이번 포스팅에서는 R의 DataFrame에서 특정 조건에 해당하는 값의 행과, 해당 행의 앞, 뒤 2개 행(above and below 2 rows) 을 동시에 제거하는 방법을 소개하겠습니다.
예를 들어서, 아래와 같이 var1, var2의 두 개의 변수를 가지는 df라는 이름의 DataFrame이 있다고 했을 때, var2의 값 중 음수(-)인 값을 가지는 행과, 해당 행의 위, 아래 2개 행을 같이 제거(remove, filter) 해서 df2 라는 이름의 새로운 DataFrame을 만들어보겠습니다.
다음으로 칼럼 var2의 값이 음수(-)인 값의 위치를 기준으로 해당 값의 행과 앞, 뒤 2개행까지는 제거(remove, filter)하고, 그 외의 값은 유지(keep_idx = TRUE) 하는 keep_idx 라는 벡터를 for loop 반복문과 if 조건문을 사용해서 만들어보겠습니다.
이제 df라는 DataFrame에서 위에서 구한 keep_idx = TRUE 인 행만 indexing 해서 (즉, keep_idx = FALSE 인 행은 제거) 새로운 df2 라는 DataFrame을 만들어보겠습니다.
> # subset only rows with keep_idx = TRUE
> df_filstered <- df[keep_idx, ]
> df_filstered
var1 var2
5 5 50
6 6 300
12 12 80
위는 예는 조건문과 반복문을 사용해서 indexing 해오는 방법이었구요, windows 함수인 lag(), lead()를 사용해서도 동일한 기능을 수행하는 프로그램을 짤 수도 있습니다. 다만, 이번 포스팅에서 소개한 코드가 좀더 범용적이고 코드도 짧기 때문에 lag(), lead() 함수를 사용한 방법은 추가 설명은 하지 않겠습니다.
'0'이 연속 세번 나오는 구간을 노란색으로 표시를 했습니다. 이 구간을 기준으로 원래의 벡터를 구분해서 나눈 후에(split), 각각을 새로운 벡터로 생성하여 분리해주는 프로그램을 짜보는 것이 이번 포스팅의 주제입니다.
아래에 wihle() 반복문, if(), else if() 조건문, assign() 함수를 사용해서 위의 요건을 수행하는 코드를 짜보았습니다. 원래 벡터에서 제일 왼쪽에 있는 숫자가 '0'이 아니면 하나씩 빼서 빈 벡터에 차곡차곡 쌓아 놓구요, '0'이 3개 나란히 있는 '000'이 나타나면 그동안 쌓아두었던 벡터를 잘라내서 다른 이름의 벡터로 저장하고, '000'도 그 다음 이름의 벡터로 저장하면서 원래 벡터에서 '000'을 빼놓도록 하는 반복문입니다. assign() 함수는 저장하는 객체의 이름에 paste()를 사용해서 변화하는 숫자를 붙여주고자 할 때 사용하는 함수인데요, 자세한 사용법 예제는 여기(=> http://rfriend.tistory.com/108)를 참고하세요.
아래 프로그램에서 'bin_range'에 할당하는 숫자를 변경하면 원하는 회수만큼 '0'이 반복되었을 때 구간을 분할하도록 조정할 수 있습니다. 가령, '0'이 연속 10번 나오면 분할하고 싶으면 bin_range <- 10 이라고 할당해주면 됩니다.
아래의 코드는 페이스북 R User Group의 회원이신 June Young Lee 님께서 data.table 라이브러리를 사용해서 짜신 것입니다. 코드도 간결할 뿐만 아니라, 위에 제가 짠 코드보다 월등히 빠른 실행속도를 자랑합니다. 대용량 데이터를 빠른 속도로 조작, 처리하려면 data.table 만한게 없지요. 아래 코드는 저도 공부하려고 옮겨 놓았습니다.
