[PyTorch] 텐서의 인덱싱과 슬라이싱 (indexing & slicing of PyTorch tensor)
Deep Learning (TF, Keras, PyTorch)/PyTorch basics 2023. 2. 19. 23:52이번 포스팅에서는 PyTorch 에서 인덱싱(indexing)과 슬라이싱(slicing)을 이용해서 텐서 내 원하는 위치의 원소 부분집합을 가져오는 방법을 소개하겠습니다. PyTorch 로 딥러닝을 할 때 인풋으로 사용하는 데이테셋이 다차원의 행렬인 텐서인데요, 인덱싱과 슬라이싱을 자주 사용하기도 하고, 또 차원이 많아질 수록 헷갈리기도 하므로 정확하게 익혀놓을 필요가 있습니다. NumPy의 인덱싱, 슬라이싱을 이미 알고 있으면 그리 어렵지 않습니다.
(1) 파이토치 텐서 인덱싱 (indexing of PyTorch tensor)
(2) 파이토치 텐서 슬라이싱 (slicing of PyTorch tensor)
(3) 1개 값만 가지는 파이토치 텐서에서 숫자 가져오기 : tensor.item()
(4) 파이토치 텐서 재구조화 (reshape)

(1) 파이토치 텐서 인덱싱 (indexing of PyTorch tensor)
먼저, 예제로 사용할 PyTorch tensor를 NumPy ndarray를 변환해서 만들어보겠습니다.
torch.Size([3, 5]) 의 형태를 가진 텐서를 만들었습니다.
import torch
import numpy as np
## -- creating a tensor object
x = torch.tensor(
np.arange(15).reshape(3, 5))
print(x)
# tensor([[ 0, 1, 2, 3, 4],
# [ 5, 6, 7, 8, 9],
# [10, 11, 12, 13, 14]])
## -- shape, size of a tensor
x.shape
# torch.Size([3, 5])
x.size(0)
# 3
x.size(1)
# 5
다양한 인덱싱 시나리오별로 예를 들어서 설명을 해보겠습니다.
(1-1) 1번 행 전체를 인덱싱 해오기
## indexing using position number
x[1] # or equivalently x[1, :]
# tensor([5, 6, 7, 8, 9])
(1-2) 1번 행, 2번 열 원소 인덱싱 해오기
x[1, 2]
# tensor(7)
(1-3) 1번 열 전체를 인덱싱 해오기
x[:, 1]
# tensor([ 1, 6, 11])
(1-4) 1번 열, 블리언(Boolean) True 인 행만 인덱싱 해오기
## indexing using Boolean
x[1][[True, False, False, False, True]]
# tensor([5, 9])
(1-5) 1번 열, 텐서(tensor)의 값의 행만 인덱싱 해오기
## indexing using a tensor
x[1][torch.tensor([1, 3])]
# tensor([6,8])
(1-6) 1번 열을 가져오되, 행은 리스트의 위치 값 순서대로 바꾸어서 가져오기
## changing the position using indexing
x[1, [4,3,0,1,2]]
# tensor([9, 8, 5, 6, 7])
(1-7) 행 별로 열의 위치를 달리해서 값 가져오기
(예) 0번 행의 4번 열, 1번 행은 3번 열, 2번 행은 2번 열의 값 가져오기
## 행별로 인덱싱할 위치를 바뀌가면서 인덱싱하기
x[torch.arange(x.size(0)), [4,3,2]]
# tensor([ 4, 8, 12])
(1-8) 전체 행의 마지막 열(-1) 값 가져오기
## -1 : last elements
x[:, -1]
# tensor([ 4, 9, 14])
(1-9) 인덱싱한 위치에 특정 값을 재할당 하기
(예) 1번 행에 값 '0'을 재할당하기
## asinging new value using indexing
x[1] = 0
print(x)
# tensor([[ 0, 1, 2, 3, 4],
# [ 0, 0, 0, 0, 0], <----- '0' 으로 재할당 됨
# [10, 11, 12, 13, 14]])
(2) 파이토치 텐서 슬라이싱 (slicing of PyTorch tensor)
