[R data.table] 그룹 별 선형회귀모형 적합하고 회귀계수 구하기 (Grouped Regression in R data.table)
R 분석과 프로그래밍/R 데이터 전처리 2021. 2. 6. 21:05지난번 포스팅에서는 R data.table 에서 .SD[which.max()], .SD[which.min()] 와 by 를 활용해서 그룹별로 최대값 또는 최소값을 가지는 행을 동적으로 인덱싱(dynamic indexing for the row with maximum or minimum value) 해오는 방법을 소개하였습니다. (rfriend.tistory.com/612)
이번 포스팅에서는 R data.table 에서 그룹별로 선형회귀모형을 적합하고, 적합된 모델로부터 설명변수의 추정 회귀계수를 구하는 방법을 소개하겠습니다.
(1) 선형 회귀모형 적합하고 회귀계수 가져오기 (fitting linear regression model and getting coefficients)
(2) 그룹 별로 적합된 회귀모형의 회귀계수 구하기 (regression coefficients by groups)
(3) 그룹 별로 구한 회귀계수의 히스토그램으로 분포 확인하기 (distribution of group-level coefficients)
(4) 그룹 별 회귀계수를 data.table로 저장하기 (saving coefficients as data.table, lists)

먼저, data.table 패키지를 불러오고, 예제로 사용할 데이터로 Lahman 패키지에 들어있는 야구 투수들의 통계 데이터인 'Pitching' 데이터셋을 data.table 로 참조해서 불러오겠습니다.
library(data.table)
## Lahman database on baseball
#install.packages("Lahman")
library(Lahman)
data("Pitching")
## coerce lists and data.frame to data.table by reference
setDT(Pitching)
str(Pitching)
# Classes 'data.table' and 'data.frame': 47628 obs. of 30 variables:
# $ playerID: chr "bechtge01" "brainas01" "fergubo01" "fishech01" ...
# $ yearID : int 1871 1871 1871 1871 1871 1871 1871 1871 1871 1871 ...
# $ stint : int 1 1 1 1 1 1 1 1 1 1 ...
# $ teamID : Factor w/ 149 levels "ALT","ANA","ARI",..: 97 142 90 111 90 136 111 56 97 136 ...
# $ lgID : Factor w/ 7 levels "AA","AL","FL",..: 4 4 4 4 4 4 4 4 4 4 ...
# $ W : int 1 12 0 4 0 0 0 6 18 12 ...
# $ L : int 2 15 0 16 1 0 1 11 5 15 ...
# $ G : int 3 30 1 24 1 1 3 19 25 29 ...
# $ GS : int 3 30 0 24 1 0 1 19 25 29 ...
# $ CG : int 2 30 0 22 1 0 1 19 25 28 ...
# $ SHO : int 0 0 0 1 0 0 0 1 0 0 ...
# $ SV : int 0 0 0 0 0 0 0 0 0 0 ...
# $ IPouts : int 78 792 3 639 27 3 39 507 666 747 ...
# $ H : int 43 361 8 295 20 1 20 261 285 430 ...
# $ ER : int 23 132 3 103 10 0 5 97 113 153 ...
# $ HR : int 0 4 0 3 0 0 0 5 3 4 ...
# $ BB : int 11 37 0 31 3 0 3 21 40 75 ...
# $ SO : int 1 13 0 15 0 0 1 17 15 12 ...
# $ BAOpp : num NA NA NA NA NA NA NA NA NA NA ...
# $ ERA : num 7.96 4.5 27 4.35 10 0 3.46 5.17 4.58 5.53 ...
# $ IBB : int NA NA NA NA NA NA NA NA NA NA ...
# $ WP : int 7 7 2 20 0 0 1 15 3 44 ...
# $ HBP : int NA NA NA NA NA NA NA NA NA NA ...
# $ BK : int 0 0 0 0 0 0 0 2 0 0 ...
# $ BFP : int 146 1291 14 1080 57 3 70 876 1059 1334 ...
# $ GF : int 0 0 0 1 0 1 1 0 0 0 ...
# $ R : int 42 292 9 257 21 0 30 243 223 362 ...
# $ SH : int NA NA NA NA NA NA NA NA NA NA ...
# $ SF : int NA NA NA NA NA NA NA NA NA NA ...
# $ GIDP : int NA NA NA NA NA NA NA NA NA NA ...
# - attr(*, ".internal.selfref")=<externalptr>
(1) 선형 회귀모형 적합하고 회귀계수 가져오기
(fitting linear regression model and getting coefficients)
data.table의 .SD와 by를 활용한 그룹별 회귀모형에 들어가기 전에, R 코드에 대한 이해를 돕기 위하여 먼저 R로 선형회귀모형을 적합하는 방법을 간단히 소개하겠습니다.