똑같은 일을 하는데 있어서도 누가 어떤 로직으로 무슨 패키지, 함수를 사용해서 짜느냐에 따라서 복잡도나 연산속도가 이렇게 크게 차이가 날 수 있구나 하는 좋은 예제가 될 것 같습니다. 이런게 프로그래밍의 묘미이겠지요? ^^ June Young Lee 님께 엄지척! ^^b
아래의 예제와 같이 콤마로 구분되어 있는 문자형 변수(caracter variable with comma seperator delimiter)를 가진 데이터 프레임이 있다고 합시다.
두번째의 item 변수에 콤마로 구분되어 들어있는 다수의 항목들을 구분자 콤마(',')를 기준으로 분리(split)한 후에 => 이를 동일한 name을 key로 해서 세로로 주욱~ 늘여서 재구조화하여야 할 필요가 생겼다고 합시다.
데이터 구조변환의 전/후 모습을 말로 설명하려니 좀 어려운데요, 아래의 'Before (original dataset) => After (transformation)' 의 그림을 참고하시기 바랍니다.
이걸 R로 하는 방법을 소개합니다.
먼저 위의 Before 모양으로 간단한 데이터 프레임을 만들어보았습니다.
##-------------------------------------------------------- ## splitting character of dataframe and reshaping dataset ##--------------------------------------------------------
(7) item_index_split_temp <- data.frame(strsplit(item_index, split = ',')) : (6)번에서 i번째 행별로 indexing해 온 item을 구분자 'comma (',')'를 기준으로 문자열을 분리(split)한 후에, 이것을 데이터 프레임으로 생성합니다.
(8) mart_temp <- data.frame(cbind(name_index, item_index_split_temp)) : (5)번과 (7)번 결과물을 cbind()로 묶은 후에, 이것을 데이터 프레임으로 생성합니다. cbind()로 결합할 때 name은 1개인데 item이 2개 이상일 경우에는 1개밖에 없는 name이 자동으로 반복으로 item의 개수만큼 재할당이 됩니다.
(9) names(mart_temp) <- c("name", "item") : mart_temp의 변수 이름을 첫번째 변수는 "name", 두번째 변수는 "item"으로 지정해줍니다.
> mart_new
name item
1: John Apple
2: John Banana
3: John Mango
4: Jane Banana
5: Jane Kiwi
6: Jane Tomato
7: Jane Mango
8: Tom Apple
9: Tom Tomato
10: Tom Cherry
11: Tom Milk
12: Tom IceCream
Ashtray 님께서 댓글로 남겨주신 R script를 여러 사람이 좀더 쉽게 널리 공유할 수 있도록 아래에 공유합니다 (Ashtray님, R script 공유해주셔서 감사합니다. ^^).
구분자가 "\\^"를 기준으로 문자열을 분리하고, for loop 문을 사용해서 세로로 세워서 재구조화하는 절차는 같습니다. 대신 변수 개수가 다르다보니 for loop문이 조금 다르구요, data table이 아니라 list()를 사용했다는점도 다릅니다.
R script 짜다보면, 그리고 다른 분께서 R script 짜놓은것을 보면 "동일한 input과 동일한 output이지만 가운데 process는 방법이 단 한가지만 있는게 아니구나" 하고 저도 배우게 됩니다.
결론 먼저 말씀드리면, data.table package의 rbindlist(data) 함수가 속도 면에서 월등히 빠르네요.
[ R로 여러개의 데이터프레임을 한꺼번에 하나의 데이터프레임으로 묶기 ]
0) 문제 (The problem)
아래처럼 3개의 칼럼으로 구성된 100,000 개의 자잘한 데이터 프레임을 한개의 커다란 데이터 프레임으로 합치는 것이 풀어야 할 문제, 미션입니다.
data = list() 로 해서 전체 데이터 프레임들을 data라는 리스트로 만들어서 아래 각 방법별 예제에 사용하였습니다.
