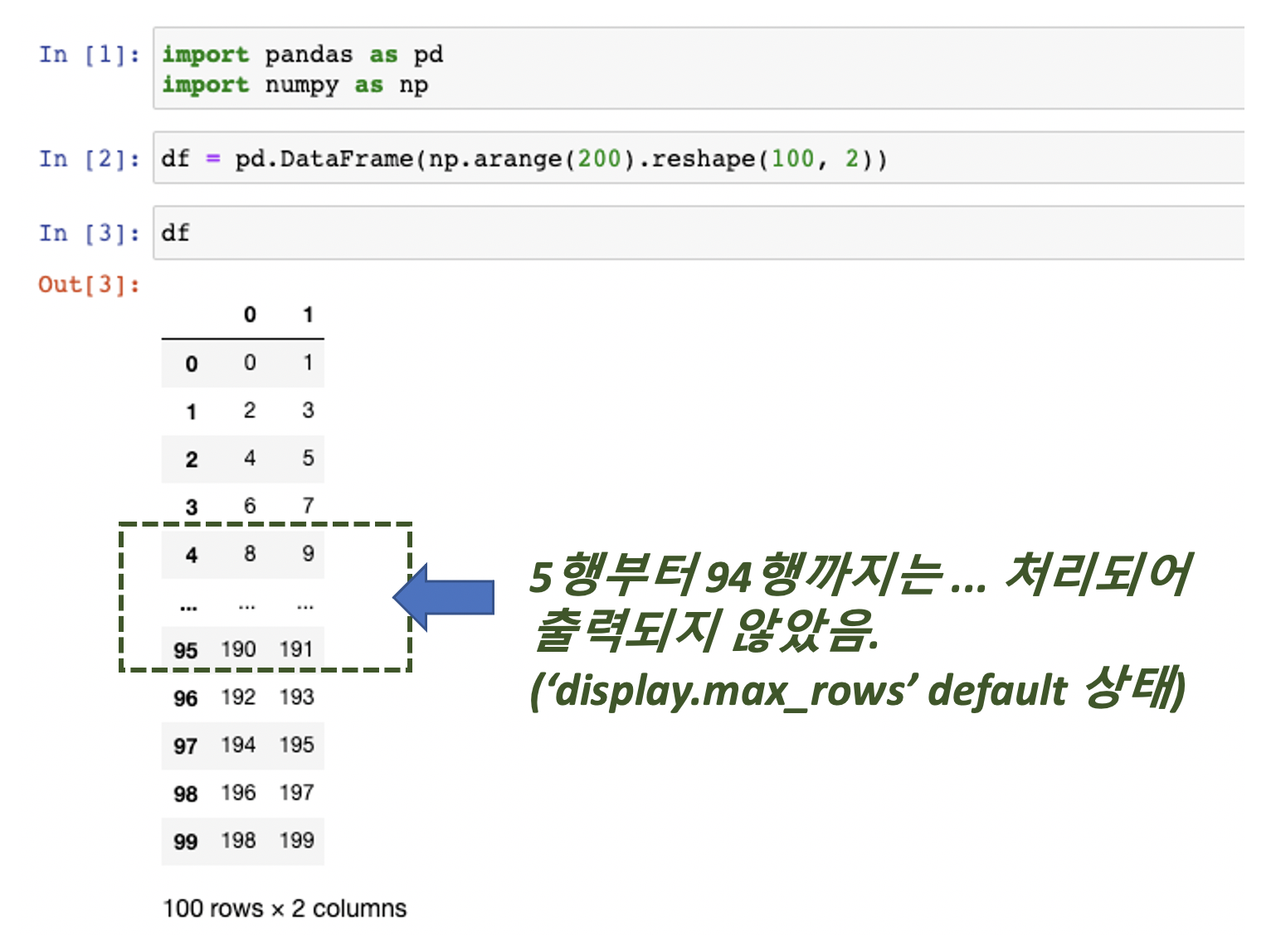
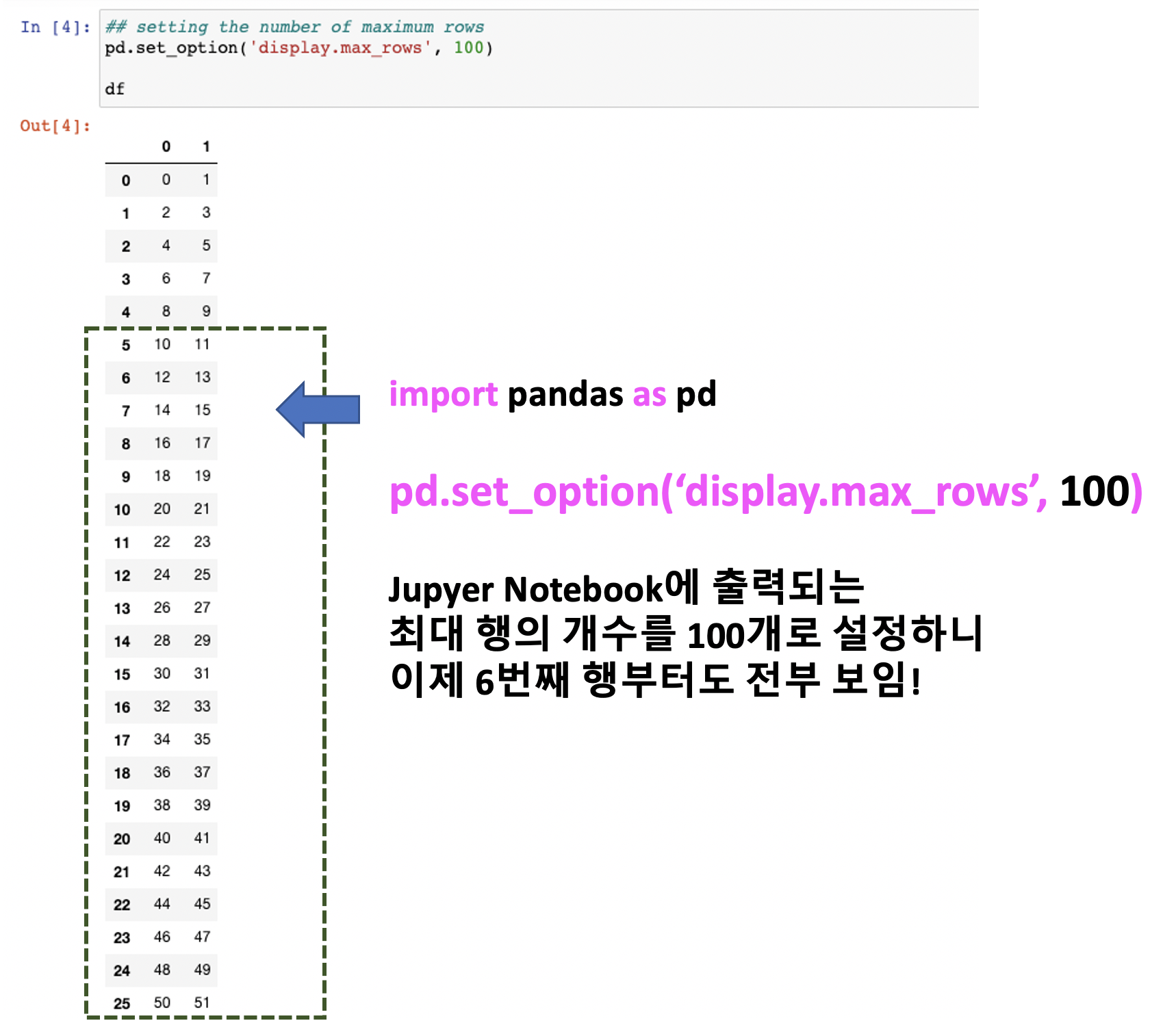
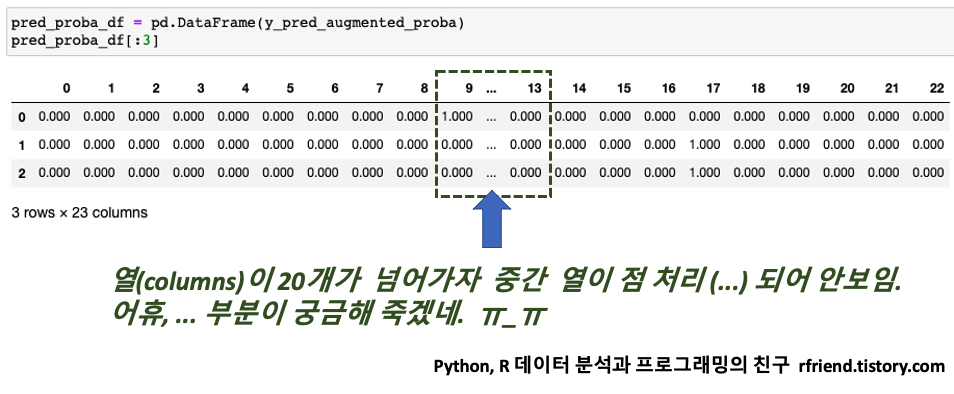
[Python pandas] Series, DataFrame에서 시계열 데이터 indexing, slicing, 조회하기
Python 분석과 프로그래밍/Python 데이터 전처리 2019. 12. 23. 18:41지난번 포스팅에서는 날짜-시간 시계열 객체(date-time, Timeseries objects)를 문자열(Strings)로 변환하기, 거꾸로 문자열을 날짜-시간 시계열 객체로 변환하는 방법(https://rfriend.tistory.com/498)을 소개하였습니다.
이번 포스팅에서는 날짜-시간 시계열 데이터(date-time time series)를 index로 가지는 Python pandas의 Series, DataFrame 에서 특정 날짜-시간을 indexing, slicing, selection, truncation 하는 방법을 소개하겠습니다.
(1) pandas Series에서 시계열 데이터 indexing, slicing, selection, truncation 하는 방법
