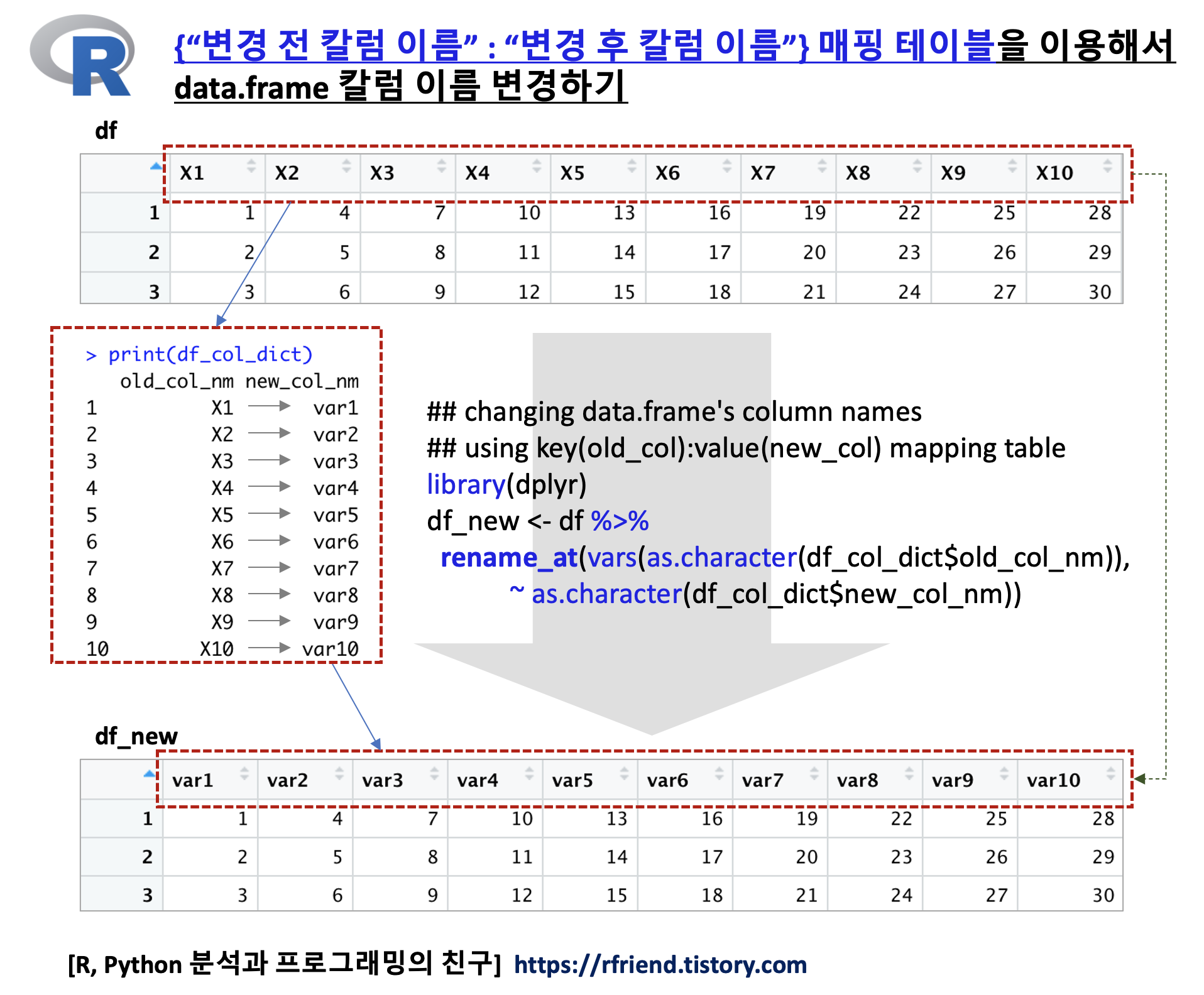
이번 포스팅에서는 R data.frame에서 여러개의 칼럼 이름을 '변경 전 칼럼 이름 : 변경 후 칼럼 이름'의 매핑 테이블 (old_column_name : new_column_name mapping table) 을 이용해서 한꺼번에 변경하는 방법을 소개하겠습니다. data.frame에 칼럼 개수가 엄청 많고, 특정 칼럼에 대해서 선별적으로 칼럼 이름을 변경하고 싶을 때 전:후 칼럼 이름 매핑 테이블을 사용하는 이번 포스팅의 방법을 사용하면 편리합니다.
renaming column names using mapping table in R data.frame
다음으로, '변경 전 칼럼 이름 : 변경 후 칼럼 이름' 매핑 테이블을 만들어보겠습니다. 아래 예제에서는 변경 전 칼럼 이름 "X1"~"X10" 을 --> 변경 후 칼럼 이름 "var1"~"var10" 의 매핑 테이블 data.frame을 만들었습니다. (특정 칼럼만 선별적으로 변경하고 싶으면 해당 칼럼의 "변경 전 : 변경 후 매핑 테이블"을 만들면 됩니다.)
(1) dcast() 함수로 데이터셋 재구조화 시 문자열을 원소의 개수 (length) 로 집계
문자열 대상 집계일 때는 default 설정이 원소의 개수 (length) 이므로 위와 결과는 동일합니다만, 이번에는 경고 메시지가 안떴습니다.
##-- (1) counting the number of values as an aggregation function for string values
dcast(dt, x1 ~ x2,
fun.aggregate = length,
value.var = "x3")
# x1 1 2 3
# 1: g1 1 1 2
# 2: g2 1 2 1
(2) dcast() 함수로 데이터셋 재구조화 시 문자열을 콤마로 구분해서 붙여쓰기
dcast() 로 재구조화 시 하나의 셀 안에 여러개의 원소가 존재하게 될 경우, 이들 문자열 원소들을 콤마로 구분해서 옆으로 나란히 붙여서 집계하는 사용자 정의 함수를 fun.aggregate 매개변수란에 써주었습니다.
##-- (2) concatenation as an aggregation function for string values
dcast(dt, x1 ~ x2,
fun.aggregate = function(x) if (length(x)==1L) x else paste(x, collapse=","),
value.var = "x3")
# x1 1 2 3
# 1: g1 a b c,d
# 2: g2 e f,g h
(3) dcast() 함수로 데이터셋 재구조화 시 첫번째 문자열만 가져오기
dcast() 로 재구조화 시 하나의 셀 안에 여러개의 원소가 존재하게 될 경우, 이들 복수개의 원소들 중에서 첫번째 원소만 가져오는 사용자정의함수를 fun.aggregate 매개변수란에 작성해주었습니다.
##-- (3) keeping the first value as an aggregation function for string values
dcast(dt, x1 ~ x2,
fun.aggregate = function(x) if (length(x)==1L) x else x[1],
value.var = "x3")
# x1 1 2 3
# 1: g1 a b c
# 2: g2 e f h
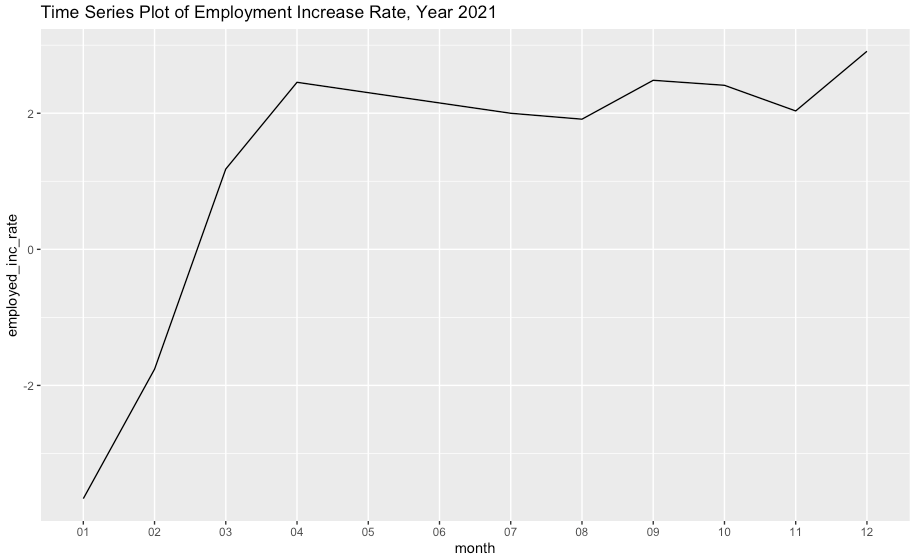
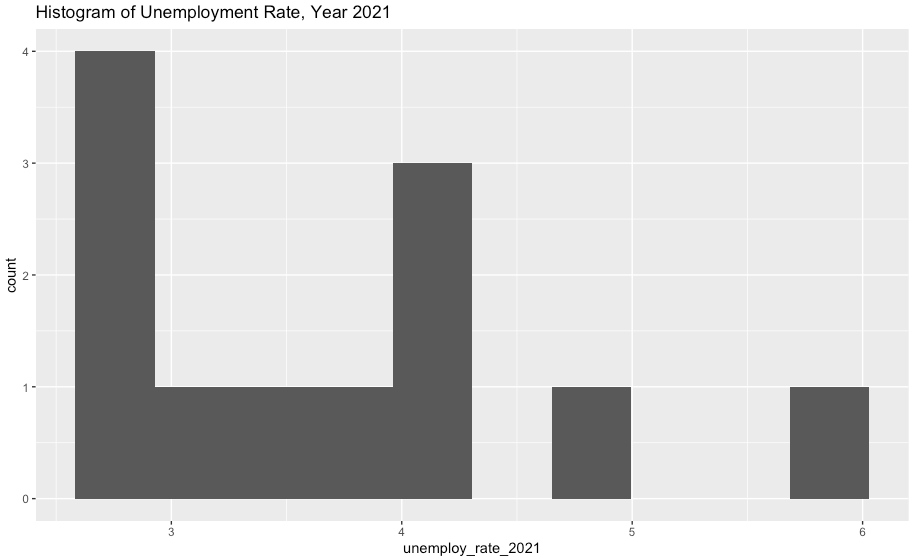
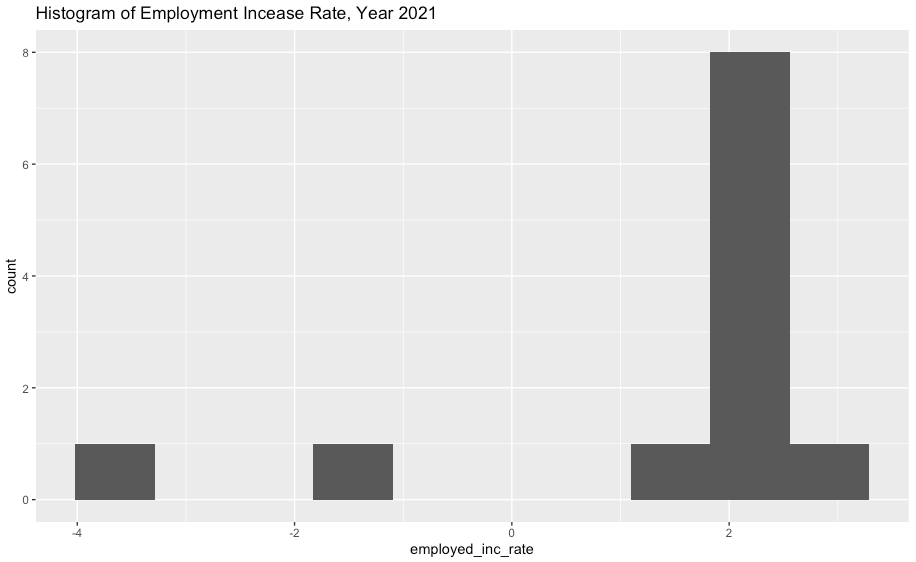
주식을 하는 분들은 아마도 대표적인 시계열 데이터인 주가의 이동평균, 누적평균 그래프에 이미 익숙할 것입니다.
