[Python pandas] 결측값을 회귀모형 추정값으로 채우기 (fill missing values using prediction values of linear regression model)
Python 분석과 프로그래밍/Python 데이터 전처리 2021. 5. 5. 00:59이전 포스팅의 rfriend.tistory.com/262 에서는 Python pandas DataFrame의 결측값을 fillna() 메소드를 사용해서 특정 값으로 채우거나 평균으로 대체하는 방법을 소개하였습니다.
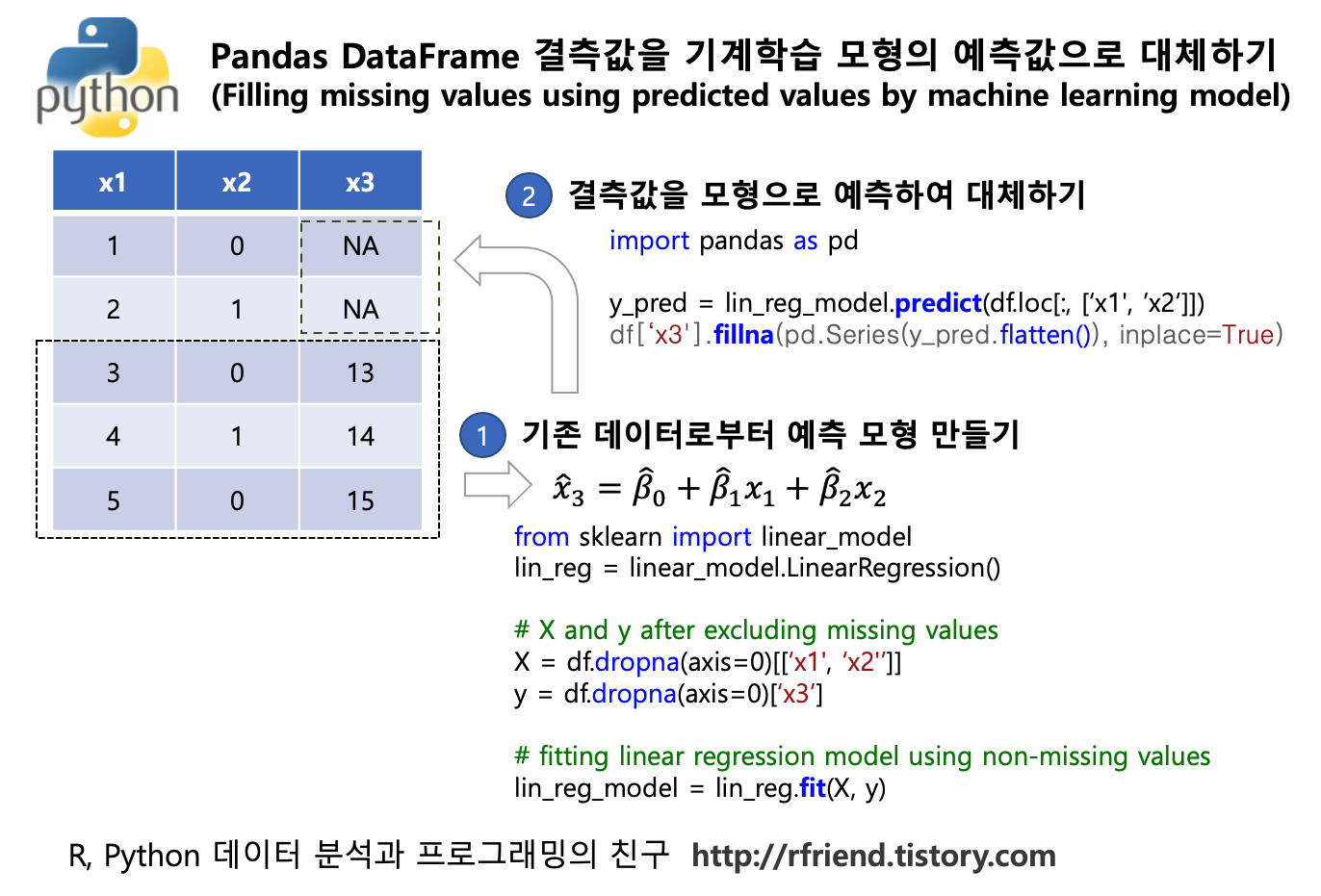
이번 포스팅에서는 Python pandas DataFrame 의 결측값을 선형회귀모형(linear regression model) 을 사용하여 예측/추정하여 채워넣는 방법을 소개하겠습니다. (물론, 아래의 동일한 방법을 사용하여 선형회귀모형 말고 다른 통계, 기계학습 모형을 사용하여 예측/추정한 값으로 대체할 수 있습니다.)
