이번 포스팅에서는 PostgreSQL, Greenplum database에서 SQL, MADlib 함수, PL/R, PL/Python을 사용해서 연속형 데이터에 대한 요약통계량을 구하는 방법을 소개하겠습니다. 무척 쉬운 내용이므로 쉬어가는 코너 정도로 가볍게 생각해주시면 좋겠습니다. ^^
PostgreSQL, Greenplum database 에서 연속형 데이터에 대해 그룹별로,
(1) SQL 로 요약통계량 구하기
(2) Apache MADlib 으로 요약통계량 구하기
참고로, 이번 포스팅에서는 PostgreSQL 9.4, Greenplum 6.10.1 버전을 사용하였으며, PostgreSQL 9.4 버전보다 낮은 버전을 사용하면 최빈값(mode), 사분위부(percentile) 구하는 함수를 사용할 수 없습니다.
먼저, 예제로 사용하기 위해 '나이'의 연속형 데이터와 '성별'의 범주형 데이터 (그룹)를 가진 간단한 테이블을 만들어보겠습니다. 결측값(missing value)도 성별 그룹별로 몇 개 넣어봤습니다.
DROP TABLE IF EXISTS cust;
CREATE TABLE cust (id INT, age INT, gender TEXT);
INSERT INTO cust VALUES
(1,NULL,'M'),
(2,NULL,'M'),
(3,25,'M'),
(4,28,'M'),
(5,27,'M'),
(6,25,'M'),
(7,26,'M'),
(8,29,'M'),
(9,25,'M'),
(10,27,'M'),
(11,NULL,'F'),
(12,23,'F'),
(13,25,'F'),
(14,23,'F'),
(15,24,'F'),
(16,26,'F'),
(17,23,'F'),
(18,24,'F'),
(19,22,'F'),
(20,23,'F');
(1) SQL로 연속형 데이터의 그룹별 요약통계량 구하기
함수가 굳이 설명을 안해도 될 정도로 간단하므로 길게 설명하지는 않겠습니다.
표준편차 STDDEV() 와 분산 VARIANCE() 함수는 표본표준편차(sample standard deviation), 표본분산(sample variance) 를 계산해줍니다. 만약 모표준편차(population standard deviation), 모분산(population variance)를 구하고 싶으면 STDDEV_POP(), VAR_POP() 함수를 사용하면 됩니다.
PostgreSQL 9.4 버전 이상부터 최빈값(MODE), 백분위수(Percentile) 함수가 생겨서 정렬한 후에 집계하는 기능이 매우 편리해졌습니다. (MODE(), PERCENTILE_DISC() 함수를 사용하지 않고 pure SQL로 최빈값과 백분위수를 구하려면 query 가 꽤 길어집니다.)
SELECT
gender AS group_by_value
, 'age' AS target_column
, COUNT(*) AS row_count
, COUNT(DISTINCT age) AS distinct_values
, AVG(age)
, VARIANCE(age)
, STDDEV(age)
, MIN(age)
, PERCENTILE_DISC(0.25) WITHIN GROUP (ORDER BY age) AS first_quartile
, MEDIAN(age)
, PERCENTILE_DISC(0.75) WITHIN GROUP (ORDER BY age) AS third_quartile
, MAX(age)
, MODE() WITHIN GROUP (ORDER BY age) -- over PostgreSQL 9.4
FROM cust
WHERE age IS NOT NULL
GROUP BY gender
ORDER BY gender;
성별 그룹별로 연령(age) 칼럼의 결측값 개수를 구해보겠습니다.
결측값 개수는 WHERE age IS NULL 로 조건절을 주고 COUNT(*)로 행의 개수를 세어주면 됩니다.
SELECT
gender
, COUNT(*) AS missing_count
FROM cust
WHERE age IS NULL
GROUP BY gender
ORDER BY gender;
Out[5]:
gender
missing_count
F
1
M
2
위의 집계/ 요약통계량과 결측값 개수를 하나의 조회 결과로 보려면 아래처럼 Join 을 해주면 됩니다.