이번 포스팅에서는 R의 zoo 패키지의 rollapply() 라는 window function 의
(1) Rolling Windows 를 사용해서 시계열 데이터의 이동 평균 구하기
(average of time series using rolling windows)
(2) Expanding Windows 를 사용해서 시계열 데이터의 누적 평균 구하기
(average of time series using expanding windows)
방법을 소개하겠습니다.
[ 이동 평균 (average using Rolling Windows) vs. 누적 평균 (average using Expanding Windows) ]
moving average (rolling windows) vs. cumulative average (expanding windows) using R zoo rollapply() function
시계열 데이터를 전처리하고 분석할 때 Window Function 을 자주 사용하는데요,
- Rolling Windows : 특정 window width (예: 10분, 1시간, 1일 등) 를 유지한채 측정 단위시간별로 이동하면서 분석
- Expanding Windows : 처음 시작 시점은 고정한 채, 시간이 흐름에 따라 신규로 포함되는 데이터까지 누적해서 분석
하는 차이가 있습니다. 바로 위에 Rolling Windows 와 Expanding Windows 를 도식화 해놓은 자료를 보면 금방 이해가 될거예요.
만약 시계열 데이터에 추세(trend) 나 계절성 (seasonality) 이 있다면 Rolling Windows 가 적당하며, 시계열 데이터에 추세나 계절성이 없이 안정적(stable) 이다면 Expanding Windows 를 사용해서 더 많은 데이터를 이용해서 요약 통계량을 계산하는게 유리할 수 있겠습니다.
시계열 예측 모델링할 때는 Rolling Windows 를 사용해서 모델 성능을 검증합니다.
R 의 zoo 패키지의 rollapply() 함수를 사용할 것이므로, zoo 패키지를 먼저 설치하고 임포팅합니다.
그리고 예제로 사용할 간단한 시계열 데이터를 만들어보겠습니다. 추세와 노이즈가 있는 시계열 데이터 입니다.
## ------------
## Wimdow functions in Time Series
## (1) Rolling window
## (2) Expanding window
## R zoo's rollapply(): https://www.rdocumentation.org/packages/zoo/versions/1.8-9/topics/rollapply
## ------------
install.packages("zoo")
library(zoo)
## generating a time series with trend and noise
set.seed(1) # for reproducibility
x <- rnorm(n=100, mean=0, sd=10) + 1:100
plot(x, type='l',
main="time series plot with trend and noise")
time series with trend and noise
(1) Rolling Windows 를 사용해서 시계열 데이터의 이동 평균 구하기
(average of time series using rolling windows)
zoo 패키지의 rollapply() 함수에서
- width 매개변수는 'window width' 를 설정할 때 사용합니다.
- FUN 매개변수에는 원하는 함수를 지정해줄 수 있으므로 매우 강력하고 유연하게 사용할 수 있습니다. 아래 예에서는 평균(mean)과 최대값(max) 을 계산하는 함수를 사용해보았습니다.
- align 은 데이터의 기준을 정렬할 때 왼쪽("left"), 중앙("centered", default 설정), 오른쪽("right") 중에서 지정할 수 있습니다. 이때 align="left"로 설정해주면 자칫 잘못하면 미래의 데이터를 가져다가 요약 통계량을 만드는 실수 (lookahead) 를 할 수도 있으므로, 만약 예측 모델링이 목적이라면 lookahead 를 하는건 아닌지 유의해야 합니다.
- partial=TRUE 로 설정하면 양쪽 끝부분에 window width 의 개수에 데이터 포인트 개수가 모자라더라도 있는 데이터만 가지고 부분적으로라도 함수의 통계량을 계산해줍니다.
## (1) Rolling Windows
## (1-1) moving average
f_avg_rolling_win <- rollapply(
data=zoo(x),
width=10, # window width
FUN=function(w) mean(w),
# 'align' specifies whether the index of the result should be left-aligned
# or right-aligned or centered (default)
# compared to the rolling window of observations.
align="right",
# If 'partial=TRUE', then the subset of indexes
# that are in range are passed to FUN.
partial=TRUE)
## (1-2) moving max
f_max_rolling_win <- rollapply(
zoo(x),
10,
function(w) max(w),
align="right",
partial=TRUE)
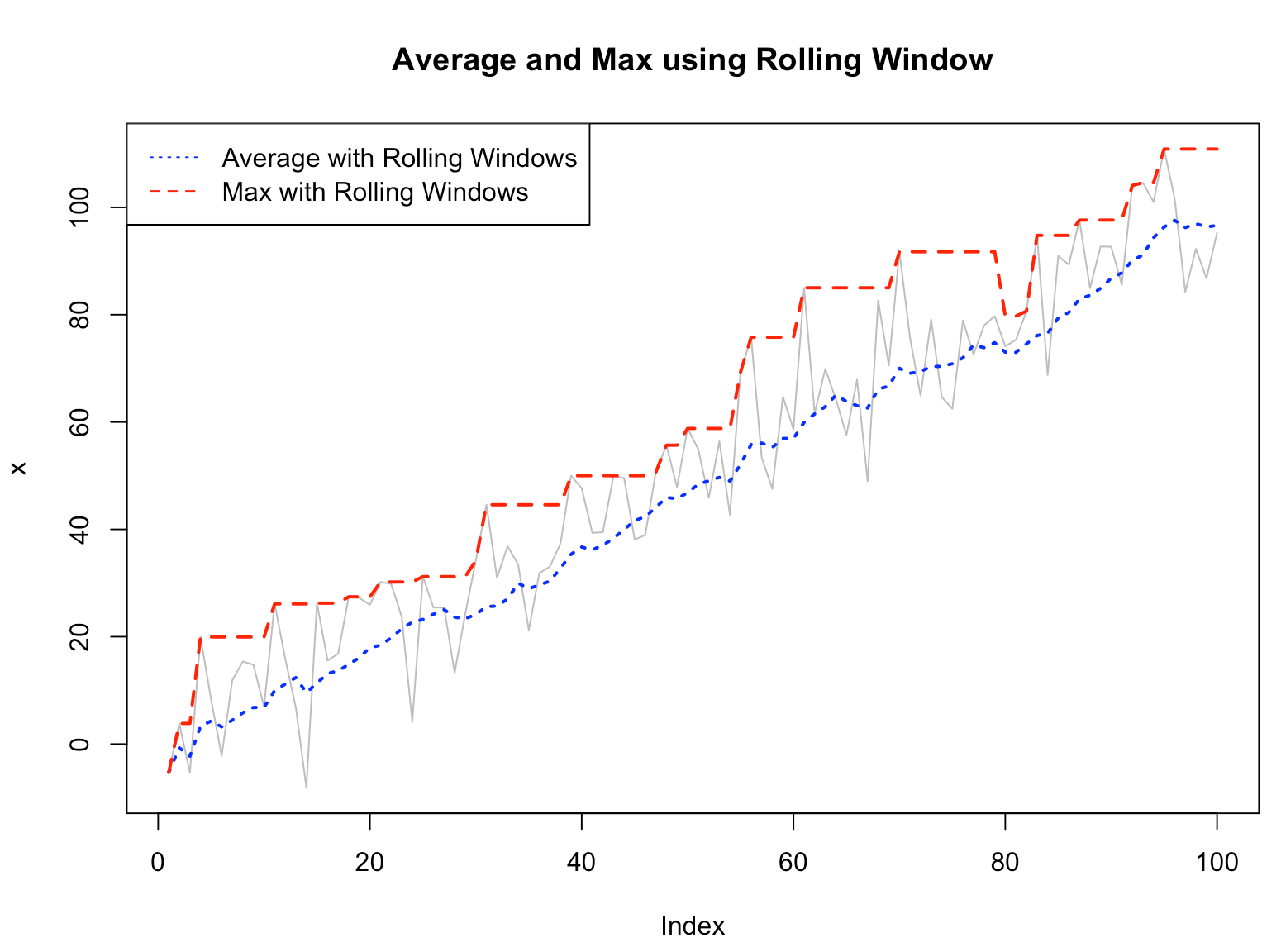
plot(x, col="gray", lwd=1, type="l", main="Average and Max using Rolling Window")
lines(f_avg_rolling_win, col="blue", lwd=2, lty="dotted")
lines(f_max_rolling_win, col="red", lwd=2, lty="dashed")
legend("topleft",
c("Average with Rolling Windows", "Max with Rolling Windows"),
col = c("blue", "red"),
lty = c("dotted", "dashed"))
moving average and max using the rolling windows
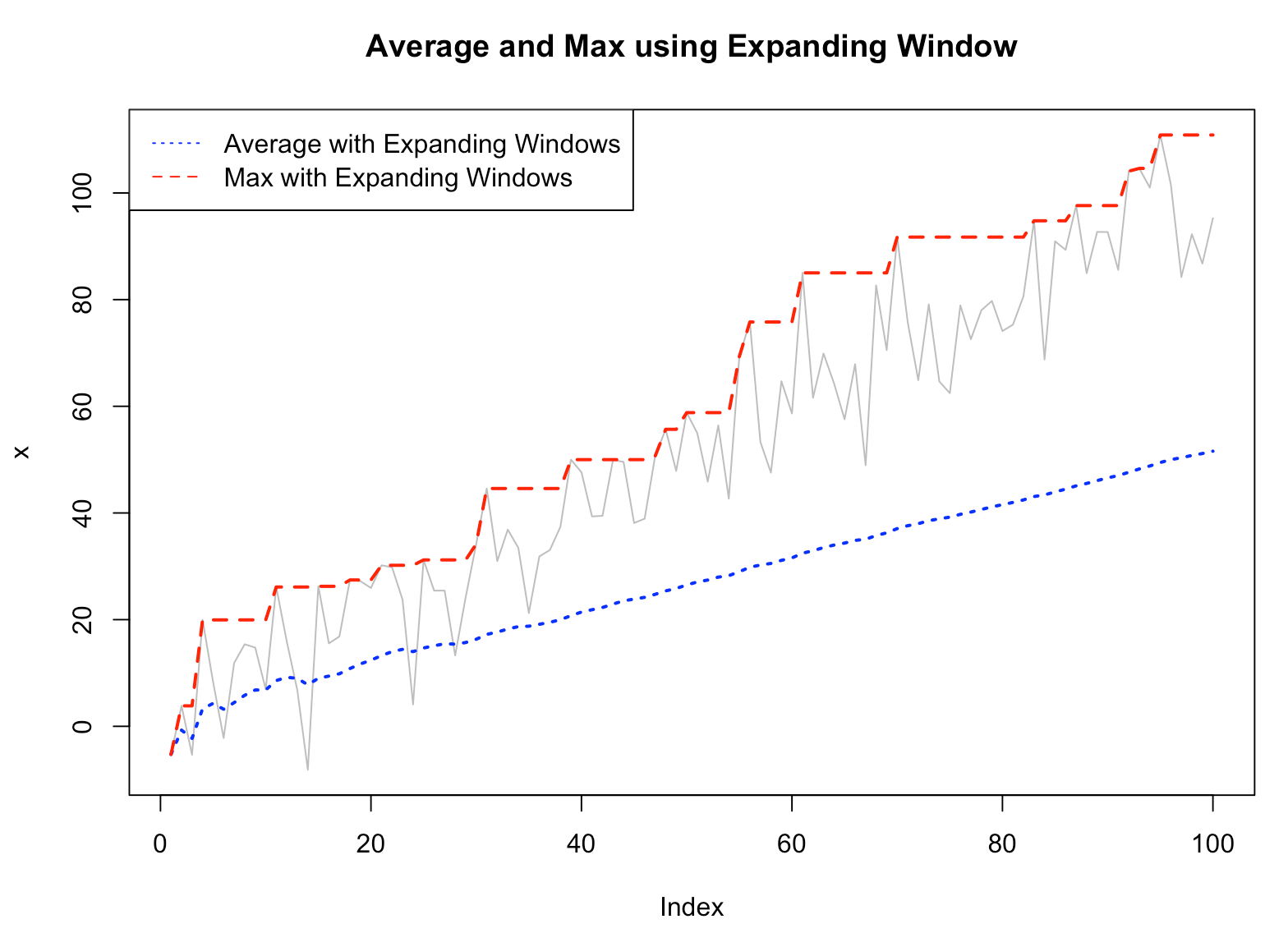
(2) Expanding Windows 를 사용해서 시계열 데이터의 누적 평균 구하기
(average of time series using expanding windows)
R 에서 zoo 패키지의 rollapply() 함수로 Expanding Windwos 를 사용하려면 width = seq_along(x) 를 지정해주면 누적으로 함수를 계산해줍니다.