(1) 결측값을 제외한 데이터로부터 선형회귀모형 훈련하기
(training, fitting a linear regression model using non-missing values)
(2) 선형회귀모형으로 부터 추정값 계산하기 (prediction using linear regression model)
(3) pandas 의 fillna() 메소드 또는 numpy의 np.where() 메소드를 사용해서 결측값인 경우 선형회귀모형 추정값으로 대체하기 (filling missing values using the predicted values by linear regression model)
아래에는 예제로 사용할 데이터로 전복(abalone) 공개 데이터셋을 읽어와서 1행~3행의 'whole_weight' 칼럼 값을 결측값(NA) 으로 변환해주었습니다.
import pandas as pd
import numpy as np
# read abalone dataset from website
abalone = pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning-databases/abalone/abalone.data",
header=None,
names=['sex', 'length', 'diameter', 'height',
'whole_weight', 'shucked_weight',
'viscera_weight', 'shell_weight', 'rings'])
# get 10 observations as an example
df = abalone.copy()[:10]
# check missing values : no missing value at all
pd.isnull(df).sum()
# sex 0
# length 0
# diameter 0
# height 0
# whole_weight 0
# shucked_weight 0
# viscera_weight 0
# shell_weight 0
# rings 0
# dtype: int64
# insert NA values as an example
df.loc[0:2, 'whole_weight'] = np.nan
df
# sex length diameter height whole_weight shucked_weight viscera_weight shell_weight rings
# 0 M 0.455 0.365 0.095 NaN 0.2245 0.1010 0.150 15
# 1 M 0.350 0.265 0.090 NaN 0.0995 0.0485 0.070 7
# 2 F 0.530 0.420 0.135 NaN 0.2565 0.1415 0.210 9
# 3 M 0.440 0.365 0.125 0.5160 0.2155 0.1140 0.155 10
# 4 I 0.330 0.255 0.080 0.2050 0.0895 0.0395 0.055 7
# 5 I 0.425 0.300 0.095 0.3515 0.1410 0.0775 0.120 8
# 6 F 0.530 0.415 0.150 0.7775 0.2370 0.1415 0.330 20
# 7 F 0.545 0.425 0.125 0.7680 0.2940 0.1495 0.260 16
# 8 M 0.475 0.370 0.125 0.5095 0.2165 0.1125 0.165 9
# 9 F 0.550 0.440 0.150 0.8945 0.3145 0.1510 0.320 19
(1) 결측값을 제외한 데이터로부터 선형회귀모형 훈련하기 (training, fitting a linear regression model using non-missing values)
pandas 패키지의 dropna() 메소드를 이용해서 결측값이 포함된 행을 제거한 후의 설명변수 ' diameter', 'height', 'shell_weight' 를 'X' DataFrame 객체로 만들고, ' whole_weight' 를 종속변수 'y' Series로 만든 후에, sklearn의 linear_model.LinearRegression() 메소드로 lin_reg.fit(X, y) 로 선형회귀모형을 적합하였습니다.