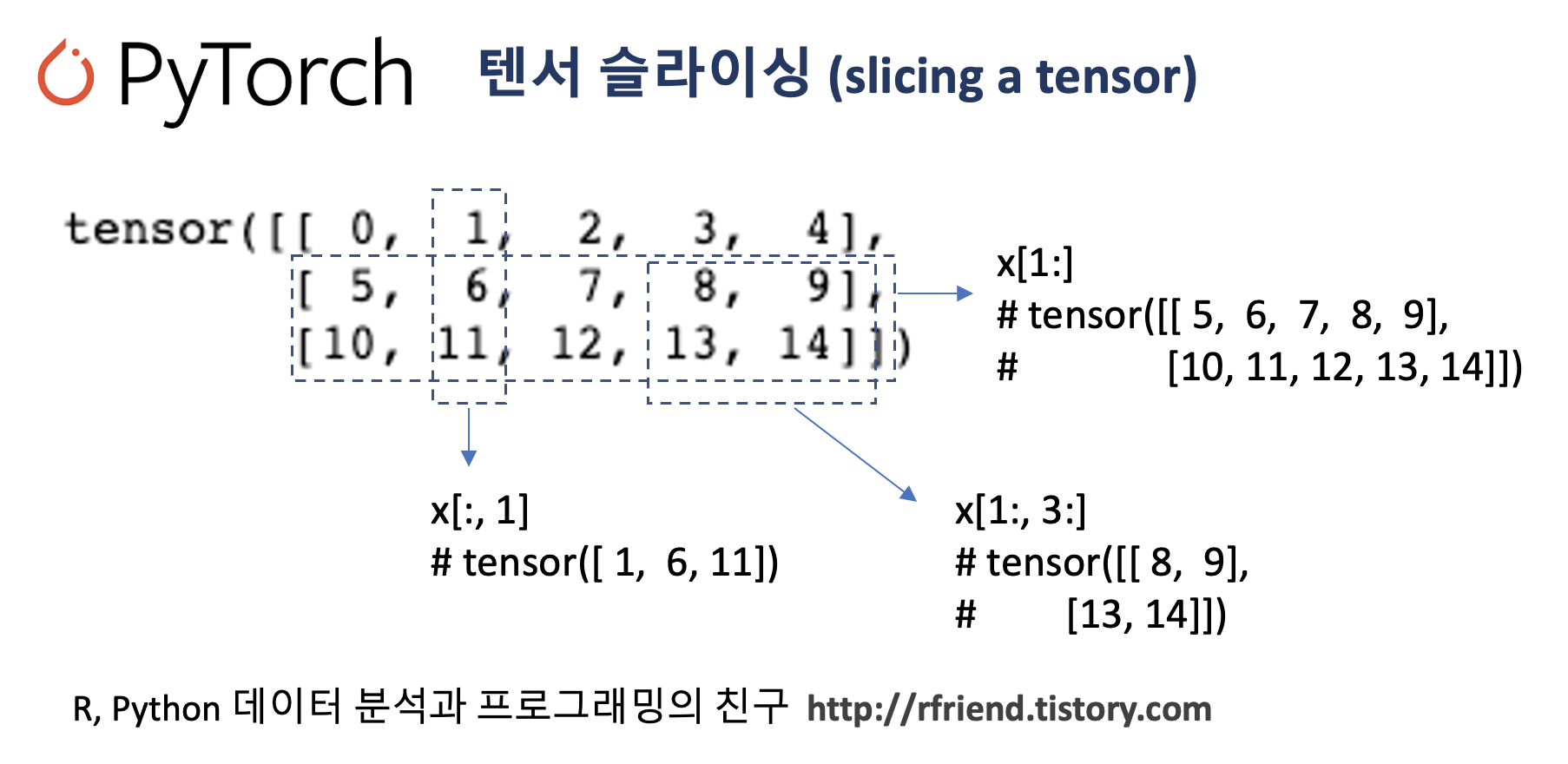
(2-1) 1번 행 이후의 행의 모든 값 가져오기
x = torch.tensor(
np.arange(15).reshape(3, 5))
print(x)
# tensor([[ 0, 1, 2, 3, 4],
# [ 5, 6, 7, 8, 9],
# [10, 11, 12, 13, 14]])
## -- slicing
x[1:]
# tensor([[ 5, 6, 7, 8, 9],
# [10, 11, 12, 13, 14]])
(2-2) 1번 행 이후의 행 & 3번 열 이후의 열의 모든 값 가져오기
x[1:, 3:]
# tensor([[ 8, 9],
# [13, 14]])
(2-3) 전체 행, 1번 열의 값 가져오기
x[:, 1]
# tensor([ 1, 6, 11])
(2-4) 1번 행, 전체 열의 값 가져오기
x[1, :] # or equivalently x[1]
# tensor([5, 6, 7, 8, 9])
(2-5) 1번 행의, 1번과 4번 행의 값 가져오기
(생소한 코드예요. ^^;)
## tensor[1::3] ==> (1, None, None, 4)
x[1][1::3]
# tensor([6, 9])
(3) 1개 값만 가지는 파이토치 텐서에서 숫자 가져오기 : tensor.item()
## torch.tensor.item()
## : get a Python number from a tensor containing a single vlaue
y = torch.tensor([[5]])
print(y)
# tensor([[5]])
y.item()
# 5
만약 PyTorch tensor가 1개의 값(즉, 스칼라) 만을 가지는 것이 아니라 여러개의 값을 가지는 경우, tensor.item() 메소드를 사용하면 ValueError: only one element tensors can be converted to Python scalars 가 발생합니다.
## ValueError
x.item()
# ValueError Traceback (most recent call last)
# <ipython-input-74-3396a1b2b617> in <module>
# ----> 1 x.item()
# ValueError: only one element tensors can be converted to Python scalars
(4) 파이토치 텐서 재구조화 (reshape)
NumPy의 reshape() 메소드와 동일하게 PyTorch tensor 도 reshape() 메소드를 이용해서 형태(shape)를 재구조화할 수 있습니다.
torch.tensor([[0, 1, 2, 3, 4, 5]])
# tensor([[0, 1, 2, 3, 4, 5]])
## -- reshape
torch.tensor([[0, 1, 2, 3, 4, 5]]).reshape(2, 3)
# tensor([[0, 1, 2],
# [3, 4, 5]])
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)

'Deep Learning (TF, Keras, PyTorch) > PyTorch basics' 카테고리의 다른 글
| [PyTorch] 텐서 나누기 (splitting a PyTorch tensor into multiple tensors) (0) | 2023.02.23 |
|---|---|
| [PyTorch] 텐서 합치기 (concat, stack) (0) | 2023.02.21 |
| [PyTorch] NumPy의 array 대비 PyTorch 의 성능 비교 (0) | 2023.02.19 |
| [PyTorch] 난수를 생성해서 텐서 만들기 (generating a tensor with random numbers) (0) | 2023.02.12 |
| [PyTorch] 텐서 객체 만들기 (PyTorch tensor objects) (0) | 2023.02.05 |