WITH summary_tbl AS ( SELECT gender AS group_by_value , 'age' AS target_column , COUNT(*) AS row_count , COUNT(DISTINCT age) AS distinct_values , AVG(age) , VARIANCE(age) , STDDEV(age) , MIN(age) , PERCENTILE_DISC(0.25) WITHIN GROUP (ORDER BY age) AS first_quartile , MEDIAN(age) , PERCENTILE_DISC(0.75) WITHIN GROUP (ORDER BY age) AS third_quartile , MAX(age) , MODE() WITHIN GROUP (ORDER BY age) FROM cust WHERE age IS NOT NULL GROUP BY gender ORDER BY gender ), missing_tbl AS ( SELECT gender AS group_by_value , COUNT(*) AS missing_count FROM cust WHERE age IS NULL GROUP BY gender ) SELECT a.*, b.missing_count FROM summary_tbl a LEFT JOIN missing_tbl b USING(group_by_value) ;
(2) Apache MADlib으로 연속형 데이터의 그룹별 요약통계량 구하기
Apache MADlib의 madlib.summary() 함수를 사용하면 단 몇 줄의 코드만으로 위의 (1)번에서 SQL 집계 함수를 사용해서 길게 짠 코드를 대신해서 매우 깔끔하고 간단하게 구할 수 있습니다.
아래는 (1)번의 결과를 얻기위해 성별(gender) 연령(age) 칼럼의 집계/요약데이터를 구하는 madlib.summary() 함수 예시입니다.
Target columns 위치에는 1 개 이상의 분석을 원하는 연속형 데이터 칼럼을 추가로 넣어주기만 하면 되므로 (1) 번의 pure SQL 대비 훨씬 편리한 측면이 있습니다!
그리고 그룹별로 구분해서 집계/요약하고 싶으면 Grouping columns 위치에 기준 칼럼 이름을 넣어주기만 하면 되므로 역시 (1)번의 pure SQL 대비 훨씬 편리합니다!
DROP TABLE IF EXISTS cust_summary;
SELECT madlib.summary('cust' -- Source table
,'cust_summary' -- Output table
, 'age' -- Target columns
, 'gender' -- Grouping columns
);
madlib.summary() 함수의 결과 테이블에서 조회할 수 있는 집계/요약통계량 칼럼 리스트는 아래와 같습니다.
이번에는 PL/R 의 output 을 반환하는 5가지 방법 (5 ways to return PL/R result on Greenplum) 을 소개하겠습니다.
(1) returns float8[] : array 형태로 결과 반환 (그룹 당 1행)
(2) returns setof float8 : 행 단위로 결과 반환 (관측치 당 1행, 그룹 당 여러 행)
(3) reterns setof composite_type : 행 단위로 composite type에 맞게 결과 반환
(관측치 당 1행, 그룹 당 여러 행)
(4) returns table : 행 단위로 결과 반환 (관측치 당 1행, 그룹 당 여러 행)
(5) returns bytea : byte array 로 결과 반환 (그룹 당 1행)
--> unserialize 하는 PL/R 함수 추가로 필요
[ PL/R on Greenplum & PostgreSQL DB (workflow 예시) ]
예제에 사용하기 위해 그룹('grp') 칼럼과 정수('x1'), 실수('x2') 칼럼을 가진간단한 테이블을 생성해보겠습니다.
----------------------------------
-- PL/R on Greenplum
-- : 5 ways to return PL/R results
----------------------------------
-- create an example dataset table
createschema test;
droptableifexists test.src_tbl;
createtable test.src_tbl (
grp varchar(10) notnull
, x1 integer
, x2 float8
) distributed by (grp);
insertinto test.src_tbl values
('a', 1, 0.13)
, ('a', 2, 0.34)
, ('a', 3, 0.31)
, ('a', 4, 0.49)
, ('a', 5, 0.51)
, ('b', 1, 0.10)
, ('b', 2, 0.26)
, ('b', 3, 0.30)
, ('b', 4, 0.62)
, ('b', 5, 0.59);
select * from test.src_tbl;
예시에 사용할 PL/R 함수는 x1에 2를 곱하고 x2를 로그 변환 (log transformation) 하여 더한 값 (x_new = 2 * x1 + log(x2))을 계산하는 매우 간단한 것입니다. (물론 SQL로도 할 수 있는데요, PL/R 예시로 간단한 걸로 사용한 거예요)
(1) returns float8[] : array 형태로 결과 반환 (그룹 당 1행)
returns float8[] 에서 꺽쇠 '[]' 가 array 로 반환하라는 의미의 기호입니다.
코딩이 간단하고 그룹별로 1행으로 저장이 되므로 조회나 테이블 조인(table join) 할 때 빠르다는 장점이 있습니다. 하지만 조회를 했을 때 array 형태이므로 조회해서 보고 활용할 때 보통 unnest 를 해야 해서 불편한 점이 있습니다.
