[NLP] 언어 구조의 구성 요소 (Building Blocks of Language Structure)
Deep Learning (TF, Keras, PyTorch)/Natural Language Processing 2022. 2. 20. 23:45지난 포스팅에서는 자연어 처리 (NLP: Natural Language Processing) 란 무엇이며, 어디에 사용되는지에 대해서 살펴보았습니다(https://rfriend.tistory.com/738).
이번 포스팅에서는 자연어 처리의 대상이 되는 언어에 대해서 알아보겠습니다. 언어학(linguistics)에서 말하는 언어 구조의 구성요소 관련 용어와 개념을 이해하면 자연어 처리를 공부하는데 큰 도움이 됩니다.
(1) 언어란 무엇인가? (What is language?)
(2) 언어 구조의 구성 요소 (Building Blocks of Language Structure)
: 음소(Phonemes), 형태소 & 어휘항목 (Morphemes & Lexemes), 구문 (Syntax), 문맥 (Context)
(1) 언어란 무엇인가? (What is language?)
언어는 인간이 의사소통에 사용하는 구조화된 시스템입니다. 언어는 말, 제스처, 신호, 또는 글로 표현될 수 있습니다.
미국의 언어학자이자, 철학자, 인지 과학자, 역사가, 사회비평가, 정치운동가이자 저술가이기도 한 현대 언어학의 아버지 에이브럼 노엄 촘스키(Avram Noam Chomsky)는 언어에 대해서 이렇게 말했습니다. 한마디로 '언어'는 겁나 어렵다는 의미같습니다. ^^;
언어는 단순히 단어들이 아닙니다.
그것은 문화, 전통, 공동체의 통일, 공동체가 무엇인지를 만드는 것에 대한 전체 역사입니다.
그것은 모두 언어로 구현되어 있습니다.
- 노암 촘스키

(2) 언어 구조의 구성 요소 (Building Blocks of Language Structure)
: 음소(Phonemes), 형태소 & 어휘항목 (Morphemes & Lexemes), 구문 (Syntax), 문맥 (Context)
아래의 도식은 Sowmya Vajjala, et.al, "Practical Natural Language Processing", O'REILLY (2020) 에서 인용한 'Building Blocks of Language Structure'와 언어의 각 구성요소별 NLP 응용분야를 정리한 것입니다. 음소, 형태소 & 어휘항목, 구문, 문맥 순서대로 하나씩 소개해보겠습니다. (영어 단어가 생소해서 원서로 처음 읽을 때 뭔 소리인가 했어요..)

(2-1) 음소 (Phonemes) : 말과 소리 (Speech & Sounds)
음소(Phonemes)는 언어에서 말과 소리의 가장 작은 단위(the smallest units of sound in a language)입니다. 음소는 그 자체로는 아무런 의미도 없지만, 다른 음소들과 함께 사용이 되면 의미를 가지게 될 수 있습니다.[1] 음운론(Phonology)과 언어학(Linguistics)에서 음소는 특정 언어에서 한 단어와 다른 단어를 구별할 수 있는 소리의 단위입니다.[2]
아래는 영어와 한글의 음소 예시예요. 영어에는 44개의 다른 소리의 음소가 있고, 한글에는 14개의 자음과 10개의 모음 소리의 음소가 있습니다.