아래 예에서는 누적으로 평균과 최대값을 계산해서 시각화 한건데요, 우상향 하는 추세가 있는 시계열이다보니 누적으로 평균을 구하면 시계열 초반의 낮은 값들까지 모두 포함이 되어서 누적평균 값이 최근 값들을 제대로 따라가지 못하고 있습니다.
반면, 누적으로 최대값을 계산한 값은 중간에 소폭 값이 줄어들더라도 계산 시점까지 누적으로 최대값을 계산하므로, 항상 우상향하는 누적 최대값을 보여주고 있습니다.
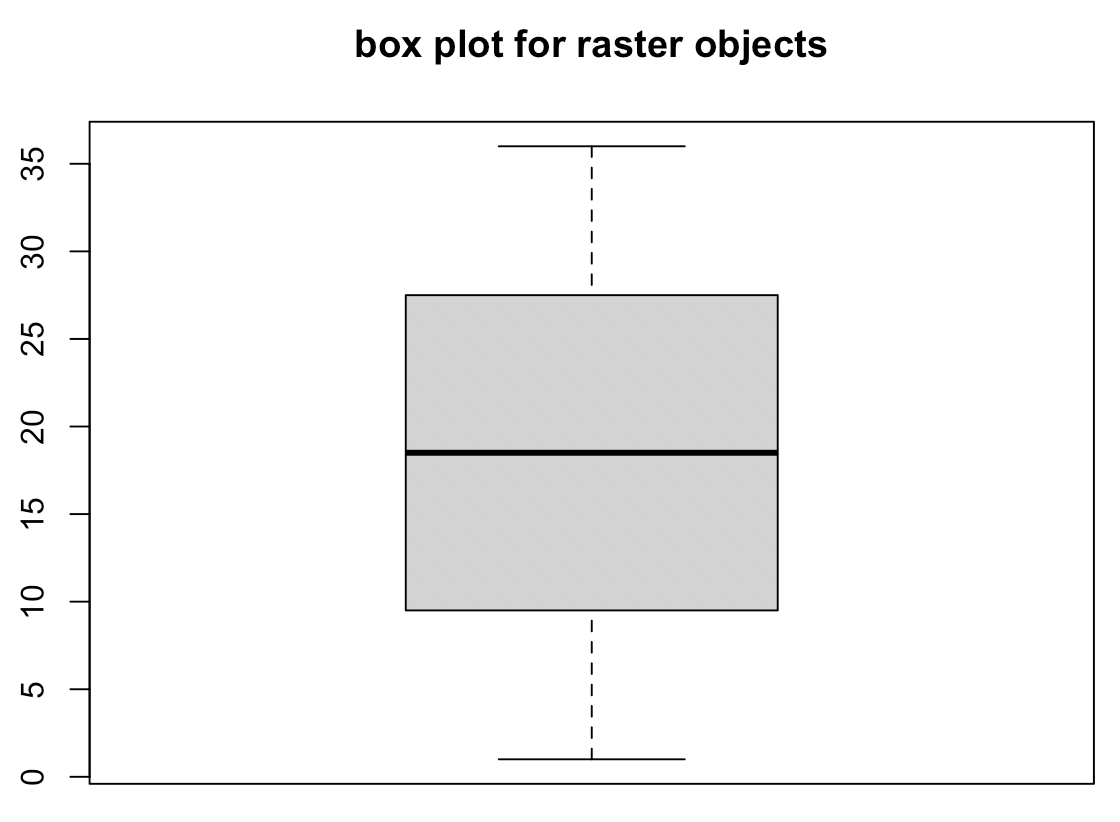
레스터 객체에 대해 summary(raster_obj) 함수를 사용하면 레스터 객체의 픽셀 속성값에 대한 최소값(Minimum value), 1사분위수(1st Quantile), 중위값(Median), 3사분위수(3rd Quantile), 최대값(Maximum value), 결측값 개수(NA's) 에 대한 기술통계량(descriptive statistics)을 확인할 수 있습니다.
## summary() function for raster objects
summary(elev)
# layer
# Min. 1.00
# 1st Qu. 9.75
# Median 18.50
# 3rd Qu. 27.25
# Max. 36.00
# NA's 0.00
레스터 객체의 픽셀 속성값에 대해 cellStats(raster_obj, summary_function) 함수를 사용하여 평균(mean), 분산(variance), 표준편차(standard deviation), 사분위수(quantile), 합계(summation) 를 구할 수 있습니다.
RasterBlack Calss, RasterStack Class와 같이 여러개의 층을 가지는 레스터 클래스 객체 (multi-layered raster classes objects) 에 대해서 앞서 소개한 요약 통계량을 구하는 함수를 적용하면 각 층별로 따로 따로 요약 통계량이 계산됩니다.
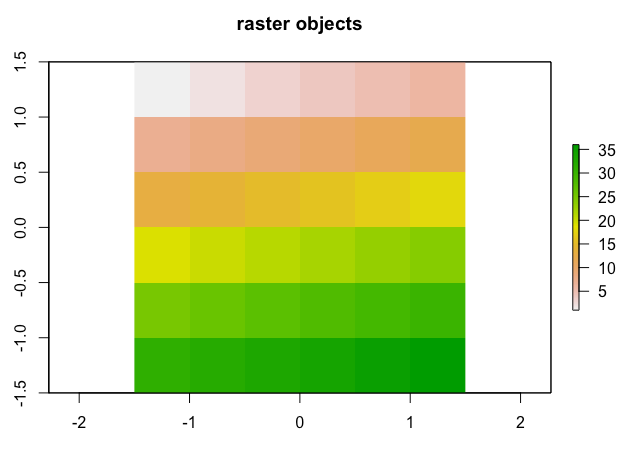
(2) 레스터 객체 시각화 하기 (visualizing raster objects)
## -- visualization of raster objects
## plot()
plot(elev, main = "raster objects")
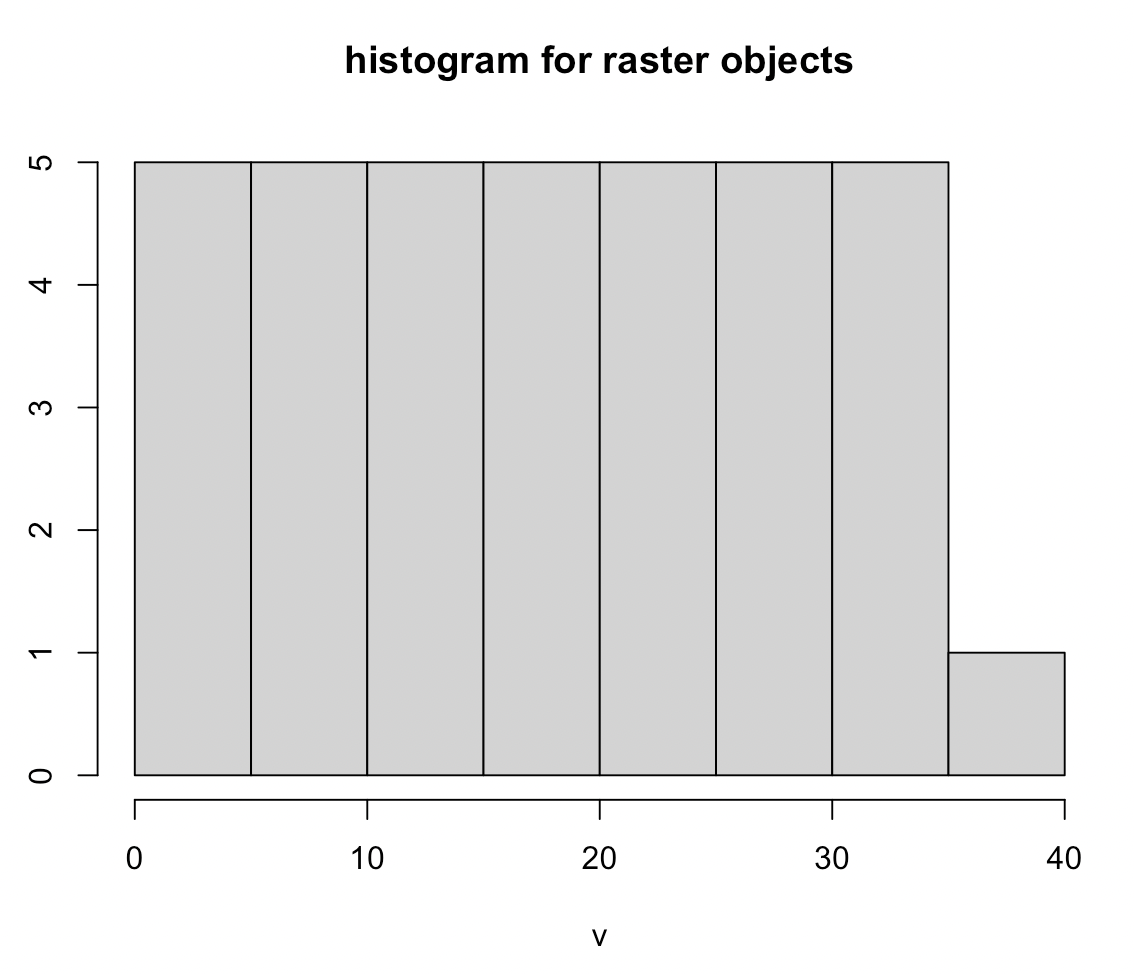
레스터 객체의 픽셀 속성값에 대해 히스토그램(histogram for raster objects)을 그리려면 hist() 함수를 사용하면 됩니다.