> ###########################################
> ## Concatenating a list of data frames
> ## do.call(rbind, data)
> ## ldply(data, rbind)
> ## rbind.fill(data)
> ## rbindlist(data) ** winner! **
> ###########################################
> > ## The Problem
> > data = list()
> > N = 100000
> > for (n in 1:N) {
+ data[[n]] = data.frame(index = n,
+ char = sample(letters, 1),
+ z = runif(1))
+ }
> > data[[1]]
index char z
1 1 j 0.2300154
1) The navie solution : do.call(rbind, data)
가장 쉽게 생각할 수 있는 방법으로 base package에 포함되어 있는 rbind() 함수를 do.call 함수로 계속 호출해서 여러개의 데이터 프레임을 위/아래로 합치는 방법입니다.
이거 한번 돌리니 정말 시간 오래 걸리네요. @@~ 낮잠 잠깐 자고 와도 될 정도로요.
> ## (1) The Naive Solution
> head(do.call(rbind, data))
index char z
1 1 j 0.23001541
2 2 f 0.63555284
3 3 d 0.65774397
4 4 y 0.46550511
5 5 b 0.02688307
6 6 u 0.19057217
2-1) plyr package : ldply(data, rbind)
두번째 방법은 plyr package의 ldply(data, rbind) 함수를 사용하는 방법입니다.
> ## (2) Alternative Solutions #1 and #2
> ## (2-1) plyr package : ldply(data, rbind)
> install.packages("plyr")
> library(plyr)
> head(ldply(data, rbind))
index char z
1 1 j 0.23001541
2 2 f 0.63555284
3 3 d 0.65774397
4 4 y 0.46550511
5 5 b 0.02688307
6 6 u 0.19057217
2-2) plyr package : rbind.fill(data)
세번째 방법은 plyr package의 rbind.fill(data) 함수를 사용하는 방법입니다. 결과는 앞의 두 방법과 동일함을 알 수 있습니다.
> ## (2-2) plyr package : rbind.fill(data)
> library(plyr)
> head(rbind.fill(data))
index char z
1 1 j 0.23001541
2 2 f 0.63555284
3 3 d 0.65774397
4 4 y 0.46550511
5 5 b 0.02688307
6 6 u 0.19057217
3) data.table package : rbindlist(data)
마지막 방법은 data.table package의 rbindlist(data) 함수를 사용하는 방법입니다.
패키지/함수별 성능 비교를 해본 결과 data.table 패키지의 rbindlist(data) 함수가 월등히 빠르다는 것을 알 수 있습니다. 위의 벤치마킹 결과를 보면, 속도가 가장 빨랐던 rbindlist(data)를 1로 놨을 때, 상대적인 속도(relative 칼럼)를 보면 rbind.fill(data)가 86.932로서 rbindlist(data)보다 86배 더 오래걸리고, ldply(data, rbind)가 292.644로서 rbindlist(data)보다 292배 더 오래걸린다는 뜻입니다. do.call(rbind, data)는 rbindlist(data) 보다 상대적으로 668.692배 더 시간이 걸리는 것으로 나오네요.
rbindlist(data)가 훨등히 속도가 빠른 이유는 두가지인데요,
(1) rbind() 함수가 각 데이터 프레임의 칼럼 이름을 확인하고, 칼럼 이름이 다를 경우 재정렬해서 합치는데 반해, data.table 패키지의 rbindlist() 함수는 각 데이터 프레임의 칼럼 이름을 확인하지 않고 단지 위치(position)를 기준으로 그냥 합쳐버리기 때문이며,
(따라서, rbindlist() 함수를 사용하려면 각 데이터 프레임의 칼럼 위치가 서로 동일해야 함)
(2) rbind() 함수는 R code로 작성된 반면에, data.table 패키지의 rbindlist() 는 C 언어로 코딩이 되어있기 때문입니다.