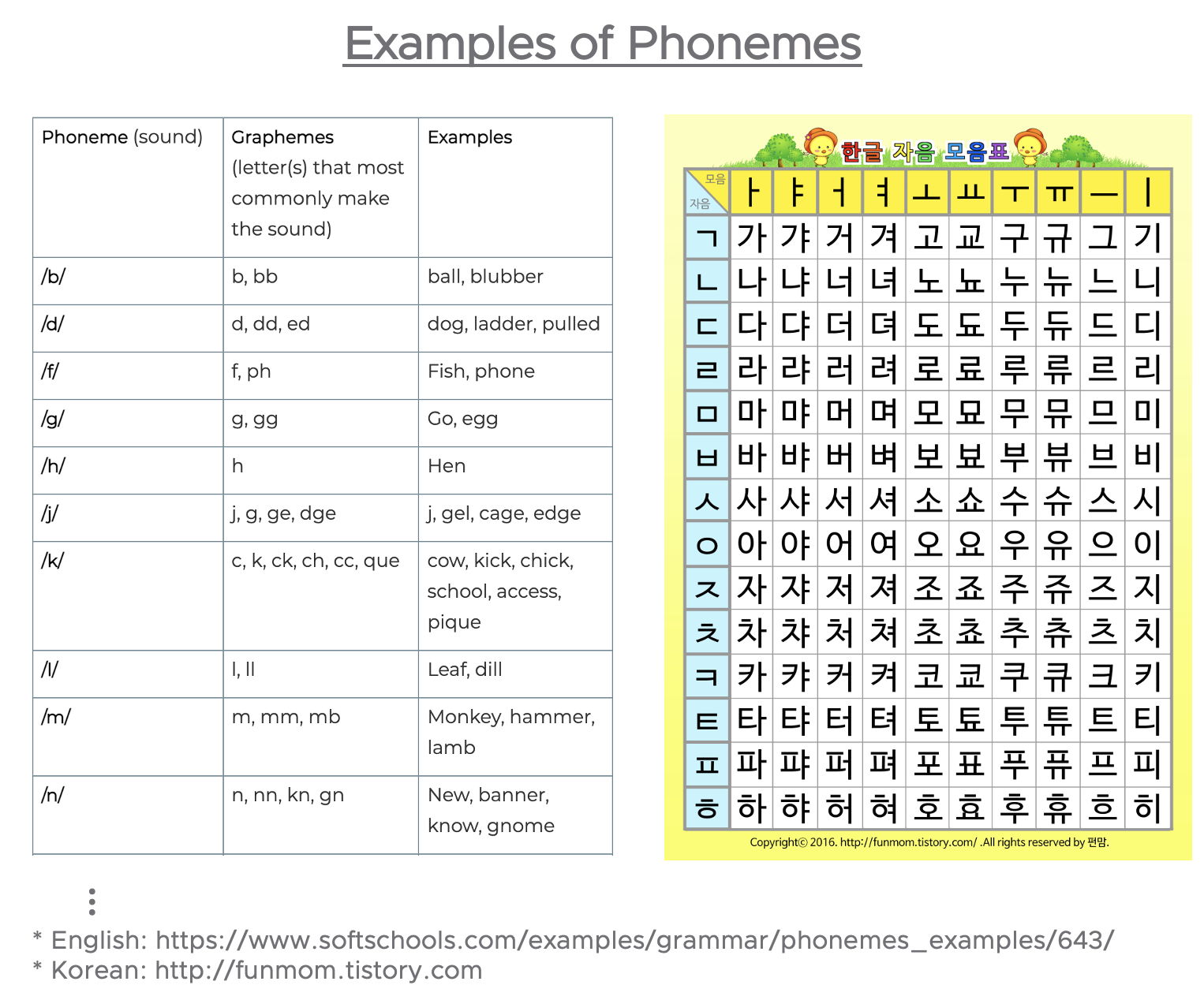
음소(Phonemes)는 말을 글로 변환하기(Speech to Text), 글을 말로 변환하기(Text to Speech), 화자 파악하기 (Speaker Identification) 등의 영역에 활용이 됩니다.
(2-2) 형태소 & 어휘 항목 (Morphemes & Lexemes) : 단어 (Words)
형태소(Morphemes) 는 의미를 가지는 언어의 가장 작은 단위(the smallest unit of language) 이며, 음소(phonemes)의 조합을 통해서 만들어집니다.[1] 형태소는 단어(Words)처럼 보이기는 하지만, 그렇다고 행태소가 곧 단어는 아닙니다. 형태소와 단어의 차이점은, 형태소는 홀로 사용될 수 없지만, 단어는 그 정의상 항상 홀로 자기완결적으로 사용될 수 있다는 점입니다.[3]
아래 예에서는 영어 단어를 형태소로 분리해본 것인데요, 아무래도 예를 보는 것이 형태소를 이해하는데 직관적으로 와 닿을것 같습니다. (예: running => run + nning, books => book + s, unreadable => un+read+able, readability => read+able+ity) unreadable 에서 접두사 'un'이나 접미사 'able'은 모두 형태소로서, 단어의 뜻을 바꾸어줍니다.
[ 단어에서 형태소 분리 예시 (examples of morphemes in words) ]

어휘항목(Lexemes) 또는 어휘소는 의미에 의해서 서로 관련되어 있는 형태소의 구조적인 변형(the structural variations of morphemes related to one another by meaning)입니다.[1] 어휘항목(어휘소)는 변형을 통해 관련되는 단어들의 기초가 되는 어휘적 의미의 단위입니다. 어근 단어(root word)에 의해 대략적으로 일치하는 형태소 분석의 단위인 기본 추상적 의미 단위입니다.[4] (위키피디아 번역하려니 쉽지가 않네요. -,-;) 예를 들어, 영어에서 Run, Runs, Ran, Running은 "RUN"으로 표현될 수 있는 동일한 어휘소의 형태입니다. 예를 보면 금방 이해가 될 것 같습니다.