아래 예는 Pitching 데이터셋에 대해 반응변수(response, dependent, target variable) 인 y: ERA 와 설명변수(explanatory, independent, input variable)인 x: ERA (Eearned Run Average, 투수의 방어율 평균자책점) 와의 관계를 선형 회귀모형으로 모델링해보았습니다. R 에서는 lm(y ~ x, data) 의 구문으로 표현합니다.
## -- fitting linear regression with W(Win) on ERA(Earned Run Average)
lm(ERA ~ W, data = Pitching)
# Call:
# lm(formula = ERA ~ W, data = Pitching)
#
# Coefficients:
# (Intercept) W
# 6.0704 -0.2064
lm() 함수로 선형회귀모형을 적합한 결과 객체에서 coef(lm(y ~ x, data)) 로 회귀계수에 접근할 수 있습니다.
## coefficients
coef(lm(ERA ~ W, data = Pitching))
# (Intercept) W
# 6.0704227 -0.2064383
특정 설명변수의 회귀계수만을 가져오고 싶으면 coef(lm(y~x, data))['var_name'] 처럼 설명변수 이름(variable name) 또는 위치(position index)를 사용해서 가져올 수 있습니다. 아래 예에서는 'W' (Win) 설명변수의 회귀계수를 가져온 것입니다.
## coefficient of variable 'W'
coef(lm(ERA ~ W, data = Pitching))['W']
# W
# -0.2064383
(2) 그룹 별로 적합된 회귀모형의 회귀계수 구하기
(regression coefficients by groups)
R로 회귀모형을 적합하고 회귀계수에 접근하는 법을 알았으니, 이제 R data.table에서 그룹별로 선형회귀모형을 적합하는 방법을 소개하겠습니다.
아래 예에서는 팀 그룹별로 ERA(Earned Run Average, 투수 방어율 평균자책점) 와 W (승리 회수) 간의 관계 (즉, 'W'의 회귀계수)가 서로 다를 것이라는 가정 하에,
(1) 팀 그룹 별로 (by = teamID)
(2) 투수 평균자책점(ERA)에 대한 승리 회수(W) 설명변수의 회귀계수를 w_coef 라는 이름으로 저장하는데 ( .(w_coef = coef(lm(ERA ~ W))['W']),
(3) 단, 이때 팀 그룹 별로 관측치 개수가 20개 초과인 경우로 한정(if (.N > 20))해서 구하라.
는 분석 과제입니다.
## -- Grouped Regression
## use the .N > 20 filter to exclude teams with few observations
w_coef <- Pitching[ , if (.N > 20L) .(w_coef = coef(lm(ERA ~ W))['W'])
, by = teamID]
w_coef
# teamID w_coef
# 1: CHN -0.17955149
# 2: CN1 -0.27648701
# 3: BSN -0.17162655
# 4: PRO -0.07482397
# 5: BFN -0.12261226
# 6: CL2 -0.04856038
# 7: DTN -0.09514190
# 8: PT1 -0.11607060
# 9: LS2 -0.14260380
# 10: SL4 -0.03346271
# 11: BL2 -0.11725059
# 12: PH4 -0.20383108
# 13: CN2 -0.12078548
# 14: NY1 -0.13258517
# 15: PHI -0.23418637
# 16: NY4 -0.22204042
# 17: BR3 -0.09991895
# 18: WS8 -0.15919173
# 19: CL3 -0.14955735
# 20: PIT -0.21553344
# 21: IN3 -0.45703062
# 22: CL4 -0.16492015
# 23: CL6 -0.22551150
# 24: BRO -0.28905077
# 25: CIN -0.20696370
# 26: WAS -0.33627146
# 27: SLN -0.19956027
# 28: BLN -0.15588106