아래의 화면캡쳐 예시처럼 MyDocuments > R > FILES 폴더 아래에 daily로 쪼개진 10개의 text 파일들이 들어있다고 해봅시다. (10개 정도야 일일이 불어올 수도 있겠지만, 100개, 1,000개 파일이 들어있다면?)
(1) 폴더 경로 객체로 만들기
## cleaning up environment
rm(list=ls())
## making directory as an object
src_dir <- c("C:/Users/Owner/Documents/R/FILES") # 경로 구분 : '\'를 '/'로 바꿔야 함
src_dir
#[1] "C:/Users/Owner/Documents/R/FILES"
(2) 폴더 내 파일들 이름을 list-up 하여 객체로 만들기 : list.files()
# listing up name of files in the directory => object
src_file <- list.files(src_dir) # list
src_file
#[1] "day_20160701.txt" "day_20160702.txt" "day_20160703.txt" "day_20160704.txt"
#[5] "day_20160705.txt" "day_20160706.txt" "day_20160707.txt" "day_20160708.txt"
#[9] "day_20160709.txt" "day_20160710.txt"
"C:/Users/Owner/Documents/R/FILES" 디렉토리에 들어있는 파일들을 열어보면 아래와 같은 데이터들이 들어있습니다. (가상으로 만들어 본 것임) daily로 집계한 데이터들이 들어있네요.
(3) 파일 개수 객체로 만들기 : length(list)
# counting number of files in the directory => object
src_file_cnt <- length(src_file)
src_file_cnt
#[1] 10
여기까지 R을 실행하면 아래와 같이 environment 창에 객체들이 생겼음을 확인할 수 있습니다.
(4) 폴더 내 파일들을 LOOP 돌려서 불러오기 => (5) 파일을 내보내면서 합치기 : write.table(dataset, APPEND = TRUE)
: for(i in 1:src_file_cnt) {read.table() write.table(dataset, append = TRUE)}
## write.table one by one automatiically, using loop program
for(i in 1:src_file_cnt) {
# write.table one by one automatiically, using loop program
dataset <- read.table(
paste(src_dir, "/", src_file[i], sep=""),
sep=",",
header=F,
stringsAsFactors = F)
# dataset exporting with 'APPEND = TREU' option, filename = dataset_all.txt
write.table(dataset,
paste(src_dir, "/", "dataset_all.txt", sep=""),
sep = ",",
row.names = FALSE,
col.names = FALSE,
quote = FALSE,
append = TRUE) # appending dataset (stacking)
# delete seperate datasets
rm(dataset)
# printing loop sequence at console to check loop status
print(i)
}
#[1] 1
#[1] 2
#[1] 3
#[1] 4
#[1] 5
#[1] 6
#[1] 7
#[1] 8
#[1] 9
#[1] 10
여기까지 실행을 하면 아래처럼 MyDocuments>R>FILES 폴더 아래에 'dataset_all.txt' 라는 새로운 텍스트 파일이 하나 생겼음을 확인할 수 있습니다.
새로 생긴 'dataset_all.txt' 파일을 클릭해서 열어보면 아래와 같이 'day_20160701.txt' ~ 'day_20160710.txt'까지 10개 파일에 흩어져있던 데이터들이 차곡차곡 쌓여서 합쳐져 있음을 확인할 수 있습니다.
(6) 데이터 프레임으로 불러오기 : read.table() 칼럼 이름 붙이기 : col.names = c("var1", "var2", ...)
# reading dataset_all with column names
dataset_all_df <- read.table(
paste(src_dir, "/", "dataset_all.txt", sep=""),
sep = ",",
header = FALSE, # no column name in the dataset
col.names = c("ymd", "var1", "var2", "var3", "var4", "var5", + "var6", "var7", "var8", "var9", "var10"), # input column names
stringsAsFactor = FALSE,
na.strings = "NA") # missing value : "NA"
우측 상단의 environment 창에서 'dataset_all_df' 데이터 프레임이 새로 생겼습니다.
