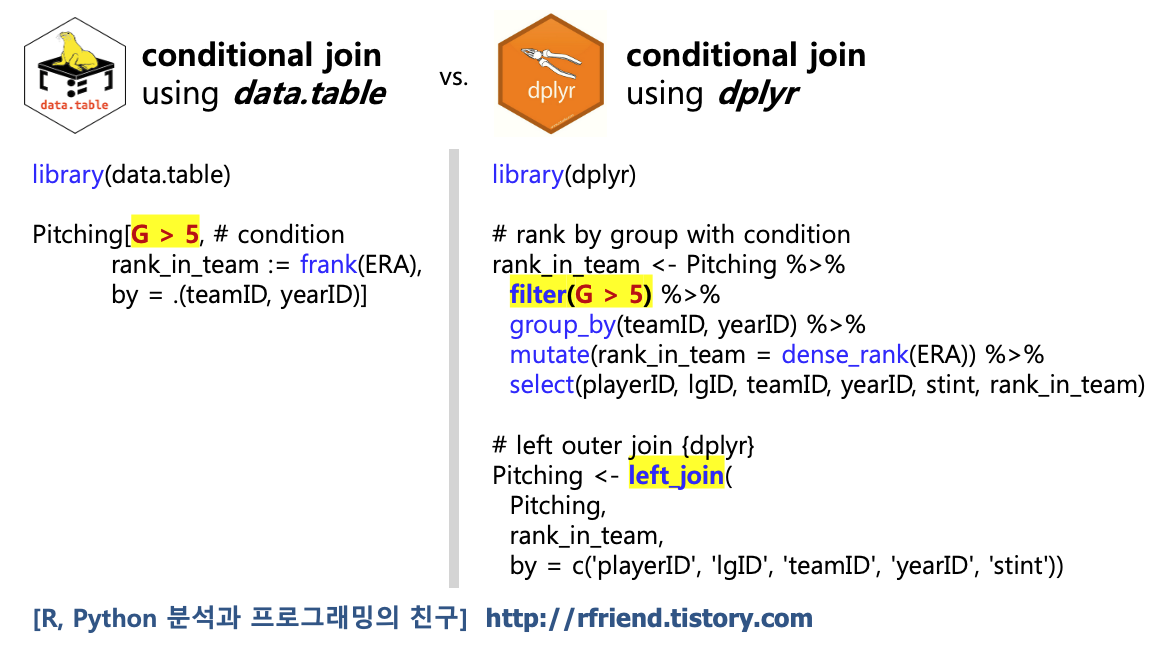
[R data.table] .SD[], by를 사용해 그룹별로 부분집합 가져오기 (Group Subsetting)
R 분석과 프로그래밍/R 데이터 전처리 2021. 1. 31. 23:58지난번 포스팅에서는 조건이 있는 상태에서 데이터셋 합치기(conditional joins) 방법을 소개하였습니다. (rfriend.tistory.com/610)
이번 포스팅에서는 .SD[]를 사용해서 그룹별로 부분집합을 가져오는 방법(Group Subsetting)을 소개하겠습니다.
(1) 그룹별로 정렬 후 마지막 행 가져오기 (subsetting the last row by groups)
(2) 그룹별로 정렬 후 첫번째 행 가져오기 (subsetting the first row by groups)
(3) 그룹별로 무작위로 행 하나 추출하기 (subsetting a row randomly by groups)

먼저, data.table 패키지를 불러오고, 예제로 사용할 데이터로 Lahman 패키지에 들어있는 야구 팀들의 통계 데이터인 'Teams' 데이터셋을 DataTable로 불러오겠습니다.