(2) pandas DataFrame에서 시계열 데이터 indexing, slicing, selection, truncation 하는 방법

(1) pandas Series에서 시계열 데이터 indexing, slicing, selection, truncation 하는 방법 |
먼저, 간단한 예제로 사용하도록 2019년 11월 25일 부터 ~ 2019년 12월 4일까지 10일 기간의 년-월-일 날짜를 index로 가지는 pands Series를 만들어보겠습니다.
pandas.date_range(시작날짜, periods=생성할 날짜-시간 개수) 함수를 사용하여 날짜-시간 데이터를 생성하였으며, 이를 index로 하여 pandas Series를 만들었습니다.
import pandas as pd from datetime import datetime # DatetimeIndex ts_days_idx = pd.date_range('2019-11-25', periods=10) ts_days_idx
# Series with time series index series_ts = pd.Series(range(len(ts_days_idx)) , index=ts_days_idx) series_ts [Out]:2019-11-25 0
2019-11-26 1
2019-11-27 2
2019-11-28 3
2019-11-29 4
2019-11-30 5
2019-12-01 6
2019-12-02 7
2019-12-03 8
2019-12-04 9
Freq: D, dtype: int64series_ts.index [Out]: DatetimeIndex(['2019-11-25', '2019-11-26', '2019-11-27', '2019-11-28',
'2019-11-29', '2019-11-30', '2019-12-01', '2019-12-02',
'2019-12-03', '2019-12-04'],
dtype='datetime64[ns]', freq='D')series_ts.index[6] [Out]: Timestamp('2019-12-01 00:00:00', freq='D') |
참고로, 아례의 예처럼 pd.date_range(start='시작 날짜-시간', end='끝 날짜-시간') 처럼 명시적으로 시작과 끝의 날짜-시간을 지정해주어도 위의 perieds를 사용한 예와 동일한 결과를 얻을 수 있습니다.