클릭해서 열어보면 아래와 같이 'day_20160701.txt' ~ 'day_20160710.txt'까지 데이터셋이 합쳐져있고, "ymd", "var1" ~ "var10" 까지 칼럼 이름도 생겼습니다.
댓글 질문에 '폴더에 있는 개별 파일을 하나씩 읽어와서 하나씩 DataFrame 객체로 메모리상에 생성하는 방법에 대한 질문이 있어서 코드 추가해서 올립니다. 위에서 소개한 방법과 전반부는 동일하구요, 마지막에 루프 돌릴 때 assign() 함수로 파일 이름을 할당하는 부분만 조금 다릅니다.
#========================================================= # read all files in a folder and make a separate dataframe #========================================================= rm(list=ls()) # clear all
# (2) make a file list of all files in the folder src_file <- list.files(src_dir) src_file
# (3) count the number of files in the directory => object src_file_cnt <- length(src_file) src_file_cnt # 5
# (4) read files one by one using looping # => make a dataframe one by one using assign function for (i in 1:src_file_cnt){ assign(paste0("day_", i), read.table(paste0(src_dir, "/", src_file[i]), sep = ",", header = FALSE)) print(i) # check progress }
댓글에 "여러개의 파일을 하나로 합칠 때 "파일 이름을 데이터 프레임의 새로운 칼럼에 값으로 추가한 후"에 합치는 방법"에 대한 문의가 있었습니다. 댓글란에 코드 블락을 복사해 넣으면 들여쓰기가 무시되어서 보기가 힘들므로 본문에 예제 코드 추가해 놓습니다.
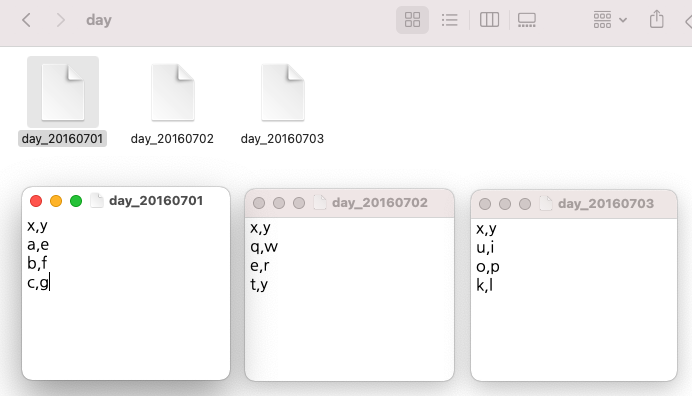
간단한 샘플 텍스트 파일 3개 만들어서 for loop 순환문으로 각 파일 읽어온 후, 파일 이름을 새로운 칼람 'z'의 값으로 할당 해주고, blank data.frame 인 'day_all' 에 순차적으로 rbind 해주었습니다.
multiple files
##--------------------------------------------------------
## add new column with file name and append all dataframes
##--------------------------------------------------------
## blank data.frame to save all files later
day_all <- data.frame()
## file list
src_dir <- c("/Users/lhongdon/Documents/day")
src_file <- list.files(src_dir)
src_file
# [1] "day_20160701" "day_20160702" "day_20160703"
for (i in 1:length(src_file)){
# read dataset 1 by 1 sequentially
day_temp <- read.table(
paste0(src_dir, "/", src_file[i]),
sep=",",
header=T,
stringsAsFactors=F)
# add filename as a new column
day_temp$z <- src_file[i]
# rbind day_temp to day_all data.frame
day_all <- rbind(day_all, day_temp)
#print(i) # for progress check
}
print(day_all)
# x y z
# 1 a e day_20160701
# 2 b f day_20160701
# 3 c g day_20160701
# 4 q w day_20160702
# 5 e r day_20160702
# 6 t y day_20160702
# 7 u i day_20160703
# 8 o p day_20160703
# 9 k l day_20160703
=============================
(2021.08.25 일 추가)
댓글에 추가 질문이 달려서 요건에 맞게 코드를 더 추가하였습니다.