## ===============================
## R data.table
## : Grouped .SD operations
## ===============================
library(data.table)
## Lahman database on baseball
#install.packages("Lahman")
library(Lahman)
data("Teams")
# coerce lists and data.frame to data.table by reference
setDT(Teams)
str(Teams)
# Classes 'data.table' and 'data.frame': 2925 obs. of 48 variables:
# $ yearID : int 1871 1871 1871 1871 1871 1871 1871 1871 1871 1872 ...
# $ lgID : Factor w/ 7 levels "AA","AL","FL",..: 4 4 4 4 4 4 4 4 4 4 ...
# $ teamID : Factor w/ 149 levels "ALT","ANA","ARI",..: 24 31 39 56 90 97 111 136 142 8 ...
# $ franchID : Factor w/ 120 levels "ALT","ANA","ARI",..: 13 36 25 56 70 85 91 109 77 9 ...
# $ divID : chr NA NA NA NA ...
# $ Rank : int 3 2 8 7 5 1 9 6 4 2 ...
# $ G : int 31 28 29 19 33 28 25 29 32 58 ...
# $ Ghome : int NA NA NA NA NA NA NA NA NA NA ...
# $ W : int 20 19 10 7 16 21 4 13 15 35 ...
# $ L : int 10 9 19 12 17 7 21 15 15 19 ...
# $ DivWin : chr NA NA NA NA ...
# $ WCWin : chr NA NA NA NA ...
# $ LgWin : chr "N" "N" "N" "N" ...
# $ WSWin : chr NA NA NA NA ...
# $ R : int 401 302 249 137 302 376 231 351 310 617 ...
# $ AB : int 1372 1196 1186 746 1404 1281 1036 1248 1353 2571 ...
# $ H : int 426 323 328 178 403 410 274 384 375 753 ...
# $ X2B : int 70 52 35 19 43 66 44 51 54 106 ...
# $ X3B : int 37 21 40 8 21 27 25 34 26 31 ...
# $ HR : int 3 10 7 2 1 9 3 6 6 14 ...
# $ BB : int 60 60 26 33 33 46 38 49 48 29 ...
# $ SO : int 19 22 25 9 15 23 30 19 13 28 ...
# $ SB : int 73 69 18 16 46 56 53 62 48 53 ...
# $ CS : int 16 21 8 4 15 12 10 24 13 18 ...
# $ HBP : int NA NA NA NA NA NA NA NA NA NA ...
# $ SF : int NA NA NA NA NA NA NA NA NA NA ...
# $ RA : int 303 241 341 243 313 266 287 362 303 434 ...
# $ ER : int 109 77 116 97 121 137 108 153 137 166 ...
# $ ERA : num 3.55 2.76 4.11 5.17 3.72 4.95 4.3 5.51 4.37 2.9 ...
# $ CG : int 22 25 23 19 32 27 23 28 32 48 ...
# $ SHO : int 1 0 0 1 1 0 1 0 0 1 ...
# $ SV : int 3 1 0 0 0 0 0 0 0 1 ...
# $ IPouts : int 828 753 762 507 879 747 678 750 846 1548 ...
# $ HA : int 367 308 346 261 373 329 315 431 371 573 ...
# $ HRA : int 2 6 13 5 7 3 3 4 4 3 ...
# $ BBA : int 42 28 53 21 42 53 34 75 45 63 ...
# $ SOA : int 23 22 34 17 22 16 16 12 13 77 ...
# $ E : int 243 229 234 163 235 194 220 198 218 432 ...
# $ DP : int 24 16 15 8 14 13 14 22 20 22 ...
# $ FP : num 0.834 0.829 0.818 0.803 0.84 0.845 0.821 0.845 0.85 0.83 ...
# $ name : chr "Boston Red Stockings" "Chicago White Stockings" "Cleveland Forest Citys" "Fort Wayne Kekiongas" ...
# $ park : chr "South End Grounds I" "Union Base-Ball Grounds" "National Association Grounds" "Hamilton Field" ...
# $ attendance : int NA NA NA NA NA NA NA NA NA NA ...
# $ BPF : int 103 104 96 101 90 102 97 101 94 106 ...
# $ PPF : int 98 102 100 107 88 98 99 100 98 102 ...
# $ teamIDBR : chr "BOS" "CHI" "CLE" "KEK" ...
# $ teamIDlahman45: chr "BS1" "CH1" "CL1" "FW1" ...
# $ teamIDretro : chr "BS1" "CH1" "CL1" "FW1" ...
# - attr(*, ".internal.selfref")=<externalptr>
(1) 그룹별로 정렬 후 마지막 행 가져오기
(subsetting the last row by groups)
년도를 기준으로 내림차순 정렬(order(yearID))을 한 상태에서, 'teamID' 그룹 별(by = teamID)로 마지막 행을 부분집합으로 가져오기(.SD[.N])를 해보겠습니다.