## histogram
hist(elev, main = "histogram for raster objects")
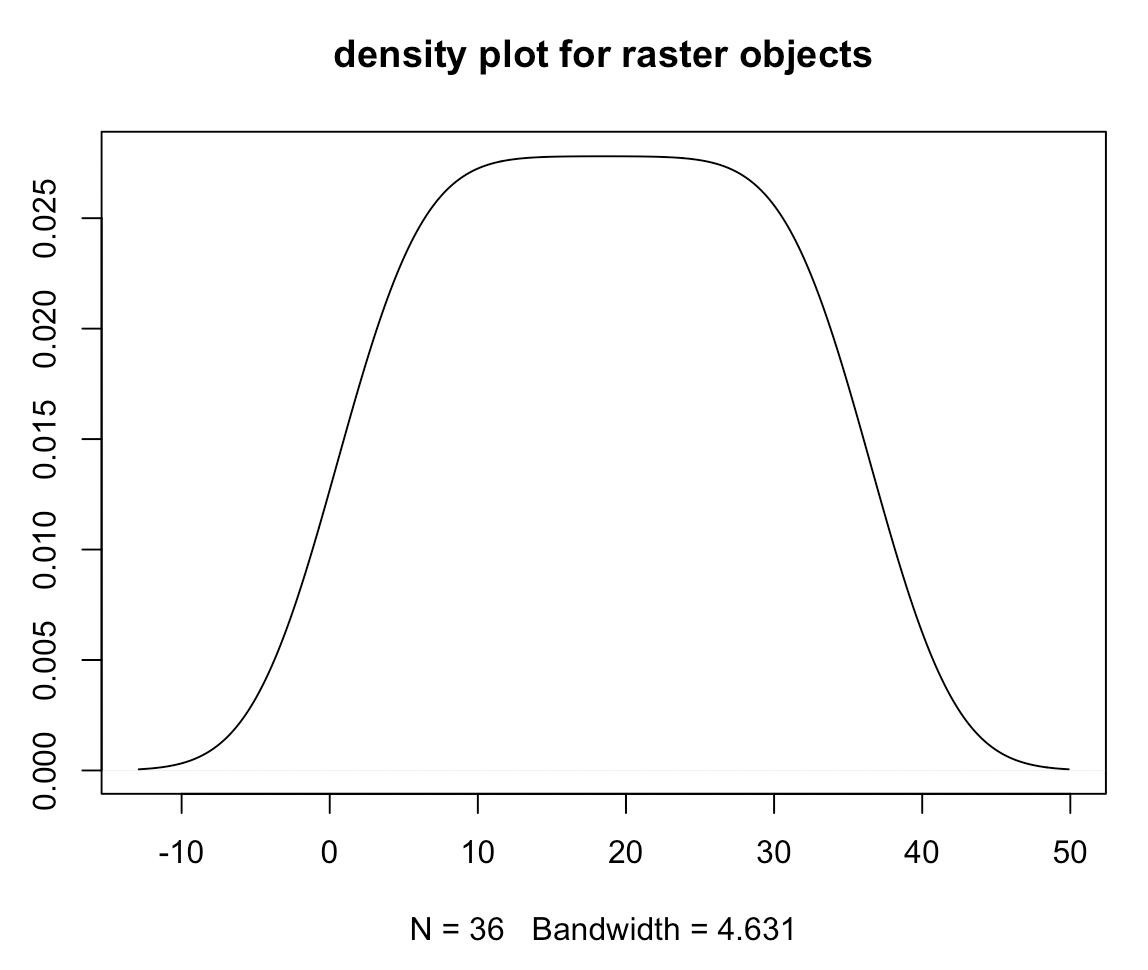
레스터 객체의 픽셀 속성값에 대해서 raster 패키지의 raster::density() 함수를 사용하여 추정 밀도 곡선(smoothed density estimates curve) 을 그릴 수 있습니다.
## raster::density() : density plot (smoothed density estimates)
density(elev, main = "density plot for raster objects")
레스터 객체의 픽셀 속성값에 대해 boxplot() 함수를 사용하면 상자그림(box plot for raster objects)을 그릴 수 있습니다.
## boxplot
boxplot(elev, main = "box plot for raster objects")
만약 레스터 객체에 대해 시각화를 하려고 하는데 안된다면 values() 또는 getValues() 함수를 사용해서 레스터 객체로 부터 픽셀의 속성값을 반환받은 결과에 대해서 시각화를 하면 됩니다.
레스터 객체의 행과 열의 일부분을 가져오는 것은 Base R의 '[' 연산자('[' operator) 를 사용합니다. raster_object[i, j] 또는 raster_object[Cell_IDs] 구문으로 i행과 j 열을 가져올 수 있습니다. 레스터 객체로 부터 일부분 가져오기는 '(a) 지리정보가 아닌 속성 정보를 가져오기(non-spatial subsetting)'와, '(b) 지리정보 가져오기 (spatial subsetting)' 의 두가지 유형으로 나눌 수 있는데요, 이번 포스팅은 '(a) 레스터 객체로부터 지리정보가 아닌 속성 정보를 가져오기'에 대해서만 다루겠습니다.
elev[1, 1] 은 evel 레스터 객체로 부터 1행과 1열에 위치한 픽셀(pixel, cell) 에 위치한 속성 값을 가져온 것입니다.
elev[1] 은 Cell ID 1번에 위치한 속성 값을 가져온 것입니다. (R 레스터는 좌측 상단에서 부터 1행 1열, Cell ID 1번이 시작하므로 elev[1, 1] 과 elev[1] 은 동일한 위치의 픽셀 속성 값을 가져옴)
## -- (1) Raster subsetting is done with the base R operator '['
## , which accepts a variety of inputs:
## - non-spatial subsetting: row-column indexing, cell IDs
## - spatial subsetting: coordinates, another spatial object
## subsetting the value of the top left pixel in the raster object 'elev'
## (1-1) row-column indexing
elev[1, 1]
# [1] 1
## (1-2) cell IDs
elev[1]
# [1] 1
레스터 객체의 전체 속성 값을 Cell ID의 순서대로 모두 가져오고 싶으면 values(), getValues() 함수 또는 [] 연산자를 사용하면 됩니다.
(2) 다층 레스터 객체(multi-layered laster objects)로 부터 일부 층(layers) 가져오기
(subsetting layers from multi-layered laster objects, a raster brick or stack)
다층 레스터 객체(multi-layered laster objects)로는 RasterBrick 클래스와 RasterStack 클래스가 있습니다. (자세한 설명은 rfriend.tistory.com/617 를 참고하세요.) 이들 다층 레스터 객체로 부터 특정 층을 가져오려면 raster 패키지의 subset() 함수를 사용합니다.
먼저, 예제로 사용할 수 있도록 grain 이라는 레스터 객체를 하나 더 만들고, 이를 (1)에서 만들었던 elev 레스터 객체에 stack() 함수로 쌓아서 다층 레스터 객체를 만들어보겠습니다.
values() 로 r_stack 안의 각 층별 속성값을 조회해보면 아래처럼 "elev" 층과 "grain" 층의 각 Cell 별로 들어있는 속성 값이 들어있음을 알 수 있습니다. (values(r_stack), getValues(r_stack), r_stack[] 모두 동일하게 각 층의 모든 속성값을 반환합니다.)
(3) 레스터 객체의 일부 값을 수정하기 (modifying values in raster objects)
만약 레스터 객체의 일부 값을 새로운 값으로 덮어쓰기, 업데이트, 수정을 하고 싶으면 앞에서 소개한 subsetting 기능을 활용해서 원하는 위치의 행과 열, 픽셀 ID(Pixel ID, Cell ID) 또는 층(layer) 의 subsetting 한 부분에 새로운 속성 값을 할당(<-, =) 하면 됩니다.
아래의 첫번째 예는 elev[1, 1] <- 0 은 elev 레스터 객체의 1행 1열 위치의 셀에 새로운 값 '0'을 할당한 것입니다.
아래의 두번째 예는 evel[1, 1:3] <- 0 은 elev 레스터 객체의 1행의 1~3열 위치 셀에 새로운 값 '0'을 할당하여 속성값을 수정한 것입니다.
이번 포스팅부터는 레스터 객체 데이터셋을 조작하는 방법(manipulating raster objects dataset)을 몇 개의 포스팅으로 나누어서 소개하겠습니다.
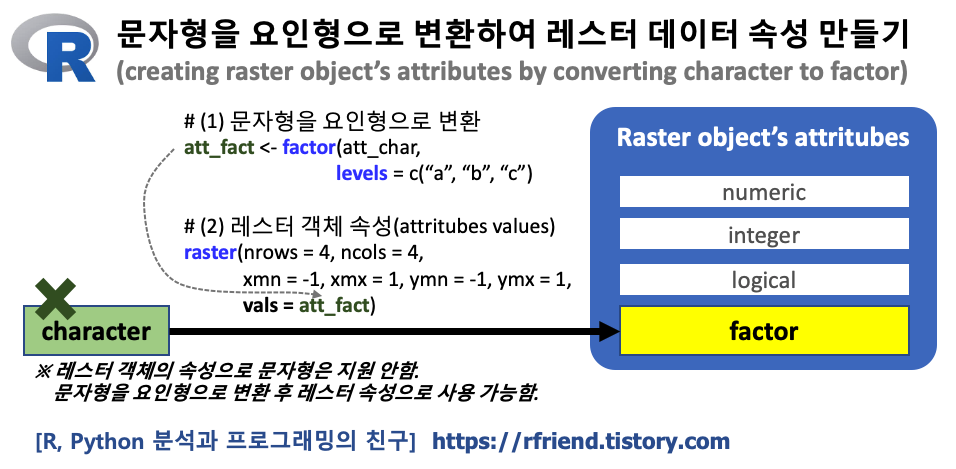
그 중에서도 이번 포스팅에서는 R 문자형을 요인형으로 변환하여 레스터 객체 데이터의 속성으로 만드는 방법(making raster objects attributes by converting character to factor type)을 알아보겠습니다.