# 29: LS3 -0.27273152
# 30: CLE -0.18379506
# 31: PHA -0.22567468
# 32: BOS -0.19749652
# 33: BLA -0.13577391
# 34: CHA -0.20046931
# 35: WS1 -0.28093311
# 36: DET -0.22160152
# 37: SLA -0.24721948
# 38: NYA -0.19447885
# 39: PTF -0.00557913
# 40: BLF -0.17924751
# 41: BUF -0.23175119
# 42: BRF -0.15565687
# 43: ML1 -0.18098399
# 44: BAL -0.25190384
# 45: KC1 -0.38279088
# 46: SFN -0.17945896
# 47: LAN -0.17251290
# 48: MIN -0.24984747
# 49: WS2 -0.25201226
# 50: LAA -0.24018977
# 51: NYN -0.21952677
# 52: HOU -0.23061888
# 53: CAL -0.20546834
# 54: ATL -0.22054211
# 55: OAK -0.19635645
# 56: SE1 -0.43530805
# 57: SDN -0.24318779
# 58: KCA -0.25287613
# 59: MON -0.33188681
# 60: ML4 -0.20159841
# 61: TEX -0.25846034
# 62: SEA -0.24887196
# 63: TOR -0.28199100
# 64: COL -0.32371519
# 65: FLO -0.34167152
# 66: ANA -0.09909373
# 67: ARI -0.31041121
# 68: TBA -0.31435364
# 69: MIL -0.31820497
# 70: MIA -0.32147649
# teamID w_coef
(3) 그룹 별로 구한 회귀계수의 히스토그램으로 분포 확인하기
(distribution of group-level coefficients)
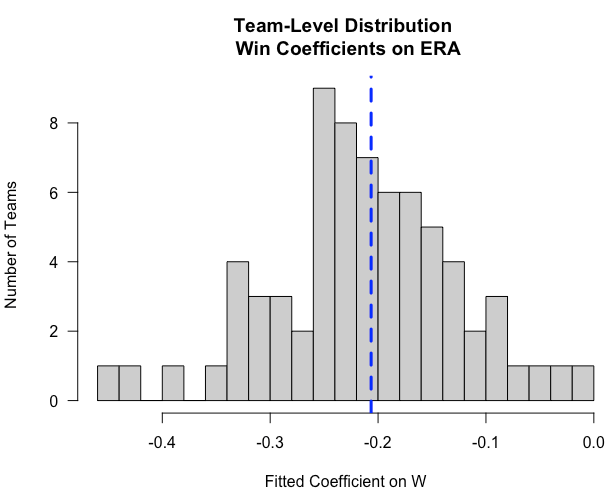
위의 (2)번에서 구한 팀 그룹별 설명변수 'W'에 대한 회귀계수의 분포를 히스토그램을 그려서 확인해 보겠습니다.
또 비교를 위해서 팀 그룹의 구분이 없이 전체 데이터셋을 대상으로 하나의 선형회귀모형을 적합했을 때의 'ERA'에 대한 설명변수 'W'의 회귀계수를 overall_coef 라는 이름으로 구해서 파란색 수직 점선으로 추가해보겠습니다.
## -- Overall coefficient for comparison
overall_coef <- Pitching[ , coef(lm(ERA ~ W))['W']]
overall_coef
# W
# -0.2064383
'ERA'에 대한 설명변수 'W'의 회귀계수는 아래의 히스토그램에서 보는 것처럼 중심을 기준으로 좌우 대칭으로 퍼져있는 정규분포 형태를 띠고 있네요. 위에서 팀 그룹 구분없이 전체 데이터셋에 대해 구한 'W'의 회귀계수 overall_coef 는 중심 부근에 위치하고 있구요.
## Histogram: team-level distribution of Win coefficinets on ERA
hist(w_coef$w_coef, 20L, las = 1L
, xlab = "Fitted Coefficient on W"
, ylab = "Number of Teams"
, main = "Team-Level Distribution \n Win Coefficients on ERA")
## adding vertical line
abline(v = overall_coef, lty = 2L, lwd = 3, col = "blue")
(4) 그룹 별 회귀계수를 data.table로 저장하기
(saving coefficients as data.table, lists)
만약 여러개의 설명변수를 사용하여 그룹별 회귀모형을 적합하고, 각 그룹별 설명변수별 회귀계수를 모두 포괄하여 추정된 회귀계수들 결과를 data.table 로 저장하려면 아래 예의 Pitching[ , as.list(coef(lm(ERA ~ W + R))), by = teamID] 와 같이 as.list() 로 회귀계수를 반환해주면 됩니다.