import pandas as pd pd.date_range(start='2019-11-25', end='2019-12-04') [Out]:DatetimeIndex(['2019-11-25', '2019-11-26', '2019-11-27', '2019-11-28', '2019-11-29', '2019-11-30', '2019-12-01', '2019-12-02', '2019-12-03', '2019-12-04'], dtype='datetime64[ns]', freq='D') |
참고로 하나더 소개하자면요, pandas.date_range('시작날짜-시간', period=생성할 날짜-시간 개수, freq='주기 단위') 에서 freq 옵션을 통해서 'S' 1초 단위, '10S' 10초 단위, 'H' 1시간 단위, 'D' 1일 단위, 'M' 1달 단위(월 말일 기준), 'Y' 1년 단위 (년 말일 기준) 등으로 날짜-시간 시계열 데이터 생성 주기를 설정할 수 있습니다. 매우 편하지요?!
< 1초 단위로 날짜-시간 데이터 10개를 생성한 예 >
# 10 timeseries data points by Second(freq='S') pd.date_range('2019-11-25 00:00:00', periods=10, freq='S') [Out]: DatetimeIndex(['2019-11-25 00:00:00', '2019-11-25 00:00:01', '2019-11-25 00:00:02', '2019-11-25 00:00:03', '2019-11-25 00:00:04', '2019-11-25 00:00:05', '2019-11-25 00:00:06', '2019-11-25 00:00:07', '2019-11-25 00:00:08', '2019-11-25 00:00:09'], dtype='datetime64[ns]', freq='S') |
< 10초 단위로 날짜-시간 데이터 10개를 생성한 예 >
# 10 timeseries data points by 10 Seconds (freq='10S') pd.date_range('2019-11-25 00:00:00', periods=10, freq='10S')
|
(1-1) 시계열데이터를 index로 가지는 pandas Series에서 특정 날짜-시간 데이터 indexing 하기
먼저 위에서 생성한 series_ts 라는 이름의 시간 순서대로 정렬되어 있는 Series 에서 7번째에 위치한 '2019-12-01' 의 값 '6'을 indexing 해보겠습니다.
(a), (b)와 같이 위치(position)를 가지고 인덱싱할 수 있습니다.
또한, (c), (d)와 같이 날짜-시간 문자열(String)을 가지고도 인덱싱(indexing)을 할 수 있습니다.
(e) 처럼 datetime.datetime(year, month, day) 객체를 사용해서도 인덱싱할 수 있습니다.
import pandas as pd from datetime import datetime # (a) indexing with index number series_ts[6] [Out]: 6# (b) indexing with index number using iloc series_ts.iloc[6]
# (c) indexing with string ['year-month-day'] series_ts['2019-12-01'] [Out]: 6# (d) indexing with string ['month/day/year'] series_ts['12/01/2019'] [Out]: 6# (f) indexing with datetime.datetime(year, month, day) series_ts[datetime(2019, 12, 1)] [Out]: 6 |
(1-2) 시계열데이터를 index로 가지는 pandas Series에서 날짜-시간 데이터 Slicing 하기
아래는 '2019-12-01' 일 이후의 값을 모두 slicing 해오는 5가지 방법입니다.
(a), (b)는 위치(position):위치(position)을 이용하여 날짜를 index로 가지는 Series를 slicing을 하였습니다.
(c), (d)는 '년-월-일':'년-월-일' 혹은 '월/일/년':'월/일/년' 문자열(string)을 이용하여 slicing을 하였습니다.