R raster objects' attritubes with numeric, integer, logical and factor types. No support for character.
R의 레스터 객체(raster objects)는 데이터 속성으로 숫자형(numeric), 정수형(integer), 논리형(logical), 요인형(factor) 데이터 유형을 지원하며, 문자형(character)은 지원하지 않습니다. 따라서 문자형으로 이루어진 범주형 변수 값(categorical variables' values)을 가지고 레스터 객체의 속성(attritubes)을 만들고 싶으면 (1) 먼저 문자형을 요인형으로 변환 (또는 논리형으로 변환)하고, --> (2) 요인형 값을 속성 값으로 해서 레스터 객체를 만들어야 합니다.
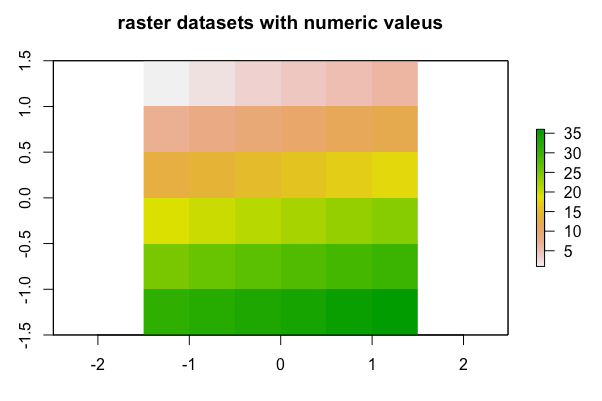
먼저, 레스터 객체 데이터에 대한 이해를 돕기위해, 정수형(integer) 값을 속성 값으로 가지는 레스터 객체를 raster 패키지의 raster() 함수를 사용해서 만들어보겠습니다. 아래의 예에서는 6 x 6 = 36개의 픽셀(pixels, cells)에, x와 y의 좌표값의 최소~최대값 범위의 좌표에, 1~36까지의 정수를 속성 값으로 가지는 레스터 객체 데이터 입니다.
## ========================================================
## R GeoSpatial data analysis
## : Manipulating Raster Objects
## [reference] https://geocompr.robinlovelace.net/attr.html
## ========================================================
## raster data represent continuous surfaces.
## Because of their unique structure,
## subsetting and other operations on raster datasets work in a different way.
library(raster)
## -- creating an example raster dataset
elev <- raster(nrows = 6, # integer > 0. Number of rows
ncols = 6, # integer > 0. Number of columns
#res = 0.5, # numeric vector of length 1 or 2 to set the resolution
xmn = -1.5, # minimum x coordinate (left border)
xmx = 1.5, # maximum x coordinate (right border)
ymn = -1.5, # minimum y coordinate (bottom border)
ymx = 1.5, # maximum y coordinate (top border)
vals = 1:36) # values for the new RasterLayer
elev
# class : RasterLayer
# dimensions : 6, 6, 36 (nrow, ncol, ncell)
# resolution : 0.5, 0.5 (x, y)
# extent : -1.5, 1.5, -1.5, 1.5 (xmin, xmax, ymin, ymax)
# crs : +proj=longlat +datum=WGS84 +no_defs
# source : memory
# names : layer
# values : 1, 36 (min, max)
plot(elev, main = 'raster datasets with numeric valeus')
이제 본론으로 넘어가서, 문자형으로 이루어진 범주형 변수를 요인형으로 변환한 후에, 이를 다시 레스터 객체의 속성으로 하여 레스터 객체를 만드는 방법을 소개하겠습니다.
(1)
문자형(character)을 요인형(factor)으로 변환할 때는 R base 패키지의 factor() 를 사용합니다. 이때 요인의 수준(levels)은 범주형 변수 내 유일한(unique) 문자열을 오름차순으로 정렬(sorting in an increasing order)하여 부여가 되는데요, 만약 요인의 수준(levels)을 특정 순서에 맞게 분석가가 수작업으로 설정을 하고 싶다면 levels 매개변수를 사용해서 직접 요인 수준을 입력을 해주면 됩니다.
아래 예에서는 모래의 굵기의 수준에 따라서 "점토(clay)", "미세모래(silt)", "모래(sand)"의 순서로 levels 매개변수를 이용해 요인의 수준을 설정해서, factor() 함수로 문자형으로 구성된 범주형 변수('grain_order')를 요인형 변수('grain_fact')으로 변환해준 것입니다.
<--> 만약 factor() 함수로 요인형으로 변환할 때 levels 매개변수로 요인 수준의 순서를 지정해주지 않는다면, default 인 유일한 문자형 값들의 오름차순 정렬에 따라서 ["clay", "sand", "silt"] 의 순서로 설정이 되었을 것입니다.
## -- raster objects can contain values of class numeric, integer, logical or factor,
## but not character.
## Raster objects can also contain categorical values of
## class logical or factor variables in R.
grain_order <- c("clay", "silt", "sand")
## random sampling with replacement
set.seed(1004)
grain_char <- sample(grain_order, 36, replace = TRUE)
grain_char
# [1] "sand" "silt" "clay" "clay" "clay" "sand" "silt" "silt" "silt" "clay" "sand" "silt" "sand" "sand"
# [15] "sand" "clay" "sand" "clay" "sand" "clay" "sand" "sand" "silt" "clay" "sand" "silt" "sand" "clay"
# [29] "clay" "clay" "sand" "sand" "clay" "sand" "sand" "clay"
## converting character into factor
grain_fact <- factor(grain_char,
# ordered factor: clay < silt < sand in terms of grain size.
levels = grain_order)
grain_fact
# [1] sand silt clay clay clay sand silt silt silt clay sand silt sand sand sand clay sand clay sand clay
# [21] sand sand silt clay sand silt sand clay clay clay sand sand clay sand sand clay
# Levels: clay silt sand
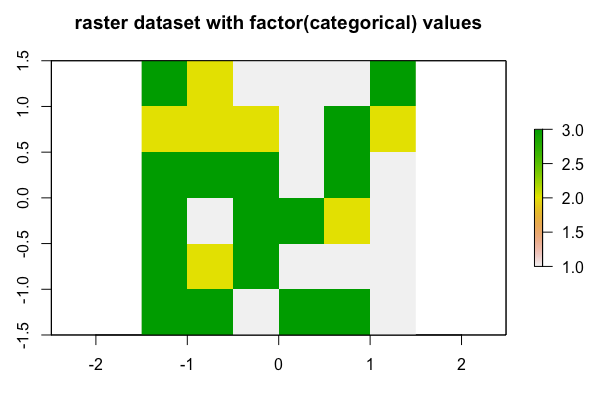
(2) 요인형 값을 속성으로 한 레스터 객체 데이터 만들기 (creating raster objects with factor values)
위의 (1)번에서 문자열 값을 요인형으로 변환한 값을 가지고 raster 패키지의 raster() 함수를 사용해서 레스터 객체를 만들어보겠습니다. 행의 수(nrows) 6개, 열의 수(ncols) 6개의 총 36개 픽셀(pixcels, cells)을 가지는 레스터 객체에 raster(nrows = 6, ncols = 6, res = 0.5, vals = grain_fact)('grain_fact' 는 요인형 값을 가지는 벡터임) 을 입력하였습니다.
레스터 객체 데이터에 대해서 plot() 함수로 간단하게 시각화를 할 수 있습니다. 이때 요인형의 수준 값(levels)인 clay = 1, silt = 2, sand = 3 의 정수값을 가지고 시각화를 하게 됩니다.
이번에는 levels() 와 cbind() 함수를 사용해서 기존의 요인의 수준에다가 wetness = c("wet", "moist", "dry") 라는 새로운 요인 수준을 추가(adding new factor levels to the attritube table) 하여 보겠습니다.
## -- Use the function levels() for retrieving and
## adding new factor levels to the attribute table:
levels(grain_raster)
# [[1]]
# ID VALUE
# 1 1 clay
# 2 2 silt
# 3 3 sand
## adding new factor levels
levels(grain_raster)[[1]] = cbind(levels(grain_raster)[[1]],
wetness = c("wet", "moist", "dry"))
## retrieving factor levels
levels(grain_raster)
# [[1]]
# ID VALUE wetness
# 1 1 clay wet
# 2 2 silt moist
# 3 3 sand dry
레스터 객체 데이터의 "attritubes"라는 이름의 속성 테이블(attritube table)에 요인형 수준 값이 저장되어 있으며, 여기에 새로운 요인형 수준 값이 추가되는 것입니다. ratify() 함수를 사용하면 이 속성 테이블(attritube table)에 저장되어 있는 값을 조회할 수 있습니다.
## -- The raster object stores the corresponding look-up table
## or “Raster Attribute Table” (RAT) as a data frame in a new slot named attributes,
## which can be viewed with ratify(grain)
ratify(grain_raster)
# class : RasterLayer
# dimensions : 6, 6, 36 (nrow, ncol, ncell)
# resolution : 0.5, 0.5 (x, y)
# extent : -1.5, 1.5, -1.5, 1.5 (xmin, xmax, ymin, ymax)
# crs : +proj=longlat +datum=WGS84 +no_defs
# source : memory
# names : layer
# values : 1, 3 (min, max)
# attributes :
# ID
# 1
# 2
# 3
레스터 객체의 각 픽셀(pixcel, cell)은 단 하나의 값만을 가질 수 있습니다. 이 예제에서는 각 픽셀이 하나의 요인 수준 값을 가지고 있는데요, 아래 예는 레스터 객체의 1번, 10번, 26번 픽셀의 요인 수준 값이 3, 1, 2 이고, 이들 요인 수준 값에 대응하는 속성 정보를 factorValues() 함수를 사용하여 속성 테이블(attritube table) 로 부터 매핑하여 보여주는 것입니다.
## -- looking up the attributes in the corresponding attribute table
grain_raster[c(1, 10, 26)]
# [1] 3 1 2
factorValues(grain_raster, grain_raster[c(1, 10, 26)])
# VALUE wetness
# 1 sand dry
# 2 clay wet
# 3 silt moist
지난번 포스팅에서는 두 개의 sf 클래스 객체의 지리 벡터 데이터 테이블을 R dplyr 패키지의 함수를 사용하여 Mutating Joins, Filtering Joins, Nesting Joins 하는 방법을 소개하였습니다(rfriend.tistory.com/625).