, test.plr_log_trans(a.x1_agg, a.x2_agg) as x_new_agg
from (
select
grp
, array_agg(x1::int) as x1_agg
, array_agg(x2::float8) as x2_agg
from test.src_tbl
groupby grp
) a;
위의 PL/R 결과 테이블에서 보는 것처럼 array 형태로 PL/R 결과를 반환하기 때문에 { } 안에 옆으로 길게 늘어서 있어서 보기에 불편합니다. 이럴 경우 SQL의 unnest() 함수를 사용해서 세로로 길게 행 단위(by row)로 테이블 형태를 바꾸어서 조회할 수 있습니다.
-- Display by rows using unnest() function
select
a.grp
, unnest(a.x1_agg) as x1
, unnest(a.x2_agg) as x2
, unnest(test.plr_log_trans(a.x1_agg, a.x2_agg)) as x_new
from (
select
grp
, array_agg(x1::int) as x1_agg
, array_agg(x2::float8) as x2_agg
from test.src_tbl
groupby grp
) a;
(2) returns setof float8 : 행 단위로 결과 반환 (관측치 당 1행, 그룹 당 여러 행)
위의 (1) 번과 지금 소개하는 (2)번이 다른 점은 (a) setof 추가, (b) [] 제거 의 두 가지입니다.
- (1)번 : returns float8[]
- (2)번 : returns setof float8
(2)번 방법으로 하면 (1)번에서 처럼 unnest() 함수를 쓸 필요없이 바로 행 단위(by rows)로 PL/R 결과를 반환합니다.
, test.plr_log_trans_2(a.x1_agg, a.x2_agg) as x_new
from (
select
grp
, array_agg(x1::int) as x1_agg
, array_agg(x2::float8) as x2_agg
from test.src_tbl
groupby grp
) a;
(3) reterns setof composite_type : 행 단위로 composite type 에 맞게 결과 반환
(관측치 당 1행, 그룹 당 여러 행)
PL/R 함수의 결과로 반환받을 결과값이 여러개의 칼럼으로 구성되어 있는 경우 composite type을 정의해서 PL/R 함수 정의할 때 사용할 수 있습니다.
위의 (2)번 예에서는 PL/R 실행 결과의 반환받는 값으로 x_new = 2*x1 + log(x2) 의 x_new 값 단 1개만 float8 형태로 반환했습니다. 이번 (3)번 예에서는 PL/R 결과값으로 x1 (integer), x2, (float8) x_new (float8) 의 3개 칼럼의 composite type 형태로 반환해보겠습니다.
이러려면 create type 으로 반환받을 composite type 을 먼저 정의를 해줍니다. 그 다음으로 PL/R 함수를 정의할 때 returns setof composite_type_name 처럼 앞서 정의한 compositie type 이름을 returns setof 뒤에 써주면 됩니다.
(2)번 예에서는 PL/R 을 실행(execution) 하면 x_new 계산 결과만 반환하므로 x_1, x_2 를 select 문에 별도로 써주었습니다. 하지만 (3)번 예에서는 PL/R 함수를 보면 x_1, x_2, x_new 를 하나의 DataFrame으로 묶고 이를 통채로 반환하도록 되어있습니다. 그리고 composite type을 x_1, x_2, x_new 각각의 데이터 유형에 맞게 정의해주었구요.
(4) returns table : 행 단위로 결과 반환 (관측치 당 1행, 그룹 당 여러 행)
PL/R 함수를 실행했을 때 반환받을 값의 칼럼이 여러개일 경우 위의 (3)번 처럼 composite type을 미리 정의해서 PL/R 함수를 정의할 때 returns setof composite_type_name 형식으로 쓸 수도 있구요, 이번의 (4)번처럼 바로 returns table (반환받을 칼럼 이름과 데이터 유형) 형식으로 바로 쓸 수도 있습니다.
(3)번 처럼 composite type을 미리 정의해두면 나중에 똑같은 칼럼과 데이터 유형으로 PL/R에 input 넣거나 output 으로 반환받을 때 그냥 composite type name 을 써주면 되므로 재활용할 수 있는 장점이 있습니다.
이번 (4)번처럼 composite type을 정의하는것 없이 그냥 바로 returns table () 처럼 하면 일단 편하고 또 직관적이어서 이해하기 쉬운 장점이 있으며, 대신 (3)번처럼 재활용은 못하므로 매번 써줘야 하는 단점이 있습니다.