(e)는 datetime.datetime(년, 월, 일):datetime.datetime(년, 월, 일) 을 이용하여 slicing을 하였습니다.
import pandas as pd from datetime import datetime # (a) slicing with position series_ts[6:] [Out]:2019-12-01 6
2019-12-02 7
2019-12-03 8
2019-12-04 9
Freq: D, dtype: int64# (b) slicing with position using iloc series_ts.iloc[6:] [Out]:2019-12-01 6
2019-12-02 7
2019-12-03 8
2019-12-04 9
Freq: D, dtype: int64# (c) slicing with string series_ts['2019-12-01':'2019-12-10'] [Out]:2019-12-01 6
2019-12-02 7
2019-12-03 8
2019-12-04 9
Freq: D, dtype: int64# (d) slicing with string series_ts['12/01/2019':'12/10/2019'] [Out]:2019-12-01 6
2019-12-02 7
2019-12-03 8
2019-12-04 9
Freq: D, dtype: int64# (e) slicing with datetime series_ts[datetime(2019, 12, 1):datetime(2019, 12, 10)] [Out]: 2019-12-01 6
2019-12-02 7
2019-12-03 8
2019-12-04 9
Freq: D, dtype: int64 |
(1-3) 시계열데이터를 index로 가지는 pandas Series 에서 날짜-시간 데이터 Selection 하기
'날짜-시간' 문자열(String)을 이용하여 특정 '년', '월'의 모든 데이터를 선택할 수도 있습니다. 꽤 편리하고 재미있는 기능입니다.
< '2019'년 모든 데이터 선택하기 예 >
# selection with year string series_ts['2019']
|
< '2019년 12월' 모든 데이터 선택하기 예 >
# selection with year-month string series_ts['2019-12'] [Out]:2019-12-01 6
2019-12-02 7
2019-12-03 8
2019-12-04 9
Freq: D, dtype: int64
|
(1-4) 시계열 데이터를 index로 가지는 pandas Series에서 날짜-시간 데이터 잘라내기 (Truncate)
truncate() methods를 사용하면 잘라내기(truncation)를 할 수 있습니다. before, after 옵션으로 잘라내기하는 범위 기간을 설정할 수 있는데요, 해당 날짜 포함 여부를 유심히 살펴보기 바랍니다.
< '2019년 12월 1일' 이전(before) 모든 데이터 잘라내기 예 >
('2019년 11월 30일'까지의 모든 데이터 삭제하며, '2019-12-01'일 데이터는 남아 있음)
# truncate before series_ts.truncate(before='2019-12-01') [Out]:2019-12-01 6 2019-12-02 7 2019-12-03 8 2019-12-04 9 Freq: D, dtype: int64
|
< '2019년 11월 30일' 이후(after) 모든 데이터 잘라내기 예 >
(''2019년 12월 1일' 부터의 모든 데이터 삭제하며, '2019-11-30'일 데이터는 남아 있음)
# truncate after series_ts.truncate(after='2019-11-30') [Out]:2019-11-25 0 2019-11-26 1 2019-11-27 2 2019-11-28 3 2019-11-29 4 2019-11-30 5 Freq: D, dtype: int64
|
(2) pandas DataFrame에서 시계열 데이터 indexing, slicing, selection, truncation 하는 방법 |
위의 (1)번에서 소개했던 pandas Series의 시계열 데이터 indexing, slicing, selection, truncation 방법을 동일하게 pandas DataFrame에도 사용할 수 있습니다.
년-월-일 날짜를 index로 가지는 간단한 pandas DataFrame 예제를 만들어보겠습니다.
import pandas as pd from datetime import datetime # DatetimeIndex ts_days_idx = pd.date_range('2019-11-25', periods=10) ts_days_idx [Out]:DatetimeIndex(['2019-11-25', '2019-11-26', '2019-11-27', '2019-11-28',
'2019-11-29', '2019-11-30', '2019-12-01', '2019-12-02',
'2019-12-03', '2019-12-04'],
dtype='datetime64[ns]', freq='D')# DataFrame with DatetimeIndex df_ts = pd.DataFrame(range(len(ts_days_idx)) , columns=['col'] , index=ts_days_idx) df_ts
|
(2-1) 시계열데이터를 index로 가지는 pandas DataFrame에서 특정 날짜-시간 데이터 indexing 하기
위의 (1-1) Series indexing과 거의 유사한데요, DataFrame에서는 df_ts[6], df_ts[datetime(2019, 12, 1)] 의 두가지 방법은 KeyError 가 발생해서 사용할 수 없구요, 아래의 3가지 방법만 indexing에 사용 가능합니다.