이번 포스팅에서는 여기서 특수한 경우로 조금 더 깊이 들어가서, 두 테이블을 Join 하는 기준이 되는 Key 칼럼이 문자열로 되어 있고, 데이터 표준화가 미흡한 문제로 인해 정확하게 매칭이 안되어서 Join 이 안되는 경우에, R의 stringr 패키지를 사용해 정규 표현식의 문자열 매칭(a string matching using regular expression)으로 Key 값을 변환하여 두 테이블을 Join 하는 방법을 소개하겠습니다.
먼저, 전세계 국가별 지리기하와 속성 정보를 모아놓은 sf 클래스 객체의 지리 벡터 데이터셋인 "world" 와, 2016년과 2017년 국가별 커피 생산량을 집계한 data frame 인 "coffee_data" 의 두 개 데이터셋을 spData 로 부터 가져오겠습니다.
그리고 두 개 테이블 Join 을 위해 dplyr 패키지를 불러오고, 정규 표현식을 이용한 문자열 매칭을 위해 stringr 패키지를 불러오겠습니다.
"world" 데이터셋은 177개의 행(국가)과 11개의 열(속성(attritubes)과 지리기하 칼럼(gemgraphy column)) 으로 이루어져 있습니다. "coffee_data"는 47개의 행과 3개의 열로 구성되어 있습니다.
## =========================================================
## inner join using a string matching
## - reference: https://geocompr.robinlovelace.net/attr.html
## =========================================================
library(sf)
library(spData)
library(dplyr)
library(stringr) # for a string matching
## -- two geography vector dataset tables : world, coffee_data
## -- (a) world: World country pologons in spData
names(world)
# [1] "iso_a2" "name_long" "continent" "region_un" "subregion" "type" "area_km2" "pop" "lifeExp" "gdpPercap"
# [11] "geom"
dim(world)
# [1] 177 11
## -- (b) coffee_data: World coffee productiond data in spData
## : estimated values for coffee production in units of 60-kg bags in each year
names(coffee_data)
# [1] "name_long" "coffee_production_2016" "coffee_production_2017"
dim(coffee_data)
# [1] 47 3
(1) 두 테이블 inner join 하기: inner_join(x, y, by)
"world"와 "coffee_data"의 두개 데이터 테이블을 inner join 해보면 45개의 행(즉, 국가)과 13개의 열(= "world"로 부터 11개의 칼럼 + "coffee_data"로 부터 2개의 칼럼) 으로 이루어진 Join 결과를 반환합니다.
위에서 "coffee_data" 데이터셋이 47개의 행으로 이루어졌다고 했는데요, inner join 한 결과는 행이 45개로서 2개가 서로 차이가 나는군요.
## -- inner join
world_coffee_inner = inner_join(x = world,
y = coffee_data,
by = "name_long")
## or shortly
world_coffee_inner = inner_join(world, coffee_data)
# Joining, by = "name_long"
dim(world_coffee_inner)
# [1] 45 13
nrow(world_coffee_inner)
# [1] 45
(2) 두 문자열의 원소 차이 알아보고 문자열 매칭으로 찾아보기: setdiff(), str_subset()
Join 전과 후에 어느 국가에서 차이가 나는지 확인해 보기 위해 setdiff() 함수를 사용해서 Join의 Key로 사용이 되었던 'name_long' (긴 국가 이름)에 대해 "coffee_data" 와 "world" 데이터의 원소 간 차이를 구해보았습니다. 그랬더니 ["Congo, Dem. Rep. of", "Others"] 의 2개 'name_long' 에서 차이가 있네요.
다음으로, "world" 의 'name_long' 칼럼의 원소 중에서 "Dem"으로 시작하고 "Congo"를 포함하고 있는 문자열을 stringr 패키지의 str_subset(string, pattern) 함수를 사용해 정규 표현식의 문자열 매칭으로 찾아보겠습니다. "world" 데이터셋의 'name_long' 칼럼에는 "Democratic Republic of the Congo" 라는 이름으로 데이터가 들어가 있네요. ("coffee_data" 데이터셋에는 "Confo, Dem. Rep. of" 라고 들어가 있다보니, 서로 같은 국가임에도 left_join() 을 했을 때 서로 정확하게 매칭이 안되어 Join 이 안되었습니다.)
참고로, str_subset() 은 x[str_detect(x, pattern)] 의 wrapper 입니다. 그리고 grep(pattern, x, value = TRUE) 와 동일한 역할을 수행합니다.
## setdiff(): calculates the set difference of subsets of two data frames
setdiff(coffee_data$name_long, world$name_long)
# [1] "Congo, Dem. Rep. of" "Others"
## string matching (regex) function from the stringr package
str_subset(world$name_long, "Dem*.+Congo")
# [1] "Democratic Republic of the Congo"
(3) 문자열 매칭으로 Key 값 업데이트 하고, 다시 두 테이블 inner join 하기
이제 Join Key로 사용하는 'name_long' 칼럼에서 "Congo" 국가에 대한 표기가 "world" 와 "coffee_data" 의 두 개 데이터셋이 서로 조금 다르다는 이유로 Join 이 안된다는 문제를 해결해 보겠습니다.
grepl(pattern, x) 함수로 "coffee_data" 데이터셋의 'name_long' 칼럼에서 "Congo" 가 들어있는 행을 찾아서, 그 행의 값의 str_subset() 의 정규표현식 문자열 매칭으로 찾은 (str_subset(world$name_long, "Dem*.+Congo") 이름인 "Demogratic Republic of the Congo" 라는 이름으로 대체를 해보겠습니다. 이렇게 하면 "world"와 "coffee_data"에 있는 "Congo" 국가의 긴 이름이 동일하게 "Demogratic Republic of Congo"로 되어 Join 이 제대로 될 것입니다.
## updating 'name_long' values using a string matching
coffee_data$name_long[grepl("Congo", coffee_data$name_long)] =
str_subset(world$name_long, "Dem*.+Congo")
## inner join again using an updated key
world_coffee_match = inner_join(world, coffee_data)
#> Joining, by = "name_long"
nrow(world_coffee_match)
#> [1] 46
참고로, R에서 문자열 패턴 매칭을 할 때 grepl(pattern, x) 은 패턴 매칭되는 여부에 대해 TRUE, FALSE 로 블러언 값을 반환하는 반면에, grep(pattern, x) 은 패턴 매칭이 되는(TRUE) 위치 인덱스(Position Index)를 반환합니다.
dplyr 패키지로 두 테이블을 Join 할 때 왼쪽(x, LHS, Left Hand Side)에 써주는 테이블의 데이터 구조로 Join 한 결과를 반환합니다. 즉, Join 할 테이블을 써주는 순서가 중요합니다.
가령, 아래의 예에서는 "world" 가 'sf' 클래스의 지리 벡터 객체이고, 'coffee_data'는 tydiverse의 tibble, data.frame 객체입니다. left_join(world, coffee_data) 로 'world' 의 'sf' 지리 벡터 객체를 Join 할 때 왼쪽(LHS, x)에 먼저 써주면 Join 한 결과도 'sf' 클래스의 지리 벡터 객체가 됩니다.(R이 지리공간 벡터 데이터임을 알고 'sf' 클래스를 적용한 지리공간 데이터 처리 및 분석이 가능함).
반면에, left_join(coffee_data, world) 로 'coffee_data'의 'data.frame'을 Join 할 때 왼쪽(LHS, x)에 먼저 써주면 Join 한 결과도 'data.frame' 객체가 반환됩니다. (지리공간 'sf' 클래스가 더이상 아님)
## starting with a non-spatial dataset and
## adding variables from a simple features object.
## the result is not another simple feature object,
## but a data frame in the form of a tidyverse tibble:
## the output of a join tends to match its first argument.
## -- (a) 'sf' object first, then returns 'sf' object.
world_coffee = left_join(world, coffee_data)
#> Joining, by = "name_long"
class(world_coffee)
# [1] "sf" "tbl_df" "tbl" "data.frame"
## -- (b) 'data.frame' object first, then returns 'data.frame' object.
coffee_world = left_join(coffee_data, world)
#> Joining, by = "name_long"
class(coffee_world)
#> [1] "tbl_df" "tbl" "data.frame"
(5) data.frame을 'sf' 클래스 객체로 변환하기
'sf' 패키지의 st_as_df() 함수를 사용하면 data.frame 을 'sf' 클래스 객체로 변환할 수 있습니다.
## -- converting data.frame to 'sf' class object
st_as_sf(coffee_world)
# imple feature collection with 47 features and 12 fields (with 2 geometries empty)
# geometry type: MULTIPOLYGON
# dimension: XY
# bbox: xmin: -117.1278 ymin: -33.76838 xmax: 156.02 ymax: 35.49401
# geographic CRS: WGS 84
# # A tibble: 47 x 13
# name_long coffee_producti~ coffee_producti~ iso_a2 continent region_un subregion type area_km2 pop lifeExp gdpPercap
# <chr> <int> <int> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
# 1 "Angola" NA NA AO Africa Africa Middle A~ Sove~ 1245464. 2.69e7 60.9 6257.
# 2 "Bolivia" 3 4 BO South Am~ Americas South Am~ Sove~ 1085270. 1.06e7 68.4 6325.
# 3 "Brazil" 3277 2786 BR South Am~ Americas South Am~ Sove~ 8508557. 2.04e8 75.0 15374.
# 4 "Burundi" 37 38 BI Africa Africa Eastern ~ Sove~ 26239. 9.89e6 56.7 803.
# 5 "Cameroo~ 8 6 CM Africa Africa Middle A~ Sove~ 460325. 2.22e7 57.1 3196.
# 6 "Central~ NA NA CF Africa Africa Middle A~ Sove~ 621860. 4.52e6 50.6 597.
# 7 "Congo, ~ 4 12 NA NA NA NA NA NA NA NA NA
# 8 "Colombi~ 1330 1169 CO South Am~ Americas South Am~ Sove~ 1151883. 4.78e7 74.0 12716.
# 9 "Costa R~ 28 32 CR North Am~ Americas Central ~ Sove~ 53832. 4.76e6 79.4 14372.
# 10 "C\u00f4~ 114 130 CI Africa Africa Western ~ Sove~ 329826. 2.25e7 52.5 3055.
# # ... with 37 more rows, and 1 more variable: geom <MULTIPOLYGON [arc_degree]>
다음번 포스팅에서는 '지리공간 벡터 데이터에서 새로운 속성을 만들고 지리공간 정보를 제거하는 방법'에 대해서 알아보겠습니다.
지난번 포스팅에서는 R 지리공간 벡터 데이터의 속성 정보에 대해서 Base R, dplyr, data.table 패키지를 사용하여 그룹별로 집계하는 방법(rfriend.tistory.com/624)을 소개하였습니다.