[ 어휘항목(어휘소, Lemexmes) 예시 ]

형태소와 어휘소는 토큰화(Tokenization), 단어 임베팅(Word Embedding), 형태소(품사) 분석(POS Tagging: Part-Of-Speech Tagging) 등의 영역에 사용됩니다.
(2-3) 구문 (Syntax) : 문장 (Phrases & Sentences)
언어학에서 구문론(Syntax)은 단어(Words)와 형태소(Morphemes)가 어떻게 결합되어 구(Phrases)나 문장(Sentences)과 같은 더 큰 단위를 형성하는지 연구하는 학문입니다. 구문론의 중심 관심사는 어순(Word Order), 문법적 관계(Grammatical Relations), 계층적 문장 구조(구성)(Hierarchical Sentence Structure, Constituency), 교차 언어적 변형의 특성(the nature of crosslinguistic variation), 형태와 의미 사이의 관계(the relationship between form and meaning)를 포함합니다. 구문론에는 중심 가정과 목표가 다른 수많은 접근법이 있습니다.[5]
언어학에서 구문론적인 구조는 많은 다양한 형태로 제시될 수 있습니다. 그중에서 문장을 표현하는 일반적인 방법으로 'a Parse Tree' 이 있습니다. Parse Tree는 언어의 계층적 구조(a hierarchical structure of language)를 가지고 있으며, 아래의 예시에서 보는 바와 같이, 제일 밑에는 단어(words), 그 위에는 형태소(품사) 태깅(POS tagging, Part-Of-Speech Tagging), 그 위에는 구(phrase), 제일 위에는 문장(sentence)으로 하여 계층적 구조를 시각화해서 나타내줍니다.[1]
[ A Parse Tree 예시 ]
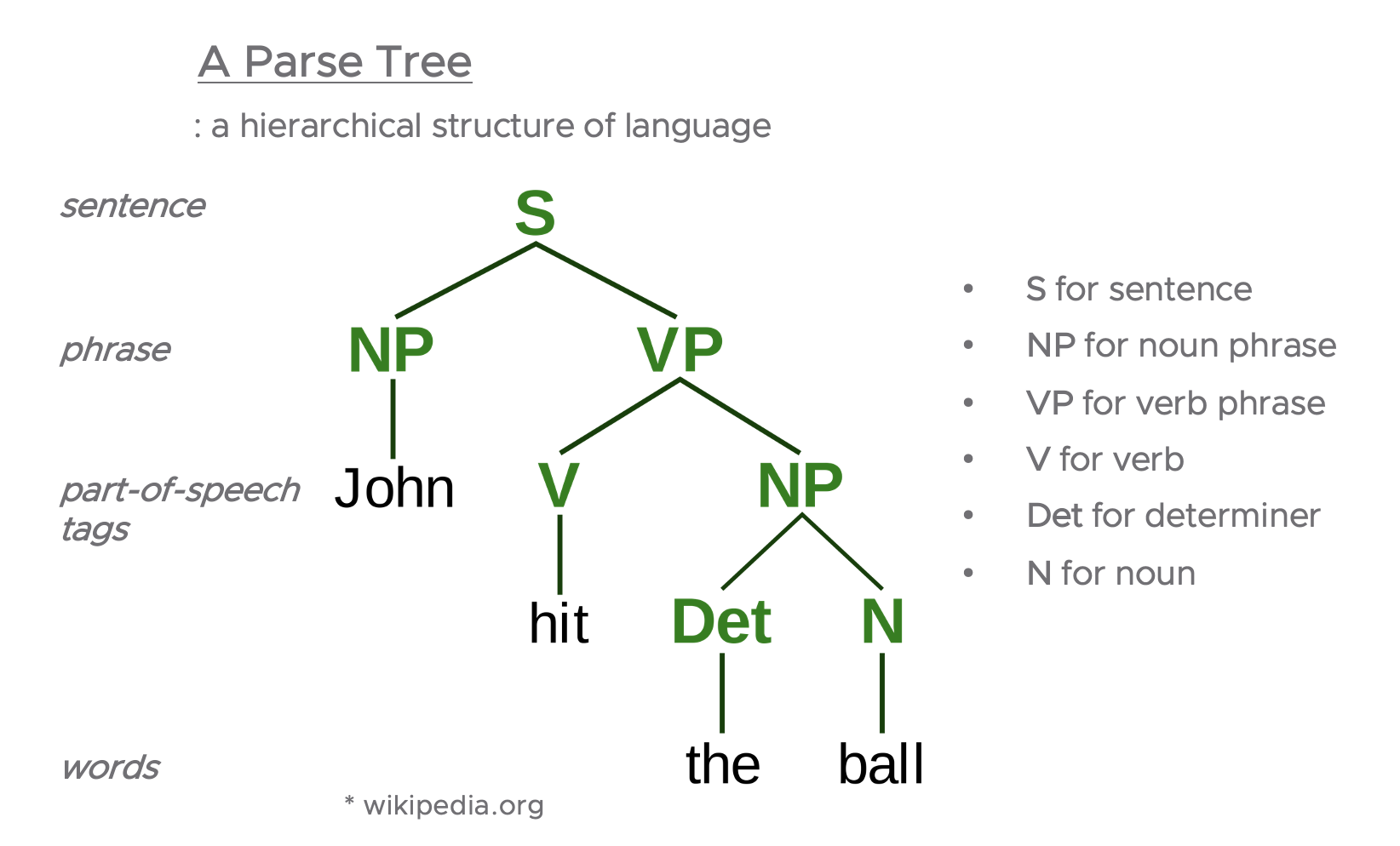
* image: wikipedia.org
언어학의 구문론(Syntax)은 파싱(Parsing), 객체 추출(Entity Extraction), 관계 추출(Relation Extraction)에 사용됩니다.
(2-4) 문맥 (Context) : 의미 (Meaning)
문맥(Context)은 언어의 사용, 언어의 변화, 대화/문장의 요약에 영향을 미치는 의사소통 상황과 관련된 제약을 말합니다.[6] 문맥은 언어의 각 요소들이 합쳐져서 특정 의미(meaning)를 가지고 만드는 것과 관련이 있습니다. 문맥은 단어와 구문의 문자 그대로의 의미(literal meaning of words and phrases)와 함께 장기간의 참조(long-term references), 세계 지식(world knowledge), 상식(common sense)을 포함한다. 문장의 의미는 문맥에 따라 달라질 수 있는데, 이는 단어와 구절이 때로는 여러 의미를 가질 수 있기 때문입니다.[1].