중첩 for loop 문에 조건절이 여러개 들어가다 보니 코드가 많이 복잡해졌네요.
[데이터 전처리 요건 ]
1. 로컬 머신 폴더 내 여러개의 csv 파일을 읽어와서 한개의 R data.frame 으로 통합
2. 이때 개별 csv 파일로 부터 읽어들인 데이터를 특정 개수의 [행 * 열] data.frame 으로 표준화
- 가령, 3 행 (rows) * 3 열 (columns) 의 data.frame 으로 표준화하기 원한다면
- 개별 csv 파일로 부터 읽어들인 데이터의 행(row)의 개수가 3보다 크면 1~3행까지만 가져와서 합치고 나머지는 버림. 반대로 3개 행보다 부족하면 'NA' 결측값으로 처리함.
- 개별 csv 파일로 부터 읽어들인 데이터의 열(column)이 타켓 칼럼 이름(가령, "x", "y", "z") 중에서 특정 칼럼이 없다면 그 칼럼의 값은 모두 'NA' 결측값으로 처리함.(가령, csv 파일 내에 "x", "y" 만 있고 "z" 칼럼은 없다면 "z" 칼럼을 만들어주고 대신 값은 모두 'NA' 처리해줌)
3. 'day' 라는 칼럼을 새로 만들어서 파일 이름(day 날짜가 들어가 있음)을 값으로 넣어줌
##--------------------------------------------------------
## (1) 3 rows & 3 cols DataFrame
## (2) add new column with file name and append all dataframes
##--------------------------------------------------------
## blank data.frame to save all files later
day_all <- data.frame()
## file list
src_dir <- c("/Users/lhongdon/Documents/day")
src_file <- list.files(src_dir)
src_file
# [1] "day_20160701" "day_20160702" "day_20160703" "day_20160704"
## setting target rows & cols
row_num <- 3 # set your target number of rows
col_name <- c("x", "y", "z") # set your target name of columns
for (i in 1:length(src_file)){
# read dataset 1 by 1 sequentially
day_temp <- read.table(
paste0(src_dir, "/", src_file[i]),
sep=",",
header=T,
stringsAsFactors=F)
##-- if the number of rows is less than 3 then 'NA',
##-- if the number of rows is greater than 3 than ignore them
##-- if the name of columns is not in col_nm then 'NA'
# blank temp dataframe with 3 rows and 3 columns
tmp_r3_c3 <- data.frame(matrix(rep(NA, row_num*col_num),
nrow=row_num,
byrow=T))
names(tmp_r3_c3) <- col_name
tmp_row_num <- nrow(day_temp)
tmp_col_name <- colnames(day_temp)
r <- ifelse(row_num > tmp_row_num, tmp_row_num, row_num)
for (j in 1:r) {
for (k in 1:length(tmp_col_name)) {
tmp_r3_c3[j, tmp_col_name[k]] <- day_temp[j, tmp_col_name[k]]
}
}
# add filename as a new column 'day'
tmp_r3_c3$day <- src_file[i]
# rbind day_temp to day_all data.frame
day_all <- rbind(day_all, tmp_r3_c3)
rm(tmp_r3_c3)
print(i) # for progress check
}
print(day_all)
# x y z day
# 1 a e 1 day_20160701
# 2 b f 3 day_20160701
# 3 c g 5 day_20160701
# 4 q w NA day_20160702
# 5 e r NA day_20160702
# 6 t y NA day_20160702
# 7 u i 3 day_20160703
# 8 o p 6 day_20160703
# 9 <NA> <NA> NA day_20160703
# 10 e a 6 day_20160704
# 11 d z 5 day_20160704
# 12 c x 3 day_20160704
위에서 생성한 xy 데이터프레임을 가지고, y변수 1, 2, 3, 4, 5 를 포함한 행(row) 별로 각 각 개별 데이터 프레임을 Loop 를 사용해서 만들어보겠습니다. 아래 Loop program에서 목표 객체(Target object)에 paste() 함수를 사용해서 공통 접두사(predix)로 'xy_'를 사용하고 뒤에 'i'로 loop 를 돌면서 1, 2, 3, 4, 5 를 붙여주려고 프로그램을 짰습니다만, "target of assignment expands to non-language object" 라는 오류 메시지가 떴습니다. 아래 프로그램에 대해 R은 [ paste("xy_", i, sep="") ]부분을 NULL 값으로 인식하기 때문에 이런 오류가 발생하게 됩니다.