이번 포스팅에서는 dplyr 패키지를 사용하여 두 개의 지리공간 벡터 데이터 테이블을 Join 하는 여러가지 방법을 소개하겠습니다. [1] Database SQL에 이미 익숙한 분이라면 이번 포스팅은 매우 쉽습니다. 왜냐하면 dplyr 의 두 테이블 간 Join 이 SQL의 Join 을 차용해서 만들어졌기 때문입니다.
R의 sf 클래스 객체인 지리공간 벡터 데이터를 dplyr 의 함수를 사용해서 두 테이블을 join 하면 속성(attributes)과 함께 지리공간 geometry 칼럼과 정보도 join 된 후의 테이블에 자동으로 그대로 따라가게 됩니다.
(1) Mutating Joins : 두 테이블을 합쳐서 새로운 테이블을 생성하기
- (1-1) inner join
- (1-2) left join
- (1-3) right join
- (1-4) full join
(2) Filtering Joins : 두 테이블의 매칭되는 부분을 기준으로 한쪽 테이블을 걸러내기
- (2-1) semi join
- (2-2) anti join
(3) Nesting joins : 한 테이블의 모든 칼럼을 리스트로 중첩되게 묶어서 다른 테이블에 합치기
- (3-1) nest join
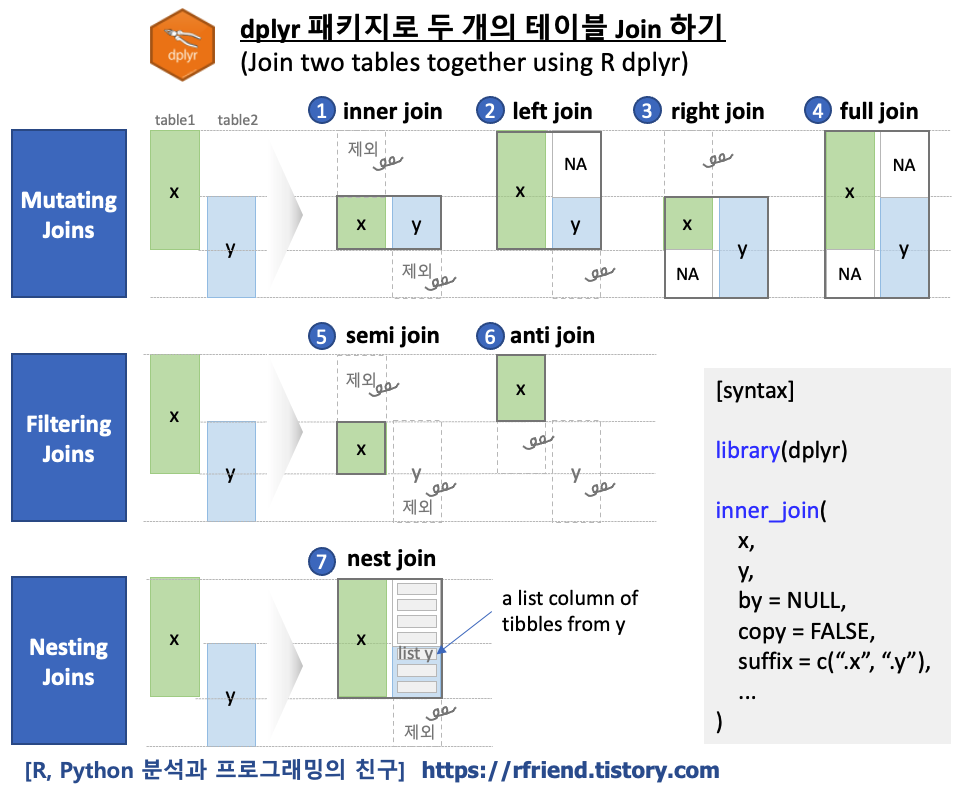
R dplyr 패키지가 두 테이블 Join 을 하는데 제공하는 함수는 inner_join(), left_join(), right_join(), full_join(), semi_join(), anti_join(), nest_join() 의 총 7개가 있으며, 이는 크게 (a) Mutating Joins, (b) Filtering Joins, (3) Nesting Joins의 3개의 범주로 분류할 수 있습니다.
[ R dplyr 패키지로 두 개의 테이블 Join 하기 (Joining two tables together using R dplyr) ]
joining two tables using R dplyr
(1) Mutating Joins
Mutation Joins 는 두 개의 테이블을 Key를 기준으로 Join 하여 두 개 테이블로 부터 가져온 (전체 또는 일부) 행과 모든 열로 Join 하여 새로운 테이블을 만들 때 사용합니다. 위의 그림에서 보는 바와 같이 왼쪽(Left Hand Side, LHS)의 테이블과 오른쪽(Right Hand Side, RHD)의 테이블로 부터 모두 행과 열을 가져와서 Join 된 테이블을 반환하며, 이때 왼쪽(LHS)와 오른쪽(RHS) 중에서 어느쪽 테이블이 기준이 되느냐에 따라 사용하는 함수가 달라집니다.
(1-1) inner join
먼저, 예제로 사용할 sf 클래스 객체로서, spData 패키지에서 세계 국가별 속성정보와 지리기하 정보를 가지고 있는 'world' 데이터셋, 그리고 2016년과 2017년도 국가별 커피 생산량을 집계한 coffee_data 데이터셋을 가져오겠습니다. "world" 데이터셋은 177개의 관측치, 11개의 칼럼을 가지고 있고, "coffee_data" 데이터셋은 47개의 관측치, 3개의 칼럼을 가지고 있습니다. 그리고 두 데이터셋은 공통적으로 'name_long' 이라는 국가이름 칼럼을 가지고 있으며, 이는 두 테이블을 Join 할 때 기준 Key 로 사용이 됩니다.
테이블 Join 을 위해 dplyr 패키지를 불러오겠습니다.
## ==================================
## GeoSpatial Data Analysis using R
## : Vector attribute joining
## : reference: https://geocompr.robinlovelace.net/attr.html
## ==================================
library(sf)
library(spData) # for sf data
library(dplyr)
## -- (a) world: World country pologons in spData
names(world)
# [1] "iso_a2" "name_long" "continent" "region_un" "subregion" "type" "area_km2" "pop" "lifeExp" "gdpPercap"
# [11] "geom"
dim(world)
# [1] 177 11
## -- (b) coffee_data: World coffee productiond data in spData
## : estimated values for coffee production in units of 60-kg bags in each year
names(coffee_data)
# [1] "name_long" "coffee_production_2016" "coffee_production_2017"
dim(coffee_data)
# [1] 47 3
dplyr 패키지의 테이블 Join 에 사용하는 함수들의 기본 구문은 아래와 같이 왼쪽(x, LHS), 오른쪽(y, RHS) 테이블, 두 테이블을 매칭하는 기준 칼럼(by), 데이터 source가 다를 경우 복사(copy) 여부, 접미사(suffix) 등의 매개변수로 구성되어 서로 비슷합니다.
## dplyr join syntax library(dplyr)
## -- (a) Mutating Joins inner_join(x, y, by = NULL, copy = FALSE, suffix = c(".x", ".y"), ...) left_join(x, y, by = NULL, copy = FALSE, suffix = c(".x", ".y"), ...) right_join(x, y, by = NULL, copy = FALSE, suffix = c(".x", ".y"), ...) full_join(x, y, by = NULL, copy = FALSE, suffix = c(".x", ".y"), ...)
## -- (b) Filtering Joins semi_join(x, y, by = NULL, copy = FALSE, ...) anti_join(x, y, by = NULL, copy = FALSE, ...)
## -- (c) Nesting Joins nest_join(x, y, by = NULL, copy = FALSE, keep = FALSE, name = NULL, ...)
inner join 은 두 테이블에서 Key 칼럼을 기준으로 서로 매칭이 되는 행에 대해서만, 두 테이블의 모든 칼럼을 반환합니다. 그럼, "world"와 "coffee_data" 두 데이터셋 테이블을 공통의 칼럼인 "name_long" 을 기준으로 inner join 해보겠습니다. 두 테이블에 공통으로 "name_long"이 존재하는 관측치가 45개가 있네요.
만약 두 테이블 x, y 에 다수의 매칭되는 값이 있을 경우에는, 모든 가능한 조합의 값을 반환하므로, 주의가 필요합니다.
dplyr 의 Join 함수들은 두 테이블 Join 의 기준이 되는 Key 칼럼 이름을 by 매개변수에 안써주면 두 테이블에 공통으로 존재하는 칼럼을 Key 로 삼아서 Join 을 수행하고, 콘솔 창에 'Joining, by = "name_long"' 과 같이 Key 를 출력해줍니다.
left join 은 왼쪽의 테이블(LHS, x)을 모두 반환하고 (기준이 됨), 오른쪽 테이블(RHS, y)은 왼쪽 테이블과 Key 값이 매칭되는 관측치에 대해서만 모든 칼럼을 왼쪽 테이블에 Join 하여 반환합니다. 만약 오른쪽 테이블(RHS, y)에 매칭되는 값이 없는 경우 x 테이블의 y에 해당하는 행은 NA 로 채워집니다.
아래 예에서는 왼쪽에 있는 "world" 테이블을 기준으로 오른쪽의 "coffee_data"를 공통으로 존재하는 'name_long' 칼럼을 Key로 해서 left join 을 한 것입니다. 12번째와 13번째 칼럼에 오른쪽 테이블인 "coffee_data" 에서 Join 해서 가져온 "coffee_production_2016", "coffee_production_2017"의 칼럼이 왼쪽 "world" 테이블에 Join 이 되었습니다.
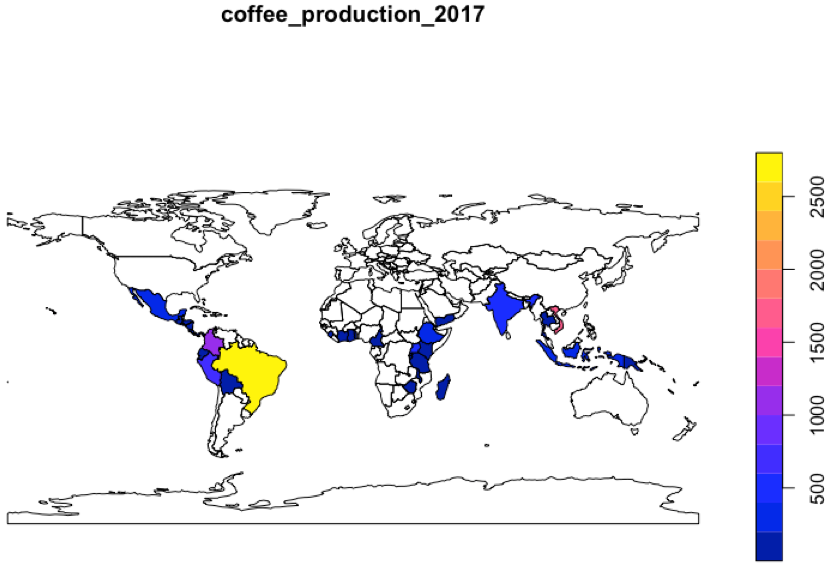
plot() 함수로 다면(multi-polygons) 기하도형으로 구성된 세계 국가별 지도에 2017년도 커피 생산량을 시각화해보았습니다. 지리기학 벡터 데이터를 Join 했을 때 누릴 수 있는 geometry 칼럼을 사용할 수 있는 혜택이 되겠습니다.