바로 언어의 이런 문맥이 가지는 특성 때문에 상식을 배우지 못하는 기계 번역이 굉장히 어려운 과제인 것입니다. 사람도 문맥을 잘 파악하지 못하면 엉뚱하게 해석해서 곤란한 경우가 자주 있는데, 인공지능이라고 예외는 아니겠죠.

문맥은 문서 요약(Summarization), 토픽 모델링(Topic Modeling), 감성분석(Sentiment Analysis), 냉소적인 표현 탐지(Sarcasm Detection) 등의 분야에 활용됩니다.
이상으로 언어 구조의 구성요소로서 음소(Phonemes), 형태소와 어휘소(Morphemes & Lexemes), 구문(Syntax), 문맥(Context) 에 대한 소개를 마치겠습니다. (저는 언어학 전공이 아닌지라 공부하면서 번역하는데 용어가 좀 어려웠습니다. ㅋ)
[ Reference ]
[1] Sowmya Vajjala el.al., "Practical Natural Language Processing: A Comprehensive Guide to Building Real-World NLP Systems", O'REILLY (2020)
[2] Phonemes (Wikipedia): https://en.wikipedia.org/wiki/Phoneme
[3] Morphemes (Wikipedia): https://en.wikipedia.org/wiki/Morpheme
[4] Lexemes (Wikipedia): https://en.wikipedia.org/wiki/Lexeme
[5] Syntax (Wikipedia): https://en.wikipedia.org/wiki/Syntax
[6] Context (Wikipedia): https://en.wikipedia.org/wiki/Context
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)

'Deep Learning (TF, Keras, PyTorch) > Natural Language Processing' 카테고리의 다른 글
| [Python] 텍스트 데이터 전처리 및 토큰화 (Tokenization) (0) | 2022.08.01 |
|---|---|
| [NLP] TF-IDF (Term Frequency - Inverse Document Frequency) (2) | 2022.04.10 |
| [NLP] 자연어 처리(NLP, Natural Language Processing)란 무엇이고, NLP 응용분야는 무엇이 있나? (0) | 2022.02.20 |
| [Python] 텍스트로부터 CSR 행렬을 이용하여 Term-Document 행렬 만들기 (0) | 2020.09.13 |
| [Python] NLTK(Natural Language Toolkit)와 WordNet으로 자연어 처리하기 맛보기 (0) | 2020.08.02 |



