베이지안 통계(Bayesian Statistics)와 베이즈 정리(Bayes's Theorem)
Python 분석과 프로그래밍/Python 통계분석 2023. 12. 9. 16:47베이지안 통계는 확률이나 정보의 새로운 증거에 따라 확률을 갱신하는 통계학의 한 분야입니다. 이는 18세기 수학자 토마스 베이즈(Thomas Bayes)의 이름에서 따왔으며 통계적 추론에 대한 확률적인 프레임워크를 제공합니다.
베이지안 통계의 주요 개념을 하나씩 소개하고, 예제를 하나 풀어보겠습니다.
1. 베이즈 정리 (Bayes' Theorem) 및 베이지안 통계 주요 개념
베이지안 통계의 핵심은 베이즈 정리로, 사건의 확률을 사건과 관련된 조건에 대한 이전 지식을 기반으로 설명합니다. 수식은 다음과 같습니다. 여기서 는 사후 확률(조건 B가 주어졌을 때 A의 확률), 는 우도(조건 A가 주어졌을 때 B의 확률), 는 사전 확률, 는 B의 주변 확률입니다.

- 사전 확률 (Prior Probability): 사전 확률은 새로운 증거를 고려하기 전의 사건에 대한 초기 믿음 또는 확률을 나타냅니다. 이는 이전 지식이나 경험에 기초합니다.
- 우도(Likelihood): 우도는 특정 가설이나 모델로 관측된 데이터를 설명할 수 있는 정도를 나타냅니다. 특정 가설이나 모델이 주어졌을 때 관측된 데이터의 확률을 나타냅니다.
- 사후 확률(Posterior Probability): 사후 확률은 새로운 증거를 고려한 후의 가설이나 사건의 갱신된 확률입니다. 베이즈 정리를 사용하여 계산됩니다.
- 사후 추론(Posterior Inference): 베이지안 통계에서는 매개변수의 점 추정 대신에 사후 분포에 중점을 둡니다. 이 분포는 가능한 값의 범위와 해당 확률을 제공합니다.
- 베이지안 갱신(Bayesian Updating): 새로운 데이터가 생기면 베이지안 통계는 믿음과 확률을 계속해서 갱신할 수 있습니다. 한 번의 분석에서 얻은 사후 분포는 다음 분석의 사전 분포가 될 수 있습니다.
베이지안 통계는 데이터가 제한적인 경우나 사전 지식을 통합해야 하는 경우에 특히 유용합니다. 기계 학습, 데이터 과학, 경제학 및 의학 연구를 포함한 여러 분야에서 응용되며 불확실성을 일관되고 확률적으로 처리하는 유연성과 능력으로 알려져 있습니다.
2. 빈도론자(Frequentist) vs. 베이지안(Bayesian) 통계 추론*
통계추론은 크게 빈도론자(Frequentist), 베이지안(Bayesian)에 의한 추론으로 구분합니다. 예를 들어서 비교해보겠습니다. ( * 예시 출처: '통계학의 개념과 제문제', 이긍희, 김훈, 김재희, 박진호, 이재용 공저, KNOU출판부)
"예를 들어, 어느 학교에 학생이 입학하였습니다. 학교는 학업 능력이 낮은 학생은 탈락시키고 학업 능력이 높은 학생은 조기에 상급학교에 진학시킨다고 합니다. 두 학생의 학업능력을 평가하기 위해 여러 번의 시험과 과제물을 평가하였습니다.
빈도론자(Frequentist)의 추론은 학생의 학업능력은 고정되어 있다고 가정하고, 일정기간 동안 여러 번의 시험과 과제물 채점 결과로 그 학생의 능력을 평가합니다. 시험 회수를 늘릴수록 두 학생의 평가결과는 공정하게 비교된다고 봅니다.
반면에 베이지안(Bayesian)은 학생의 학업능력은 고정되어 있지 않다고 가정하고 시험과 과제물 채점 시마다 그 학생의 능력평가를 변경합니다. 먼저 학생의 능력은 모두 같다고 가정합니다(또는 분석자가 사전정보를 이용한다면 한 학생이 다른 학생보다 우수하다고 가정합니다). 첫 시험을 보았는데 어떤 학생이 시험을 잘 본다면 그 학생의 능력은 다른 학생보다 우수한 것으로 생각합니다. 다음 시험을 본 후 그 학생의 능력에 대한 판단을 수정합니다."