> for (i in 1:5) {
+ paste("xy_", i, sep="") <- subset(xy, subset = (y == i))
+ }
Error in paste("xy_", i, sep = "") <- subset(xy, subset = (y == i)) :
target of assignment expands to non-language object
위 프로그램에서 하고자 했던 의도대로 R이 이해하고 실행을 하게끔 하려면 assign() 함수를 사용해야만 합니다. assign() 함수를 사용할 때는 아래 처럼 '<-' 대신에 ',' 가 사용되었음에 주의하시기 바랍니다.
> for (i in 1:5) {
+ assign(paste("xy_", i, sep=""), subset(xy, subset = (y == i)))
+ }
>
한두개 정도 일회성으로 그래프 그리고 말거면 그냥 화면 캡쳐하는 프로그램 사용하거나 아니면 RStudio의 파일 내보내기를 사용하면 됩니다.
한두번 분석하고 말거면 그냥 마우스로 Console 창 분석결과에 블럭 설정하고 Copy & Paste 하면 됩니다.
하지만, 수백개, 수천개의 그래프를 그리고 이를 파일로 저장해야 하고 자동화(사용자 정의 함수, 루프) 해야 한다거나, 분석이나 모형개발을 수백개, 수천개 해야 하고 이의 결과를 따로 저장해야 한다면 이걸 수작업으로 매번 할 수는 없는 노릇입니다. 시간도 많이 걸리고, 아무래도 사람 손이 자꾸 타다 보면 실수도 하기 마련이기 때문입니다.
이에 이번 포스팅에서는
(1) ggplot2로 그린 그래프를 jpg 나 pdf 파일로 저장하는 방법
: ggsave()
(2) Console 창에 나타나는 분석 결과, 모형 개발 결과를 text 파일로 저장하는 방법
: capture.output()
에 대해서 소개하겠습니다. R script로 위 작업을 수행할 수 있다면 프로그래밍을 통해 자동화도 할 수 있겠지요.
예제로 사용할 데이터는 MASS 패키지 내 Cars93 데이터프레임의 고속도로연비(MPG.highway), 무게(Weight), 엔진크기(EngineSize), 마련(Horsepower), 길이(Length), 폭(Width) 등의 변수를 사용해서 선형 회귀모형을 만들고 이의 적합 결과를 text 파일로 내보내기를 해보겠습니다.
R분석을 하다 보면 데이터 전처리 라든지 그래프 그리기, 혹은 모형 개발/ update 등을 하는데 있어 반복 작업을 하는 경우가 있습니다.
이때 대상 데이터셋이라든지 변수, 혹은 조건 등을 조금씩 바꿔가면서 반복 작업을 (반)자동화 하고 싶을 때 유용하게 사용할 수 있는 것이 사용자 정의 함수 (User Defined Function) 입니다.