.SD는 data.table 그 자체를 참조해서 가져오는 것을 의미하며, .SD[.N] 에서 .N 은 행의 개수(Number of rows)를 의미하므로, .SD[.N] 는 (각 'teamID' 그룹별로, by = teamID) 행의 개수 위치의 값, 즉 (teamID 그룹별) 마지막 행의 값을 부분집합으로 가져오게 됩니다.
.SDcols 는 특정 칼럼만 선별해서 가져올 때 사용하는데요, 칼럼이 너무 많아서 ID들과 순위(Rank), 경기 수(G), 승리(W), 패배(L) 칼럼만 가져오라고 했습니다.
## (1) getting the most recent season of data for each team in the Lahman data.
## In the case of grouping, .SD is multiple in nature
## – it refers to each of these sub-data.tables, one-at-a-time
library(data.table)
Teams[order(yearID) # the data is sorted by year
, .SD[.N] # the recent (last row) season of data for each team
, .SDcols = c('teamID', 'yearID', 'lgID', 'franchID', 'divID', 'Rank', 'G', 'W', 'L')
, by = teamID] # subsetting by teamID groups
# teamID teamID yearID lgID franchID divID Rank G W L
# 1: BS1 BS1 1875 NA BNA <NA> 1 82 71 8
# 2: CH1 CH1 1871 NA CNA <NA> 2 28 19 9
# 3: CL1 CL1 1872 NA CFC <NA> 7 22 6 16
# 4: FW1 FW1 1871 NA KEK <NA> 7 19 7 12
# 5: NY2 NY2 1875 NA NNA <NA> 6 71 30 38
# ---
# 145: ANA ANA 2004 AL ANA W 1 162 92 70
# 146: ARI ARI 2019 NL ARI W 2 162 85 77
# 147: MIL MIL 2019 NL MIL C 2 162 89 73
# 148: TBA TBA 2019 AL TBD E 2 162 96 66
# 149: MIA MIA 2019 NL FLA E 5 162 57 105
위의 (1)번과 동일한 과업을 dplyr 패키지로 수행하면 아래와 같습니다. (가장 최근의 값을 가져오기 위해 dplyr에서는 내림차순으로 정렬한 후 첫번째 행을 가져왔습니다. (= 오름차순 정렬 후 마지막 행을 가져오는 것과 동일))
## -- using dplyr
## getting the last row for each teamID group
library(dplyr)
Teams %>%
group_by(teamID) %>%
arrange(desc(yearID)) %>%
slice(1L) %>%
select(teamID, yearID, lgID, franchID, divID, Rank, G, W, L)
# # A tibble: 149 x 9
# # Groups: teamID [149]
# teamID yearID lgID franchID divID Rank G W L
# <fct> <int> <fct> <fct> <chr> <int> <int> <int> <int>
# 1 ALT 1884 UA ALT NA 10 25 6 19
# 2 ANA 2004 AL ANA W 1 162 92 70
# 3 ARI 2019 NL ARI W 2 162 85 77
# 4 ATL 2019 NL ATL E 1 162 97 65
# 5 BAL 2019 AL BAL E 5 162 54 108
# 6 BFN 1885 NL BUF NA 7 112 38 74
# 7 BFP 1890 PL BFB NA 8 134 36 96
# 8 BL1 1874 NA BLC NA 8 47 9 38
# 9 BL2 1889 AA BLO NA 5 139 70 65
# 10 BL3 1891 AA BLO NA 4 139 71 64
(2) 그룹별로 정렬 후 첫번째 행 가져오기
(subsetting the first row by groups)
이번에는 년도별로 내림차순으로 정렬(order(yearID)을 한 상태에서, 'teamID' 그룹별(by = teamID)로 첫번째 행의 값을 부분집합으로 가져오기(.SD[1L])를 해보겠습니다.