베이지안의 추론 방식이 일면 합리적이고, 또 보통 사람이 추론하는 방식과 유사함을 알 수 있습니다. 특히, 관측할 수 있는 데이터의 개수가 제한적이고 적을 때 사전적으로 알고 있는 지식이나 주관적인 믿음을 사전 확률로 이용하고, 새로 관측된 데이터로 사후 확률을 업데이트 하는 베이지안 분석법이 매우 강력합니다. 그리고 사후 확률도 단 하나의 점 추정이 아니라 확률적으로 생각하는 방식도 유효하구요.
빈도론자와 베인지안 간에 서로 논박하는 주요 내용은 아래를 참고하세요.
빈도론자(Frequentist)는 고정된 모수를 무한히 반복되는 표본에 대한 통계량의 표본분포를 바탕으로 추정하거나 검정합니다.
반면 베이지안(Bayesian)은 표본확률에 사전확률을 더하여 추정합니다(위의 Bayes' Theorem). 모수는 임의적이어서 확률분포를 가지고 있으며, 모든 추정과 검정은 주어진 데이터와 모수의 사전확률을 바탕으로 한 사후확률에 기반해서 진행됩니다.
빈도론자(Frequentist)는 베이지안의 결과가 지나치게 모수의 사전분포에 의존해서 결과가 일정하지 않고 계산시간이 많이 든다고 비판합니다.
반면 베이지안(Bayesian)은 빈도론자가 주어진 정보를 활용하지 않아 올바른 추정에 어려움이 있다고 비판합니다.
(* 출처: '통계학의 개념과 제문제', 이긍희, 김훈, 김재희, 박진호, 이재용 공저, KNOU출판부)
3. 베이지안 통계 추론에 의한 사후 확률 계산 예시
의료 암 진단 사례로 베이지안 갱신의 예를 들어보겠습니다.
(문제) 의료 데이터에 의하면 사전에 알려진 어떤 암에 걸릴 확률이 0.1% 라고 합니다.
암에 걸렸는지를 검사하는 진단에서 실제 암이 걸린 사람은 90%의 확률로 양성이 나오고, 실제로 암에 안 걸린 건강한 사람은 5%의 확률로 양성(오진단)이 나온다고 합니다.
이럴 때 이 암 진단에서 양성이라고 판정이 나왔을 때, 실제로 암에 걸렸을 확률을 계산하세요.
이해하기 쉽도록 도식화해서 순서대로 풀어보겠습니다.
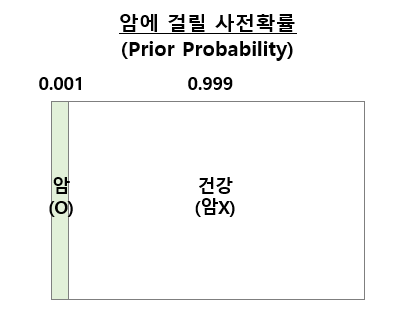
(1) 사전 확률 (Prior probability) 설정
아직은 개별 환자에 대한 정보가 없는 상태에서, 기존의 의료 데이터로 부터 얻은 사전 확률은 암에 걸릴 확률이 0.1%, 암에 걸리지 않을 확률이 99.9%라는 것을 이미 알고 있습니다.
(2) 검사 정밀도에 따른 조건부 확률 (Likelihood)
위 문제에 보면, 암에 걸렸다는 조건이 주어졌을 때 검사가 양성일 조건부 확률(P(D|H))이 90%, 암에 걸리지 않고 건강하다는 조건이 주어졌을 때 검사가 양성일 조건부 확률이 5% 라고 합니다. 이를 표로 표현하면 아래와 같습니다.