, test.plr_log_trans_5(a.x1_agg, a.x2_agg) as serialized_df
from (
select
grp
, array_agg(x1::int) as x1_agg
, array_agg(x2::float8) as x2_agg
from test.src_tbl
groupby grp
) a
) distributed by (grp);
select * from test.tbl_plr_log_trans_5;
위의 직렬화되어서 반환된 PL/R 결과를 select 문으로 조회를 해보면 사람은 눈으로 읽을 수 없게 저장이 되어있음을 알 수 있습니다. 아래는 R의 unserialize() 함수를 사용해서 역직렬화(deserialize, decode)를 해서 미리 정의해둔 composite type 으로 반환하도록 해준 PL/R 코드입니다. 좀 복잡하게 느껴질 수도 있겠습니다. ^^;
-- Unserialize
-- Define composite data type
droptype test.plr_log_trans_type cascade;
createtype test.plr_log_trans_type as (
x1 integer
, x2 float8
, x_new float8
);
-- Define PL/R UDF for reading a serialized PL/R results
Greenplum 혹은 PostgreSQL DB에서 PL/R (Procudural LanguageR Extension) 분석을 위해서는 (1) PL/R 사용자 정의 함수 정의 (define PL/R UDF), (2) array aggregation 하여 데이터 준비 (Preparation of data by array aggregation), (3) PL/R 사용자 정의 함수를 호출하여 실행 (execute PL/R UDF) 의 순서로 진행이 됩니다.
이번 포스팅에서는 Greenplum 혹은 PostgreSQL DB에서 PL/R (Procedural Language R)을 사용해서 In-DB analytics 를 하기 위해서 array 형태로 데이터를 준비하는 3가지 방법을 소개하겠습니다.
1. 열(column)을 기준으로 여러개의 행(row)을 그룹별로 array aggregation
2. 행과 열을 기준으로 그룹별로 2D (2-dimensional) array aggregation
3. 문자열로 string aggregation 하고 PL/R 코드 안에서 R로 데이터셋 변환하기
[ Workflow and Output Image of PL/R on Greenplum, PostgreSQL DB ]
예제로 사용할 PL/R 분석은 'a'와 'b' 두 개의 그룹 별로 x1, x2 두 숫자형 변수 간의 상관계수(correlation coefficients)를 계산하는 업무입니다.
예제로 사용할 간단한 테이블을 먼저 만들어보겠습니다.
--create schema and sample table
createschema test;
droptableifexists test.tbl;
createtable test.tbl (
grp textnotnull
, x1 int
, x2 int
);
insertinto test.tbl (grp, x1, x2) values
('a', 1, 2)
, ('a', 2, 5)
, ('a', 3, 4)
, ('b', 1, 8)
, ('b', 2, 7)
, ('b', 3, 3);
select * from test.tbl;
1. 열(column)을 기준으로 여러개의 행(row)을 그룹별로array aggregation
첫번째는 SQL 의 array_agg() 함수를 사용해서 그룹('grp') 별로 x1, x2 각 칼럼을 기준으로 여러개의 행을 array 형태로 aggregation 하는 방법입니다. 칼럼 기준으로 array aggregation 을 하기 때문에 PL/R 사용자 정의 함수 안에서 각 칼럼을 인자로 받아서 정의하기에 직관적으로 이해하기 쉽고 사용이 편리한 장점이 있습니다. 또 각 칼럼 별로 데이터 유형 (data type)이 서로 다를 경우 (가령, 칼럼이 텍스트, 정수형, 부동소수형 등으로 서로 다른 경우) 각 칼럼 별로 array aggregation 을 하기 때문에 각자 데이터 유형에 맞추어서 해주면 되는 점도 편리합니다.
다만, 칼럼의 개수가 많을 경우에는 일일이 array aggregation 하고, 또 PL/R 사용자 정의 함수 안에서 이들 칼럼을 다시 인자로 받아서 data frame 으로 만들거나 할 때 손이 많이 가서 번거로울 수 있습니다. 그리고, 그룹 별로 array aggregation 을 했을 때 만약 데이터 크기가 크다면 PL/R을 실행할 때 데이터 I/O 에 다소 시간이 소요될 수 있습니다.
2. 행과 열을 기준으로 그룹별로 2D (2-dimensional) array aggregation
두번째 방법은 Apache MADlib 의 madlib.matrix_agg() 함수를 사용해서 2차원 배열의 행렬을 만드는 것입니다. 만약 칼럼별 데이터 유형이 모두 숫자형이고 또 칼럼의 개수가 많아서(가령, 수십~수백개) 일일이 array_agg() 를 하기가 번거롭다면 madlib.matrix_agg() 함수를 사용하는 것이 상대적으로 2D array aggregation 하기도 쉽고 또 PL/R 사용자 정의 함수 안에서 데이터 변환을 해서 이용하기도 편리합니다.