두 테이블을 Join 할 때 기준이 되는 Key 칼럼의 이름이 서로 다른 경우 by 매개변수에 서로 다른 변수 이름을 구체적으로 명시해주면 됩니다. 아래 예에서는 오른쪽 "coffee_data" 테이블의 'name_long' 칼럼 이름을 'nm'으로 바꿔준 후에, by = c(name_long = "nm") 처럼 Join하려는 두 테이블의 서로 다른 이름의 Key 변수들을 명시해주었습니다.
## -- Using the 'by' argument to specify the joining variables
coffee_renamed = rename(coffee_data, nm = name_long)
world_coffee2 = left_join(world, coffee_renamed,
by = c(name_long = "nm")) # specify the joining variables
names(world_coffee2)
# [1] "iso_a2" "name_long" "continent" "region_un"
# [5] "subregion" "type" "area_km2" "pop"
# [9] "lifeExp" "gdpPercap" "geom" "coffee_production_2016"
# [13] "coffee_production_2017"
(1-3) right join
right join 은 오른쪽 테이블(RHS, y) 을 전부 반환하고, 왼쪽 테이블 (LHS, x) 은 오른쪽(y) 테이블과 매칭이 되는 값에 대해서만 모든 칼럼을 Join 해서 반환합니다. Key 칼럼을 기준으로 왼쪽 테이블에 없는 값은 NA 처리가 되어 오른쪽 테이블에 Join 됩니다. (위의 그림 도식을 참고하세요).
만약 왼쪽과 오른쪽 테이블에 다수의 매칭되는 값들이 있을 경우 매칭되는 값들의 모든 조합으로 Join 됩니다. 아래 예에서 Join 의 기준이 되는 Key 를 명기해주는 매개변수 by = 'name_long' 는 두 테이블에 공통으로 존재하므로 생략 가능합니다.
## -- (1-3) right join: return all rows from y, and all columns from x.
world_coffee_right = right_join(x = world,
y = coffee_data,
by = 'name_long')
dim(world) # -- left
# [1] 177 11
dim(coffee_data) # -- right
# [1] 47 3
dim(world_coffee_right) # -- right join
# [1] 47 13
(1-4) full join
full Join 은 왼쪽 (LHS, x)과 오른쪽(RHS, y)의 모든 행과 열을 반환합니다.
## -- (1-4) full join: return all rows and all columns from both x and y.
world_coffee_full = full_join(x = world,
y = coffee_data,
by = 'name_long')
dim(world_coffee_full)
# [1] 179 13
names(world_coffee_full)
# [1] "iso_a2" "name_long" "continent" "region_un"
# [5] "subregion" "type" "area_km2" "pop"
# [9] "lifeExp" "gdpPercap" "geom" "coffee_production_2016"
# [13] "coffee_production_2017"
어느 한쪽 테이블에서 버려지는 값이 없으며, 만약 왼쪽이나 오른쪽 테이블에 없는 값이면 "NA" 처리됩니다. 아래의 왼쪽 "world" 테이블과 오른쪽의 "coffee_data" 테이블 간에 서로 매칭되지 않는 부분은 "NA"가 들어가 있음을 알 수 있습니다.
## Where there are not matching values, returns 'NA' for the one missing.
head(world_coffee_full[, c(2:3, 9:13)], 10)
# Simple feature collection with 10 features and 6 fields
# geometry type: MULTIPOLYGON
# dimension: XY
# bbox: xmin: -180 ymin: -55.25 xmax: 180 ymax: 83.23324
# geographic CRS: WGS 84
# # A tibble: 10 x 7
# name_long continent lifeExp gdpPercap geom coffee_productio~ coffee_productio~
# <chr> <chr> <dbl> <dbl> <MULTIPOLYGON [arc_degree]> <int> <int>
# 1 Fiji Oceania 70.0 8222. (((180 -16.06713, 180 -16.55522, 179.3641 ~ NA NA
# 2 Tanzania Africa 64.2 2402. (((33.90371 -0.95, 34.07262 -1.05982, 37.6~ 81 66
# 3 Western Sa~ Africa NA NA (((-8.66559 27.65643, -8.665124 27.58948, ~ NA NA
# 4 Canada North Amer~ 82.0 43079. (((-122.84 49, -122.9742 49.00254, -124.91~ NA NA
# 5 United Sta~ North Amer~ 78.8 51922. (((-122.84 49, -120 49, -117.0312 49, -116~ NA NA
# 6 Kazakhstan Asia 71.6 23587. (((87.35997 49.21498, 86.59878 48.54918, 8~ NA NA
# 7 Uzbekistan Asia 71.0 5371. (((55.96819 41.30864, 55.92892 44.99586, 5~ NA NA
# 8 Papua New ~ Oceania 65.2 3709. (((141.0002 -2.600151, 142.7352 -3.289153,~ 114 74
# 9 Indonesia Asia 68.9 10003. (((141.0002 -2.600151, 141.0171 -5.859022,~ 742 360
# 10 Argentina South Amer~ 76.3 18798. (((-68.63401 -52.63637, -68.25 -53.1, -67.~ NA N
(2) Filtering Joins
Filtering Joins 은 두 테이블의 매칭되는 값을 기준으로 한쪽 테이블의 값을 걸러내는데 사용합니다.
(2-1) semi join
semi join 은 왼쪽(LHS, x)과 오른쪽(RHS, y) 테이블의 서로 매칭되는 값에 대해 왼쪽(LHS, x)의 모든 칼럼을 반환합니다. 이때 매칭 여부를 평가하는데 사용되었던 오른쪽 테이블(RHS, y)의 값은 하나도 가져오지 않으며, 단지 왼쪽 테이블(x)을 걸러내느데(filtering)만 사용하였다는 점이 위의 (1-2) Left Join 과 다른 점입니다. (위의 도식을 참고하세요)
## -- (2) Filtering joins
## -- (2-1) semi join
## : return all rows from x where there are matching values in y,
## : keeping just columns form x.
world_coffee_semi = semi_join(world, coffee_data)
# Joining, by = "name_long"
dim(world_coffee_semi)
# [1] 45 11
names(world_coffee_semi)
# [1] "iso_a2" "name_long" "continent" "region_un" "subregion" "type" "area_km2" "pop"
# [9] "lifeExp" "gdpPercap" "geom"
(2-2) anti join
anti join 은 왼쪽 테이블(LHS, x)과 오른쪽 테이블(RHS, y)의 매칭되는 부분을 왼쪽 테이블(LHS, x)에서 걸러낸 x의 모든 칼럼을 반환합니다. 이때 매칭 여부를 평가하는데 사용되었던 오른쪽(RHS, y) 테이블의 값은 하나도 가져오지 않으며, 단지 왼쪽 테이블(x)을 걸러내는데(filtering)만 사용합니다.
위의 (2-1)의 semi join 은 x와 y의 매칭되는 부분의 x값만을 반환하였다면, 이번 (2-2)의 anti join 은 반대로 x와 j의 매칭이 안되는 부분의 x값만을 반환하는게 다릅니다. (y 값은 안가져오는 것은 semi join 과 anti join 이 동일함.)
## -- (6) anti join
## : return all rows from x where there are not matching values in y,
## : keeping just columns from x.
world_coffee_anti = anti_join(world, coffee_data)
# Joining, by = "name_long"
dim(world_coffee_anti)
# [1] 132 11
names(world_coffee_anti)
# [1] "iso_a2" "name_long" "continent" "region_un" "subregion" "type" "area_km2" "pop"
# [9] "lifeExp" "gdpPercap" "geom"
(3) Nesting Joins
(3-1) nest join
nest join 은 왼쪽 테이블(LHS, x)의 모든 행과 열을 반환하며, 이때 오른쪽(RHS, y)의 매칭되는 부분의 모든 칼럼의 값들을 list 형태로 중첩되게 묶어서 왼쪽 x 테이블에 join 해줍니다. 즉, 오른쪽 y 테이블의 매칭되는 값들의 칼럼이 여러개 이더라도 왼쪽 x 테이블에 join 이 될 때는 1개의 칼럼에 list 형태로 오른쪽 y 테이블의 여러개 칼럼의 값들이 묶여서 join 됩니다.
## -- (3) Nesting joins
## -- (3-1) nest join
## : eturn all rows and all columns from x. Adds a list column of tibbles.
## : Each tibble contains all the rows from y that match that row of x.
world_coffee_nest = nest_join(world, coffee_data)
# Joining, by = "name_long"
dim(world_coffee_nest)
# [1] 177 12
names(world_coffee_nest)
# [1] "iso_a2" "name_long" "continent" "region_un" "subregion" "type" "area_km2"
# [8] "pop" "lifeExp" "gdpPercap" "geom" "coffee_data"
head(world_coffee_nest[, 10:12], 3)
# Simple feature collection with 3 features and 2 fields
# geometry type: MULTIPOLYGON
# dimension: XY
# bbox: xmin: -180 ymin: -18.28799 xmax: 180 ymax: 27.65643
# geographic CRS: WGS 84
# # A tibble: 3 x 3
# gdpPercap geom coffee_data
# <dbl> <MULTIPOLYGON [arc_degree]> <list>
# 1 8222. (((180 -16.06713, 180 -16.55522, 179.3641 -16.80135, 178.7251 -17.01204, 178.5968 ~ <tibble [0 x 2~
# 2 2402. (((33.90371 -0.95, 34.07262 -1.05982, 37.69869 -3.09699, 37.7669 -3.67712, 39.2022~ <tibble [1 x 2~
# 3 NA (((-8.66559 27.65643, -8.665124 27.58948, -8.6844 27.39574, -8.687294 25.88106, -1~ <tibble [0 x 2~
말로만 설명하면 잘 이해가 안될 듯 하여 아래에 nest_join(world, coffee_data) 된 테이블의 아웃풋을 화면 캡쳐하였습니다. nest join 된 후의 테이블에서 오른쪽의 "coffee_data" 라는 1개의 칼럼에 보면 list(coffee_proeuction_2016 = 81, coffee_proeuction_2017 = xx) 라고 해서 "coffee_data" 에 들어있는 2개의 칼럼이 1개의 리스트 형태의 칼럼에 중첩이 되어서 들어가 있음을 알 수 있습니다.
다음번 포스팅에서는 Join 했을 때 Join 의 기준이 되는 Key 값이 일부 표준화가 안되어서 제대로 Join 이 안될 경우에 정규 표현식(Regular expression)을 사용해서 Join 하는 방법(rfriend.tistory.com/626)을 소개하겠습니다.