값에서 시계열의 전체 평균 값을 뺀 값으로, 시계열 예측 모델을 사용하지 않았을 때 (모든 모수들이 '0' 일 때) 의 오차 제곱 합입니다. 나중에 결정계수(R2), 수정결정계수(Adj. R2)를 계산할 때 사용됩니다. (SST 는 모델 성능 평가에서는 제외)
2. 오차제곱합 (SSE, error sum of square)
error sum of square, SSE
3. 평균오차제곱합 (MSE, mean square error), 제곱근 평균오차제곱합 (RMSE, root mean square error)
root mean squared error
MSE는 많은 통계 분석 패키지, 라이브러리에서 모델 훈련 시 비용함수(cost function) 또는 모델 성능 평가시 기본 설정 통계량으로 많이 사용합니다.
RMSE (Root Mean Square Error) 는 MSE에 제곱근을 취해준 값으로서, SSE를 제곱해서 구한 MSE에 역으로 제곱근을 취해주어 척도를 원래 값의 단위로 맞추어 준 값입니다.
4. 평균오차 (ME, mean error)
mean error
ME(Mean Error) 는 MAE(Mean Absolute Error)와 함께 해석하는 것이 필요합니다. 왜냐하면 큰 오차 값들이 존재한다고 하더라도 ME 값만 볼 경우 + 와 - 값이 서로 상쇄되어 매우 작은 값이 나올 수도 있기 때문입니다. 따라서 MAE 값을 통해 실제값과 예측값 간에 오차가 평균적으로 얼마나 큰지를 확인하고, ME 값의 부호를 통해 평균적으로 과다예측(부호가 '+'인 경우) 혹은 과소예측(부호가 '-'인 경우) 인지를 가늠해 볼 수 있습니다.
5. 평균절대오차 (MAE, mean absolute error)
mean absolute error
6. 평균비율오차 (MPE, mean percentage error)
mean percentage error
위의 ME와 MAE 는 척도 문제 (scale problem) 을 가지고 있습니다. 반면에 MPE (Mean Percentage Error)와 MAPE (Mean Absolute Percentage Error) 는 0~100%로 표준화를 해주어서 척도 문제가 없다는 특징, 장점이 있습니다. 역시 MAE 와 MAPE 값을 함께 확인해서 해석하는 것이 필요합니다. 0에 근접할 수록 시계열 예측모델이 잘 적합되었다고 평가할 수 있으며, MAE의 부호(+, -)로 과대 혹은 과소예측의 방향을 파악할 수 있습니다.
7. 평균절대비율오차 (MAPE, mean absolute percentage error)
mean absolute percentage error
8. 수정결정계수 (Adj. R-square)
adjusted R2
결정계수 R2 는 SST 에서 예측 모델이 설명하는 부분의 비율(R2 = SSR/SST=1-SSE/SST)을 의미합니다. 그런데 결정계수 R2는 모수의 개수가 증가할 수록 이에 비례하여 증가하는 경향이 있습니다. 이러한 문제점을 바로잡기 위해 예측에 기여하지 못하는 모수가 포함될 경우 패널티를 부여해서 결정계수의 값을 낮추어주게 수정한 것이 바로 수정결정계수(Adjusted R2) 입니다. (위의 식에서 k 는 모델에 포함된 모수의 개수를 의미합니다.)
위의 2~7번의 통계량들은 SSE(Error Sum of Square)를 기반으로 하다보니 값이 작을 수록 좋은 모델을 의미하였다면, 8번의 수정결정계수(Adj. R2)는 예측모델이 설명력과 관련된 지표로서 값이 클 수록 더 좋은 모델을 의미합니다.(1에 가까울 수록 우수)
9. AIC, SBC, APC
AIC (Akaike's Information Criterion),
SBC (Schwarz's Bayesian Criterion),
APC (Amemiya's Prediction Criterion)
AIC, SBC, APC
위의 AIC, SBC, APC 지표들도 SSE(Error Sum of Square) 에 기반한 지표들로서, 값이 작을 수록 더 잘 적합된 모델을 의미합니다. 이들 지표 역시 SSE 를 기본으로 해서 여기에 모델에서 사용한 모수의 개수(k, 패널티로 사용됨), 관측치의 개수(T, 관측치가 많을 수록 리워드로 사용됨)를 추가하여 조금씩 변형을 한 통계량들입니다.