반면에, 만약 각 칼럼 별 데이터 유형이 서로 다르고 숫자형이 아닌 텍스트 등이 들어있다면 사용할 수가 없습니다.
MADlib 의 함수를 사용하는 것이므로 Greenplum DB에 MADlib을 미리 설치해두어야 합니다.
3. 문자열로 string aggregation 한 후 PL/R 코드 안에서 R 로 데이터셋 변환하기
PL/R 함수에 input으로 들어갈 데이터를 준비하는 세번째 방법은 데이터를 텍스트로 변환해서 SQL의 string_agg() 함수를 사용하여 구분자(delimiter, 가령 ',' 나 '|' 등)를 값 사이에 추가하여 그룹별로 aggregation 하는 것입니다.
string aggregation을 사용하면 다양한 데이터 유형 (가령, 텍스트, 정수, 부동소수형 등)이 섞여 있는 다수의 칼럼을 그룹 별 & 행(row) 별로 aggregation 할 수 있고, 또 array aggregation 대비 상대적으로 데이터 크기를 줄여서 PL/R 실행 시 데이터 I/O 시간을 다소 줄일 수 있는 장점이 있습니다.
반면에, PL/R 함수 안에서 R로 string aggregation 되어 있는 데이터 덩어리를 구분자(delimiter)를 기준으로 분리(split) 하고 transpose 해서 R에서 분석하기에 적합한 형태로 데이터 전처리를 해주어야 하는 번거로움이 있습니다. 아래에 (3-1) base 패키지의 strsplit() 함수를 이용한 전처리와, (3-2) data.table 패키지의 tstrsplit() 함수를 이용한 전처리로 나누어서 각각 예시를 들어보았습니다.
PL/R 함수를 SQL editor 에서 짜면서 디버깅을 하려면 input, return type 을 정의해주면서 해야하기 때문에무척 고달플 수 있습니다. 따라서 제일 빠르고 또 정확한 방법은 RStudio 같은 R 전용 IDE에서 샘플 데이터로 R code 에 에러, 버그가 없도록 clean R codes block 을 작성한 후에, 이를 PL/R 코드의 $$ R codes block $$ 안에 추가하는 방식입니다. 노파심에 다시 한번 말씀드리자면, DB 에서 PL/R 코드 돌려가면서 디버깅 하는 것은 고통스러울 수 있으니 R codes 가 정확하게 작동하는 bug-free codes 인지 먼저 명확하게 확인한 후에 PL/R 코드의 $$ ~ $$ 사이에 넣고 실행하기 바랍니다.
3-1. base 패키지의 strsplit() 함수를 이용하여 텍스트 파싱 (text parsing using base package's strsplit() function)
base 패키지 안의 strsplit() 함수를 사용해서 텍스트를 구분자(delimiter)를 기준으로 분리(split) 하고, 이를 do.call 로 "cbind" 함수를 여러번 호출해서 세로로 묶어서 데이터 프레임을 만드는 방식입니다. 아래의 예시처럼 코드가 좀 복잡하고 어렵게 보일 수 있습니다. ㅜ_ㅜ
DB에서 SQL로 string_agg() 함수를 사용하려면 대상이 되는 칼럼을 text로 데이터 유형 변환 (type casting)을 먼저 해주어야 합니다. (아래 예시에서는 integer 형태인 x1, x2 를 x1::text, x2::text 를 사용해 text 형태로 변환 후 string_agg() 적용함)
R strsplit() 함수의 구분자는 DB에서 string_agg() 함수로 aggregation 할 때 사용했던 구분자로 설정해줍니다. (아래 예시에서는 구분자로 수직막대기 '|' 를 사용하였음)
# split bydelimiterand reshape it in a long format
split_func <- function(x){
options(stringsAsFactors = FALSE) # Nottoread strings as factors
df_split <- as.data.frame(
do.call('cbind'
, strsplit(as.character(x)
# setdelimiterwithyours
, split="|"
, fixed=T)))
return (df_split)
}
df <- data.frame(lapply(df_tmp, split_func))
colnames(df) <- c("x1", "x2") # setcolumn names
# convert a datatypefromtexttonumeric
df <- data.frame(sapply(df, as.numeric))
# calculate correlation coefficients
corr_coef <- with(df, cor(x1, x2))
return (corr_coef)
$$language'plr';
-- execute PL/R UDF
select
grp
, test.plr_cor_3(x1_str_agg, x2_str_agg) as corr_coef
from test.string_agg_by_col
orderby grp asc;
3-2. data.table 패키지의 tstrsplit() 함수를 이용하여 텍스트 파싱
(text parsing using data.table package's tstrsplit() function)
data.table 패키지의 tstrsplit() 함수는 strsplit() 함수와 transpose 를 하나로 합쳐놓은 역할을 하는 함수로서, 위의 base 패키지를 사용한 파싱 대비 상대적으로 간편하고 깔끔하며 또 빠릅니다.