# initiate sklearn's linear regression
from sklearn import linear_model
lin_reg = linear_model.LinearRegression()
# X and y after excluding missing values
X = df.dropna(axis=0)[['diameter', 'height', 'shell_weight']]
y = df.dropna(axis=0)['whole_weight']
# fitting linear regression model using non-missing values
lin_reg_model = lin_reg.fit(X, y)
(2) 선형회귀모형으로 부터 추정값 계산하기 (prediction using linear regression model)
위의 (1)번에서 적합한 모델에 predict() 함수를 사용해서 'whole_weight' 의 값을 추정하였습니다.
# Prediction
y_pred = lin_reg_model.predict(df.loc[:, ['diameter', 'height', 'shell_weight']])
y_pred
# array([0.54856977, 0.21868994, 0.69091523, 0.50734984, 0.19206521,
# 0.35618402, 0.80347213, 0.7804138 , 0.53164895, 0.85086606])
(3) pandas 의 fillna() 메소드 또는 numpy의 np.where() 메소드를 사용해서 결측값인 경우 선형회귀모형 추정값으로 대체하기 (filling missing values using the predicted values by linear regression model)
(방법 1) pandas 의 fillna() 메소드를 사용해서 'whole_weight' 값이 결측값인 경우에는 위의 (2)번에서 선형회귀모형을 이용해 추정한 값으로 대체를 합니다. 이때 'y_pred' 는 2D numpy array 형태이므로, 이를 flatten() 메소드를 사용해서 1D array 로 바꾸어주고, 이를 pd.Series() 메소드를 사용해서 Series 데이터 유형으로 변환을 해주었습니다. inplace=True 옵션을 사용해서 df DataFrame 내에서 결측값이 선형회귀모형 추정값으로 대체되고 나서 저장되도록 하였습니다.
(방법 2) numpy의 where() 메소드를 사용해서, 결측값인 경우 (즉, isnull() 이 True) pd.Series(y_pred.flatten()) 값을 가져옥, 결측값이 아닌 경우 기존 값을 가져와서 'whole_weight' 에 값을 할당하도록 하였습니다.
(방법 3) for loop 을 돌면서 매 행의 'whole_weight' 값이 결측값인지 여부를 확인 후, 만약 결측값이면 (isnull() 이 True 이면) 위의 (1)에서 적합된 회귀모형에 X값들을 넣어줘서 예측을 해서 결측값을 채워넣는 사용자 정의함수를 만들고 이를 apply() 함수로 적용하는 방법도 생각해볼 수는 있으나, 데이터 크기가 큰 경우 for loop 연산은 위의 (방법 1), (방법 2) 의 vectorized operation 대비 성능이 많이 뒤떨어지므로 소개는 생략합니다.
## filling missing values using predicted values by a linear regression model
## -- (방법 1) pd.fillna() methods
df['whole_weight'].fillna(pd.Series(y_pred.flatten()), inplace=True)
## -- (방법 2) np.where()
df['whole_weight'] = np.where(df['whole_weight'].isnull(),
pd.Series(y_pred.flatten()),
df['whole_weight'])
## results
df
# sex length diameter height whole_weight shucked_weight viscera_weight shell_weight rings
# 0 M 0.455 0.365 0.095 0.548570 0.2245 0.1010 0.150 15
# 1 M 0.350 0.265 0.090 0.218690 0.0995 0.0485 0.070 7
# 2 F 0.530 0.420 0.135 0.690915 0.2565 0.1415 0.210 9
# 3 M 0.440 0.365 0.125 0.516000 0.2155 0.1140 0.155 10
# 4 I 0.330 0.255 0.080 0.205000 0.0895 0.0395 0.055 7
# 5 I 0.425 0.300 0.095 0.351500 0.1410 0.0775 0.120 8
# 6 F 0.530 0.415 0.150 0.777500 0.2370 0.1415 0.330 20
# 7 F 0.545 0.425 0.125 0.768000 0.2940 0.1495 0.260 16
# 8 M 0.475 0.370 0.125 0.509500 0.2165 0.1125 0.165 9
# 9 F 0.550 0.440 0.150 0.894500 0.3145 0.1510 0.320 19
많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)