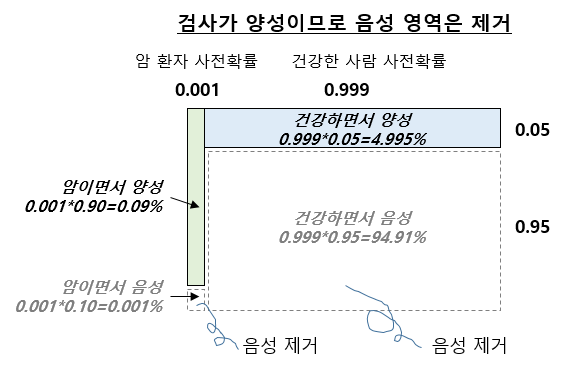
(3) 4개 유형별 각각의 확률 계산
위에 주어진 확률들로 부터 아래와 같이 4개의 유형이 존재하게 되며, 각 유형별로 확률을 계산해볼 수 있습니다.
- 암이면서 양성일 확률 = 0.001 * 0.90 = 0.09%
- 암이면서 음성일 확률 = 0.001 * 0.10 = 0.01%
- 건강하면서 양성일 확률 = 0.999 * 0.05 = 4.995%
- 건강하면서 음성일 확률 = 0.999 * 0.95 = 94.91%

(4) 검사가 양성이므로 음성 영역은 제거
우리가 관심있어하는 사람의 진단 결과가 양성이라고 했으므로, 위의 (3)번에서 진단 결과가 음성인 영역은 이 환자에게는 해당사항이 없으므로 제거합니다.
(5) 정규화(normalization)한 후의 사후 확률 (Posterior Probability) 계산
진단 결과가 양성인 영역만 남겨둔 상태에서, 암이면서 양성인 확률 (=0.001 * 0.90 = 0.09%) 과 건강하면서 양성인 확률을 (0.999 * 0.05 = 4.995%) 모두 더해서, 이 값으로 암이면서 양성인 확률과 건강하면서 양성인 확률을 나누어 주면 정규화(normalization)이 된 사후 확률을 구할 수 있습니다.
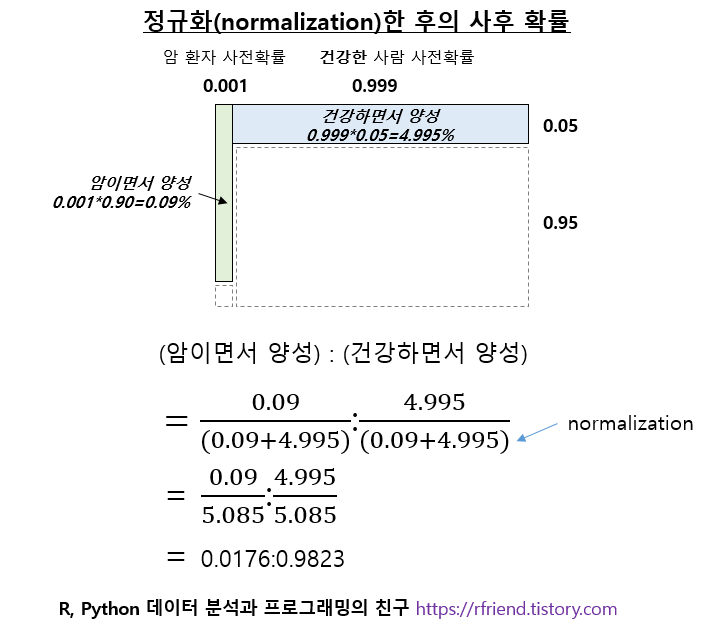
위에서 손으로 풀어본 결과 암 진단 결과가 양성으로 나온 사람이 있다고 했을 때, 실제 암에 걸렸을 사후 확률은 0.09 / (0.09 + 4.995) = 1.76% 이네요. (실제 건강한데 진단 결과 양성이 나왔을 사후 확률은 4.995 / (0.09+4.994) = 98.23% (=1-1.76%) 입니다)
90%의 정확도로 암을 진단하는 검사의 결과에서 양성이 나온다면 일반인들은 '아, 이제 나 죽나보구나. 흑.. ㅠ.ㅠ' 하고 앞이 깜깜할 거 같습니다. 그런데 베이지안(Bayesian) 통계에 대한 지식이 있는 사람이라면, '흠... 사전확률을 보니 대부분의 사람은 암이 아니고 극소수만 암이기 때문에, 진단 결과가 양성이라는 새로운 정보를 업데이트 해도... 실제로 암일 사후 확률이 그리 높지는 않겠네. 추가 검사를 기다려보도록 하지' 라고 생각할 수 있겠습니다. 베이지안 통계를 알면 쫄지 않아도 됩니다! ㅋㅋ
위의 사례를 보면 통계 지식이 부족한 일반인들이 생각하는 결과와 베이지안 통계로 추정한 확률이 차이가 많이 나고, 베이지안 통계가 일반인들의 확률에 대한 상식에 반하는거 아닌가하는 생각마저 들지도 모르겠습니다. ^^;
4. Python을 이용한 베이지안 갱신 (Bayesian Updating) 계산
베이즈 정리를 이용하여 사전확률, 조건부 확률이 주어졌을 때 사후확률을 구하는 사용자 정의 함수를 정의해보겠습니다.