data.table 패키지 안의 tstrsplit() 함수를 사용한다고 했으므로 사전에 Greenplum, PostgreSQL DB에 R data.table 패키지를 설치해두어야 합니다(Greenplum의 경우 각 segment node에 모두 설치 필요). 그리고 PL/R 함수 안에서는 library(data.table) 로 패키지를 로딩해주어야 합니다.
R tstrsplit() 함수의 구분자는 DB에서 string_agg() 함수로 aggregation 할 때 사용했던 구분자로 설정해줍니다. (아래 예시에서는 구분자로 수직막대기 '|' 를 사용하였음)
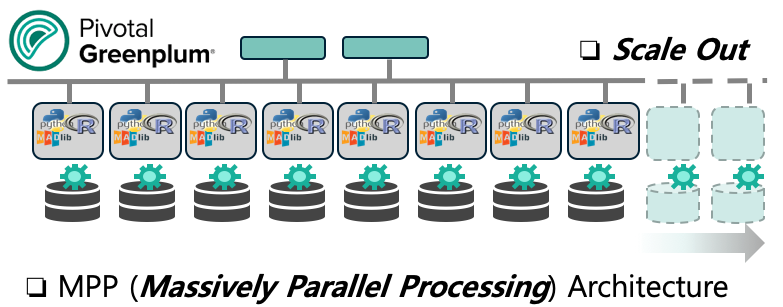
Greenplum Package Manager (gppkg) 유틸리티는 Host와 Cluster에 PL/R 과 의존성있는 패키지들을 한꺼번에 설치를 해줍니다. 또한 gppkg는 시스템 확장이나 세그먼트 복구 시에 자동으로 PL/R extension을 설치해줍니다.
Greenplum PL/R Extention 설치 순서는 아래와 같습니다.
(0) 먼저, Greenplum DB 작동 중이고, source greenplum_path.sh 실행, $MASTER_DATA_DIRECTORY, $GPHOME variables 설정 완료 필요합니다.
psql에서 Greenplum DB 버전을 확인합니다.
psql # sql -c “select version;”
master host에서 gpadmin 계정으로 작업 디렉토리를 만듭니다.
(예: /home/gpadmin/packages)
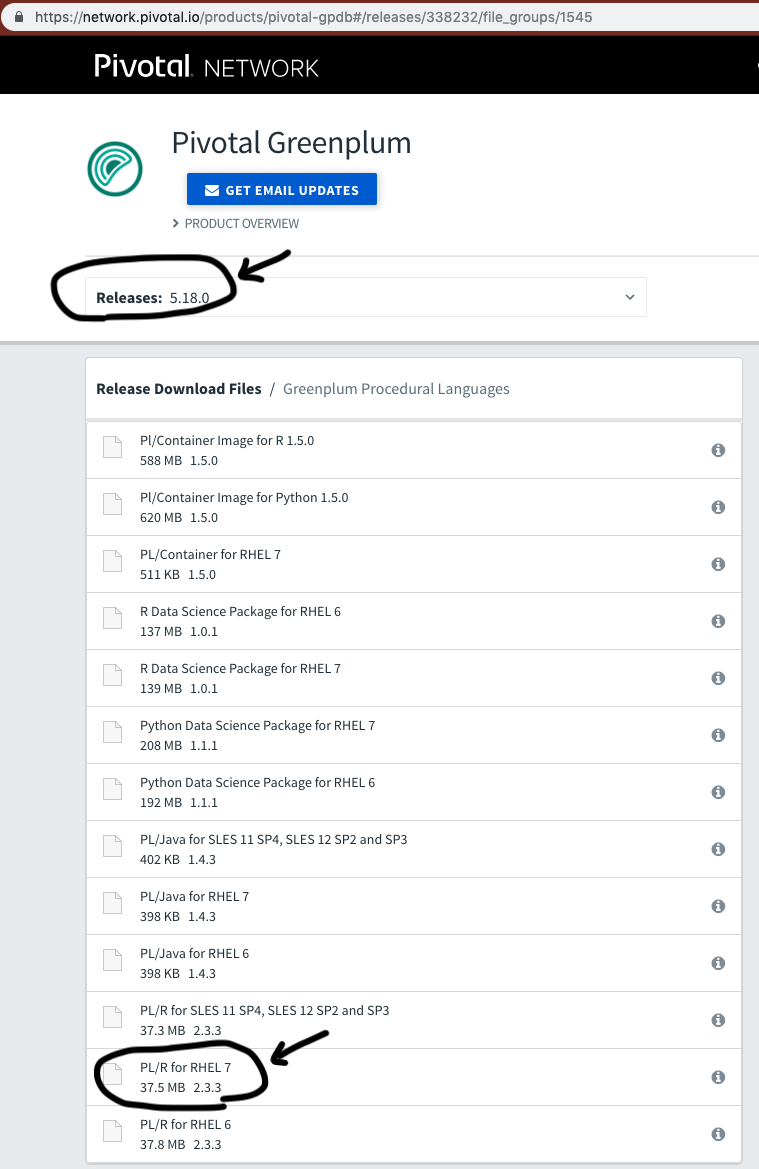
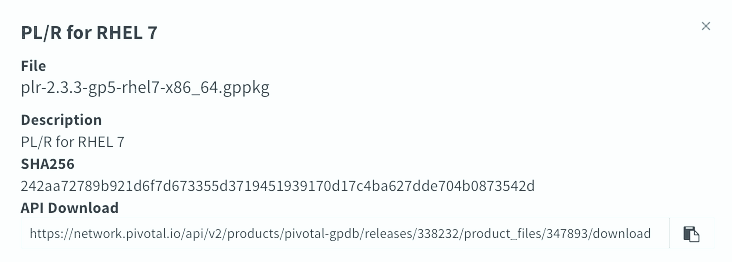
(1) Pivotal Network에서 사용 중인 Greenplum DB version에 맞는 PL/R Extension을 다운로드 합니다.
(예: plr-2.3.3-gp5-rhel7-x86_64.gppkg)
(2) 다운로드 한 PL/R Extension Package를 scp 나 sftp 를 이용해서 Greenplum DB master host로 복사합니다. (아마 회사 정책 상 DBA만 root 권한에 접근 가능한 경우가 대부분일 것이므로, 그런 경우에는 DBA에게 복사/설치 요청을 하셔야 합니다).