(a) iloc[integer] 메소드를 사용하여 위치(position) 로 indexing 하기
(b), (c) loc['label'] 메소드를 사용하여 이름('label')로 indexing 하기
# (a) indexing with index position integer using iloc[] df_ts.iloc[6] [Out]:col 6
Name: 2019-12-01 00:00:00, dtype: int64# (b) indexing with index labels ['year-month-day'] df_ts.loc['2019-12-01'] [Out]:col 6
Name: 2019-12-01 00:00:00, dtype: int64# (c) indexing with index labels ['month/day/year'] df_ts.loc['12/01/2019'] [Out]:col 6
Name: 2019-12-01 00:00:00, dtype: int64 |
(2-2) 시계열데이터를 index로 가지는 pandas DataFrame에서 날짜-시간 데이터 Slicing 하기
아래는 '2019-12-01' 일 이후의 값을 모두 slicing 해오는 4가지 방법입니다.
(a) 위치(position):위치(position)을 이용하여 날짜를 index로 가지는 Series를 slicing을 하였습니다.
(b), (c)는 loc['년-월-일']:loc['년-월-일'] 혹은 loc['월/일/년']:loc['월/일/년'] 문자열(string)을 이용하여 slicing을 하였습니다.
(d) 는 loc[datetime.datetime(year, month, day):datetime.datetime(year, month, day)] 로 slicing을 한 예입니다.
# (a) slicing DataFrame with position integer df_ts[6:10]
# (b) silcing using date strings 'year-month-day' df_ts.loc['2019-12-01':'2019-12-10']
# (c) slicing using date strings 'month/day/year' df_ts.loc['12/01/2019':'12/10/2019']
# (d) slicing using datetime objects from datetime import datetime df_ts.loc[datetime(2019, 12, 1):datetime(2019, 12, 10)]
|
(2-3) 시계열데이터를 index로 가지는 pandas DataFrame 에서 날짜-시간 데이터 Selection 하기
'년', '년-월' 날짜 문자열을 df.loc['year'], df.loc['year-month'] 에 입력하면 해당 년(year), 월(month)의 모든 데이터를 선택할 수 있습니다.
< '2019년'의 모든 데이터 선택 예 >
# selection of year '2019' df_ts.loc['2019'] # df_ts['2019']
|
< '2019년 12월'의 모든 데이터 선택 예 >
# selection of year-month '2019-12' df_ts.loc['2019-12']
|
(2-4) 시계열 데이터를 index로 가지는 pandas DataFrame에서 날짜-시간 데이터 잘라내기 (Truncate)
truncate() 메소드를 사용하면 before 이전 기간의 데이터를 잘라내거나 after 이후 기간의 데이터를 잘라낼 수 있습니다.
< '2019-12-01' 일 이전(before) 기간 데이터 잘라내기 예 >
('2019-12-01'일은 삭제되지 않고 남아 있음)
# truncate before df_ts.truncate(before='2019-12-01') # '2019-12-01' is not removed
|
< '2019-11-30'일 이후(after) 기간 데이터 잘라내기 예 >
('2019-11-30'일은 삭제되지 않고 남아 있음)
# truncate after df_ts.truncate(after='2019-11-30') # '2019-11-30' is not removed
|
많은 도움이 되었기를 바랍니다.
이번 포스팅이 도움이 되었다면 아래의 '공감~ '를 꾹 눌러주세요. :-)
'를 꾹 눌러주세요. :-)