## making regression's coefficients as lists
coef_dt <- Pitching[ , if (.N > 100L) as.list(coef(lm(ERA ~ W + R)))
, by = teamID]
coef_dt
# teamID (Intercept) W R
# 1: CHN 5.710833 -0.2327841 0.009008819
# 2: BSN 6.207018 -0.1480406 -0.003578210
# 3: NY1 5.204519 -0.1829990 0.009074176
# 4: PHI 6.288039 -0.2852063 0.008062580
# 5: PIT 5.816353 -0.3000605 0.014409032
# 6: CL4 7.069498 -0.1379608 -0.003896127
# 7: BRO 7.389586 -0.2486108 -0.006551714
# 8: CIN 5.767821 -0.2772234 0.011879565
# 9: WAS 6.992822 -0.4307016 0.012169679
# 10: SLN 5.658827 -0.2652434 0.011129236
# 11: CLE 5.603790 -0.2500250 0.012237163
# 12: PHA 6.688209 -0.2133816 -0.002355098
# 13: BOS 5.796617 -0.2486252 0.009668641
# 14: CHA 5.646432 -0.2873486 0.015712714
# 15: WS1 7.232626 -0.2110688 -0.011945155
# 16: DET 6.277144 -0.2542801 0.005730178
# 17: SLA 6.347031 -0.2954950 0.007275831
# 18: NYA 5.697457 -0.2596195 0.012947058
# 19: ML1 5.854472 -0.1546460 -0.005409552
# 20: BAL 6.164851 -0.3403211 0.016795283
# 21: KC1 7.266172 -0.3501301 -0.004535116
# 22: SFN 5.198861 -0.2817773 0.019011014
# 23: LAN 4.935047 -0.2974111 0.025402053
# 24: MIN 6.189153 -0.3409982 0.016008137
# 25: WS2 5.387437 -0.3462016 0.015272805
# 26: LAA 5.789238 -0.3530398 0.020938732
# 27: NYN 5.498020 -0.2827097 0.012036711
# 28: HOU 5.672472 -0.3028138 0.013698871
# 29: CAL 5.539583 -0.2999446 0.016522022
# 30: ATL 5.656437 -0.3144744 0.017429243
# 31: OAK 5.397168 -0.3234133 0.024444877
# 32: SDN 5.491807 -0.3883997 0.024155811
# 33: KCA 6.056765 -0.3851321 0.022070084
# 34: MON 6.564910 -0.3598835 0.005035261
# 35: ML4 5.586930 -0.3250744 0.019599030
# 36: TEX 6.246584 -0.3922595 0.021545179
# 37: SEA 6.111932 -0.3346116 0.014231822
# 38: TOR 6.528287 -0.3587363 0.013046643
# 39: COL 6.966675 -0.4478508 0.018163225
# 40: FLO 6.648690 -0.4681611 0.020578927
# 41: ANA 4.825658 -0.3218342 0.033327670
# 42: ARI 6.694492 -0.3594938 0.009086247
# 43: TBA 6.355612 -0.4242187 0.018274852
# 44: MIL 6.340569 -0.4942962 0.027135468
# 45: MIA 5.629828 -0.4644679 0.025092579
# teamID (Intercept) W R
[ Reference ]
* R data.table vignettes 'Using .SD for Data Analysis'
: cran.r-project.org/web/packages/data.table/vignettes/datatable-sd-usage.html
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)

728x90
반응형
'R 분석과 프로그래밍 > R 데이터 전처리' 카테고리의 다른 글
| [R data.table] 자동 인덱싱(Auto indexing)을 통한 빠른 탐색과 Subsetting (0) | 2021.02.11 |
|---|---|
| [R data.table] 2차 인덱스 (secondary indices) 를 활용한 빠른 탐색 기반 Subsetting (0) | 2021.02.07 |
| [R data.table] 그룹별 최소값 행, 최대값 행 가져오기 (Group Optima) (0) | 2021.01.31 |
| [R data.table] .SD[], by를 사용해 그룹별로 부분집합 가져오기 (Group Subsetting) (0) | 2021.01.31 |
| [R data.table] 조건이 있는 상태에서 Key를 기준으로 데이터셋 합치기 (Conditional Joins) (0) | 2021.01.31 |