명령 프롬프트 창에서 GPDB Docker 에서 압축한 파일을 로커로 복사 후에 ==> 다른 GPDB 서버로 복사하고 압축을 풀어줍니다. (저는 Docker 환경에서 하다보니 좀 복잡해졌는데요, 만약 로컬에서 R 패키지 다운받았으면 로컬에서 바로 GPDB 서버로 복사하면 됩니다. 압축한 R패키지 파일을 scp로 복사하거나 sftp로 업로드할 수 있으며, 권한이 없는 경우 DBA에게 요청하시구요.) 아래는 mdw에서 root 계정으로 시작해서 다운로드해서 압축한 R 패키지 파일을 scp로 /root/packages 경로에 복사하는 스크립트입니다.
-- GPDB Docker에서 압축한 파일을 로컬로 복사하기
-- 다른 명령 프롬프트 창에서 복사해오고 확인하기
ihongdon-ui-MacBook-Pro:Downloads ihongdon$ docker cp gpdb-ds:/home/gpadmin/r-pkg.tar /Users/ihongdon/Downloads/r-pkg.tar
ihongdon-ui-MacBook-Pro:Downloads ihongdon$
ihongdon-ui-MacBook-Pro:Downloads ihongdon$
ihongdon-ui-MacBook-Pro:Downloads ihongdon$ ls -lrt
-rw-rw-r-- 1 ihongdon staff 48107520 4 25 10:52 r-pkg.tar
-- 다른 GPDB 서버로 복사하기
ihongdon-ui-MacBook-Pro:Downloads ihongdon$ scp r-pkg.tar root@mdw:~/package
-- 압축 해제
$ tar -xvf r-pkg.tar
Greenplum DB에 R 패키지를 설치하려면 모든 Greenplum 서버에 R이 이미 설치되어 있어야 합니다.
여러개의 Segments 에 동시에 R 패키지들을 설치해주기 위해서 배포하고자 하는 host list를 작성해줍니다.
# source /usr/local/greenplum-db/greenplum_path.sh
# vi hostfile_packages
vi editor 창이 열리면 아래처럼 R을 설치하고자 하는 host 이름을 등록해줍니다. (1개 master, 3개 segments 예시)
-- vi 편집창에서 --
smdw
sdw1
sdw2
sdw3
~
~
~
esc 누르고 :wq!