다음번 포스팅에서는 이들 지표를 사용해서 Python으로 하나의 시계열 자료에 대해 여러 개의 지수 평활법 기법들을 적용해서 가장 모형 적합도가 높은 모델을 찾아보겠습니다.(https://rfriend.tistory.com/671)
이번 포스팅에서는 Python 의 matplotlib 라이브러리를 사용해서 사인 곡선, 코사인 곡선을 그려보겠습니다.
(1) matplotlib, numpy 라이브러리를 사용해서 사인 곡선, 코사인 곡선 그리기
(Plotting sine, cosine curve using python matplotlib, numpy)
(2) x축과 y축의 눈금값(xticks, yticks), 범례(legend) 를 설정하기
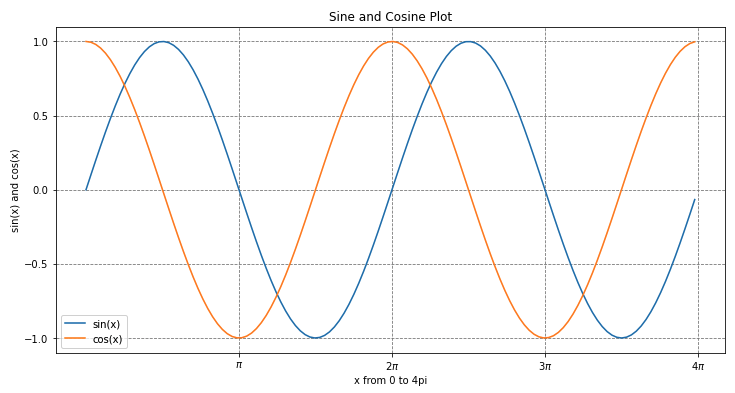
(3) 그래프에 가로, 세로 그리드 선 추가하기 (adding grid lines)
이번 포스팅은 그리 어렵지는 않은데요, 눈금값, 범례, 그리드 선 추가와 같은 소소한 팁들이 필요할 때 참고하라고 정리해 놓습니다.
(1) matplotlib, numpy 라이브러리를 사용해서 사인 곡선, 코사인 곡선 그리기
(Plotting sine, cosine curve using python matplotlib, numpy)
numpy 로 0부터 4 pi 까지 0.1씩 증가하는 배열의 x축 값을 만들고, 이들 값들을 대입하여서 사인 y값, 코사인 z값을 생성하였습니다.
이들 x 값들에 대한 사인 y값, 코사인 z값을 가장 간단하게 matplotlib 으로 시각화하면 아래와 같습니다.
import numpy as np
import matplotlib.pyplot as plt
# using Jupyter Notebook
%matplotlib inline
## generating x from 0 to 4pi and y using numpy library
x = np.arange(0, 4*np.pi, 0.1) # start, stop, step
y = np.sin(x)
z = np.cos(x)
## ploting sine and cosine curve using matplotlb
plt.plot(x, y, x, z)
plt.show()
(2) x축과 y축의 눈금값(xticks, yticks), 범례(legend) 를 설정하기
위의 (1)번 사인 곡선, 코사인 곡선을 보면 그래프 크기가 작고, x축 눈금값과 y축 눈금값이 정수로 되어있으며, x축과 y축의 라벨도 없고, 범례가 없다보니 사인 곡선과 코사인 곡선을 구분하려면 신경을 좀 써야 합니다.