.SD[1L] 에서 .SD는 (teamID 그룹별로, by=teamID) data.table 그 자체를 참조하며, '[1L]' 은 첫번째 행(1st Line)의 위치의 값을 indexing해서 가져오라는 뜻입니다.
## (2) getting the first season of data for each team in the Lahman data.
Teams[order(yearID) # the data is sorted by year
, .SD[1L] # the first season of data for each team
, .SDcols = c('teamID', 'yearID', 'lgID', 'franchID', 'divID', 'Rank', 'G', 'W', 'L')
, by = teamID] # subsetting by teamID groups
# teamID teamID yearID lgID franchID divID Rank G W L
# 1: BS1 BS1 1871 NA BNA <NA> 3 31 20 10
# 2: CH1 CH1 1871 NA CNA <NA> 2 28 19 9
# 3: CL1 CL1 1871 NA CFC <NA> 8 29 10 19
# 4: FW1 FW1 1871 NA KEK <NA> 7 19 7 12
# 5: NY2 NY2 1871 NA NNA <NA> 5 33 16 17
# ---
# 145: ANA ANA 1997 AL ANA W 2 162 84 78
# 146: ARI ARI 1998 NL ARI W 5 162 65 97
# 147: MIL MIL 1998 NL MIL C 5 162 74 88
# 148: TBA TBA 1998 AL TBD E 5 162 63 99
# 149: MIA MIA 2012 NL FLA E 5 162 69 93
(3) 그룹별로 무작위로 행 하나 추출하기
(subsetting a row randomly by groups)
마지막으로 년도를 기준으로 내림차순 정렬한 상태(order(yearID))에서, 'teamID' 그룹별로 (by = teamID) 무작위로 1개의 행을 부분집합으로 가져오기(.SD[sample(.N, 1L)])를 해보겠습니다.
.SD 는 (여기서는 teamID 그룹별로, by = teamID) data.table 그 자체를 참조하며, .SD[sample(.N, 1L)] 에서 sample(.N, 1L) 은 (teamID 그룹별) 총 행의 개수(.N) 중에서 1개의 행(1L)을 무작위로 추출(random sampling)해서 가져오라는 의미입니다.
## (3) getting a random row for each group.
Teams[order(yearID) # the data is sorted by year
, .SD[sample(.N, 1L)], # one random row of data for each team
, .SDcols = c('teamID', 'yearID', 'lgID', 'franchID', 'divID', 'Rank', 'G', 'W', 'L'),
, by = teamID] # subsetting by teamID groups
# teamID teamID yearID lgID franchID divID Rank G W L
# 1: BS1 BS1 1872 NA BNA <NA> 1 48 39 8
# 2: CH1 CH1 1871 NA CNA <NA> 2 28 19 9
# 3: CL1 CL1 1872 NA CFC <NA> 7 22 6 16
# 4: FW1 FW1 1871 NA KEK <NA> 7 19 7 12
# 5: NY2 NY2 1872 NA NNA <NA> 3 56 34 20
# ---
# 145: ANA ANA 2003 AL ANA W 3 162 77 85
# 146: ARI ARI 2012 NL ARI W 3 162 81 81
# 147: MIL MIL 2007 NL MIL C 2 162 83 79
# 148: TBA TBA 2005 AL TBD E 5 162 67 95
# 149: MIA MIA 2017 NL FLA E 2 162 77 85
[ Reference ]
* R data.table vignettes 'Using .SD for Data Analysis'
: cran.r-project.org/web/packages/data.table/vignettes/datatable-sd-usage.html
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요. :-)

728x90
반응형