명령 프롬프트 창에서 mdw로 부터 root 계정으로 각 노드에 package directory 를 복사해줍니다.
# gpscp -f hostfile_packages -r packages =:/root
hostfile_packages를 복사해서 hostfile_all 을 만들고, mdw를 추가해줍니다.
-- vi 편집창에서 --
mdw
smdw
sdw1
sdw2
sdw3
~
~
~
esc 누르고 :wq!
mdw를 포함한 모든 서버에 R packages 를 설치하는 'R CMD INSTALL r_package_name' 명령문을 mdw에서 실행합니다. (hostfile_all 에 mdw, smdw, sdw1, sdw2, sdw3 등록해놓았으므로 R이 모든 host에 설치됨)
특정 R 패키지를 설치하려고 할 때, 만약 의존성 있는 패키지 (dependencies packages) 가 이미 설치되어 있지 않다면 특정 R 패키지는 설치가 되지 않습니다. 따라서 위의 'R CMD INSTALL r-package-names' 명령문을 실행하면 설치가 되는게 있고, 안되는 것(<- 의존성 있는 패키지가 먼저 설치된 이후에나 설치 가능)도 있게 됩니다. 따라서 이 설치 작업을 수작업으로 반복해서 여러번 돌려줘야 합니다. loop 돌리다보면 의존성 있는 패키지가 설치가 먼저 설치가 될거고, 그 다음에 이전에는 설치가 안되었던게 의존성 있는 패키지가 바로 전에 설치가 되었으므로 이제는 설치가 되고, ...., ....., 다 설치 될때까지 몇 번 더 실행해 줍니다.
이번 포스팅에서는 도커 허브(Docker Hub)에서 Greenplum Database(이하 GPDB)에 MADlib, PL/R, PL/Python이 설치된 Docker Image를 내려받아 분석 환경을 구성하는 방법을 소개하겠습니다.
이번 포스팅에서 소개하는 gpdb-analytics 도커 이미지는 개인이 집이나 회사에서 GPDB로 MADlib, PL/R, PL/Python 사용하면서 테스트해보고 공부할 때 간편하게 사용할 수 있는 용도로 만든 것입니다.
[사전 준비] Dokcer Install
Docker Image를 이용하여 GPDB+분석툴을 설치할 것이므로, 먼저 Docker Hub (https://hub.docker.com/)에서 회원가입을 하고, https://www.docker.com/products/docker-desktop 사이트에서 자신의 OS에 맞는 Docker를 다운로드 받아 설치하시기 바랍니다.
단, Windows OS 사용자의 경우는 (1) Windows 10 Professional or Enterprise 64-bit 의 경우 'Docker CE for Windows'를 다운받아 설치하시구요, 그 이전 버전 혹은 Home Edition 버전 Windows OS 이용하시는 분의 경우는 'Docker Toolbox'를 다운로드 받아서 설치하시기 바랍니다.
[ Docker Hub에서 gpdb-analytics 도커 이미지 내려받아서 GPDB 분석 환경 구성하기 ]
1. Docker Hub에서 gpdb-analytics 도커 이미지 내려받기 (docker pull)
(터미널 사용)
## Docker 이미지 내려 받기
$ docker pull hdlee2u/gpdb-analytics
##Docker 이미지 확인 하기
$ docker images
REPOSITORYTAGIMAGE IDCREATEDSIZE centos7d123f4e55e129 months ago197MB hdlee2u/gpdb-baselatestbfe4e63b8e812 years ago1.17GB
hdlee2u/gpdb-analyticslatest3be773a1a7e1About a minute ago 4.93GB
2. 도커 이미지를 실행하여 Docker Container 를 생성하고, GPDB 분석 환경 시작하기
##Docker 이미지를 실행/5432를 기본 포트로,ssh를2022포트를 사용하여 접근 가능하도록 Docker 컨테이너 생성
sql_magic is Jupyter magic for writing SQL to interact with Greenplum/PostgreSQL database, Hive and Spark. Query results are saved directly to a Pandas dataframe.
# sql_magic package and ext sql_magic to query GPDB
Error response from daemon: driver failed programming external connectivity on endpoint gpdb-ds (d519c381360008f0ac0e8d756e97aeb0538075ee1b7e35862a0eaedf887181f1): Error starting userland proxy: Bind for 0.0.0.0:5432 failed: port is already allocated