만약 사용자 정의 함수를 사용하지 않는다면 특정 부분만 바뀌고 나머지는 동일한 프로그램이 매우 길고 복잡하고 산만하게 늘어세울 수 밖에 없게 됩니다. 반면 사용자 정의 함수를 사용하면 사용자 정의 함수 정의 후에 바뀌는 부분만 깔끔하게 사용자 정의 함수의 입력란에 바꿔서 한줄 입력하고 실행하면 끝입니다. 반복작업이 있다 싶으면 손과 발의 노가다를 줄이고 작업/분석 시간을 줄이는 방법, 프로그래밍을 간결하고 깔끔하게 짜는 방법으로 사용자 정의 함수를 사용할 여지가 있는지 살펴볼 필요가 있겠습니다.
사용자 정의 함수는
function_name <- function( arg1, arg2, ... ) {
expression
return( object)
}
의 형식을 따릅니다.
몇 가지 예을 들어서 설명해보겠습니다.
1) 평균(mean), 표준편차(standard deviation), min, max 계산 사용자 정의 함수 (User defined function of statistics for continuous variable)
2) 산점도 그래프 그리기 사용자 정의 함수 (User defined function of scatter plot)
> # 산점도 그래프 그리기 함수 (scatter plot)
> plot_function <- function(dataset, x, y, title) {
+ attach(dataset)
+ plot(y ~ x, dataset, type="p",
+ main = title)
+ detach(dataset)
> plot_function(dataset=Cars93, x=MPG.highway, y=Weight, title="Scatter Plot of MPG.highway & Weight")
> plot_function(dataset=Cars93, x=Price, y=Horsepower, title="Scatter Plot of Price & Horsepower")
위의 기초통계량은 summary() 함수를 사용하면 되고 산포도도 plot() 함수를 쓰는 것과 별 차이가 없어보여서 사용자 정의 함수를 쓰는 것이 뭐가 매력적인지 잘 이해가 안갈 수도 있을 것 같습니다. 하지만 만약 기초 통계량을 뽑아서 txt 파일로 외부로 내보내기를 하고, x 변수를 바꿔가면서 loop를 돌려서 반복적으로 기초 통계량을 뽑고 이것을 계속 txt 파일로 외부로 내보내기를 하되, 앞서 내보냈던 파일에 계속 append 를 해가면서 결과값을 저장한다고 할때는 위의 사용자 정의 함수를 사용하는 것이 정답입니다.
그래프도 변수명의 일부분을 바꿔가면서 그래프를 그리고 싶을 때는 paste() 함수를 적절히 사용하면 사용자 정의 함수를 더욱 강력하게 사용할 수 있게 됩니다. 응용하기 나름이고, 사용 가능한 경우가 무궁무진한데요, 이번 포스팅에서는 사용자 정의 함수의 기본 뼈대에 대해서만 간략히 살펴 보았습니다.
참고로, 사용자 정의 함수를 정의할 때 아래처럼 function(x, y, ...) 의 파란색 생략부호 점을 입력하면 나중에 사용자 정의 함수에서 정의하지 않았던 부가적인 옵션들을 추가로 덧붙여서 사용할 수 있어서 유연성이 높아지는 효과가 있습니다.
위의 2개의 예에서는 x1 이 4일 때 "Even Number"라고 판단했고, x2가 5일 때 "Odd Number"라고 잘 판단하였습니다.
하지만, 아래의 예제처럼 두개 이상의 논리값 벡터를 사용하는 경우에는 오류가 발생하게 되며, 아래 예제에서 보면 1~5까지 숫자 중에서 제일 처음으로 나오는 1에만 아래의 조건연산 프로그램이 적용되었고 두번째부터는 적용이 안되었습니다. 이럴 때는 ifelse() 문을 사용하여야 합니다.
> # Error
> x3 <- c(1, 2, 3, 4, 5)
> if (x3 %% 2 == 0) {
+ y3 = "Even Number"
+ print(y3)
+ } else {
+ y3 = "Odd Number"
+ print(y3)
+ }
[1] "Odd Number"
Warning message:
In if (x3%%2 == 0) { : the condition has length > 1 and only the first element will be used

 '를 꾹 눌러주세요.
'를 꾹 눌러주세요.