## Bayesian Update using Bayes's Theorem
import numpy as np
def bayesian_update(prior_prob, likelihood, verbose=True):
# Bayes' theorem: P(H|D) = P(D|H) * P(H) / P(D)
# Posterior Probability = Likelihood * Prior Probability / Evidence
# Calculate the unnormalized posterior probability
posterior_unnormalized = likelihood * prior_prob
# Calculate the evidence (marginal likelihood) using the law of total probability
evidence = sum(posterior_unnormalized)
# Calculate the normalized posterior probability
posterior_prob = posterior_unnormalized / evidence
if verbose:
print('Likelihood:', likelihood)
print('Prior Probability:', prior_prob)
print('Posterior Unnormalized:', posterior_unnormalized)
print('Evidence(Marginal Likelihood):', evidence)
print('Posterior Probability:', posterior_prob)
return posterior_prob
어느 특정 암에 걸릴 확률이 0.1% 라고 하는 사전확률이 주어지고,
암에 걸렸을 때 암 검사에서 양성이 나올 조건부 확률이 90.0%,
암에 걸리지 않았을 때 양성이 나올 조건부 확률이 5% 라고 했을 때,
만약 어떤 사람이 암 검사에서 양성이 나왔다면 실제로 암에 걸렸을 사후 확률을 계산해 보겠습니다.
# Example values
prior_probability = np.array([0.001, 0.999]) # Prior probability for H0 and H1
likelihood_given_h0 = np.array([0.90, 0.05]) # Likelihood of the data given H0
#likelihood_given_h1 = np.array([0.10, 0.95]) # Likelihood of the data given H1
# Update the posterior probability
posterior_probability_h0 = bayesian_update(prior_probability, likelihood_given_h0)
# Print the results
print("-----" * 10)
print("Posterior Probability for H0:", posterior_probability_h0)
# Likelihood: [0.9 0.05]
# Prior Probability: [0.001 0.999]
# Posterior Unnormalized: [0.0009 0.04995]
# Evidence(Marginal Likelihood): 0.05085
# Posterior Probability: [0.01769912 0.98230088]
# --------------------------------------------------
# Posterior Probability for H0: [0.01769912 0.98230088]
암 검사에서 양성이 나왔을 때 실제로 암에 걸렸을 확률은 1.76% 네요.
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요.

'Python 분석과 프로그래밍 > Python 통계분석' 카테고리의 다른 글
| 확률 (Probability) vs. 우도 (Likelihood) (0) | 2023.12.10 |
|---|---|
| 상관관계(Correlation) vs. 인과관계(Causation) (0) | 2023.12.10 |
| 중심극한의 정리 (Central Limit Theorem) 이란 무엇이고, 왜 중요한가? (0) | 2023.12.09 |
| [Python] 통계에서 p-값은 무엇이고, 어떻게 해석하는가? (p-value in statistics) (0) | 2023.12.08 |
| [Python] 쌍을 이룬 t-test (paired t-test) (0) | 2022.10.03 |



