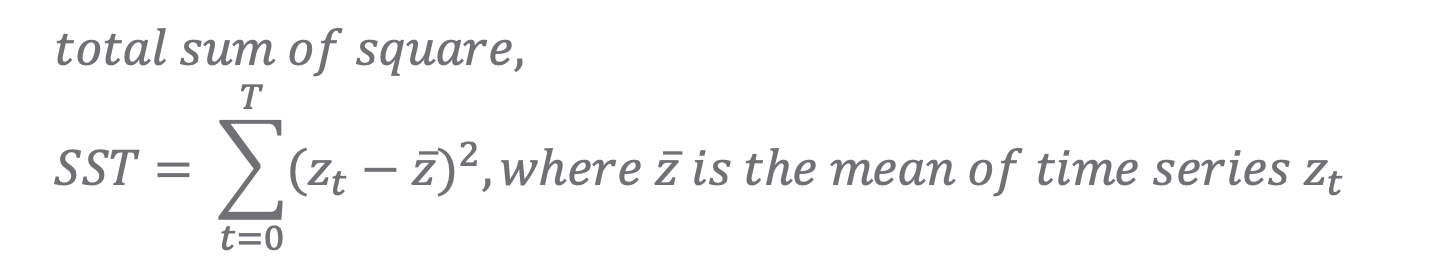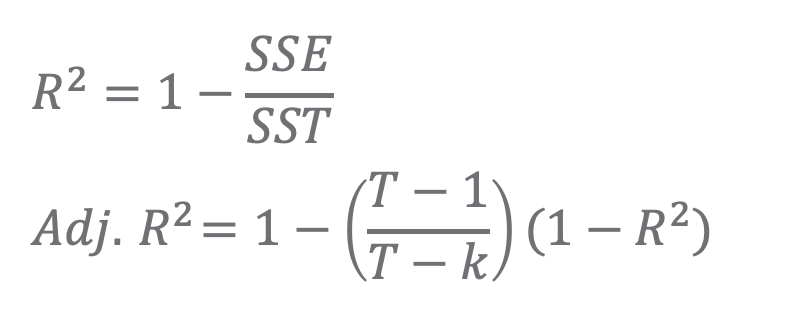예제로 사용할 샘플 데이터셋을 정규분포로부터 난수를 생성해서 100개 샘플을 추출하고, 점 그래프를 그려보겠습니다.
이 기본 점 그래프에 수평선과 수직선을 차례대로 추가해보겠습니다.
import numpy as np
import matplotlib.pyplot as plt
## generating random numbers
np.random.seed(1004)
x = np.random.normal(0, 1, 100)
## plotting the original data
plt.figure(figsize = (10, 6))
plt.plot(x, linestyle='none', marker='o', color='gray')
plt.show()
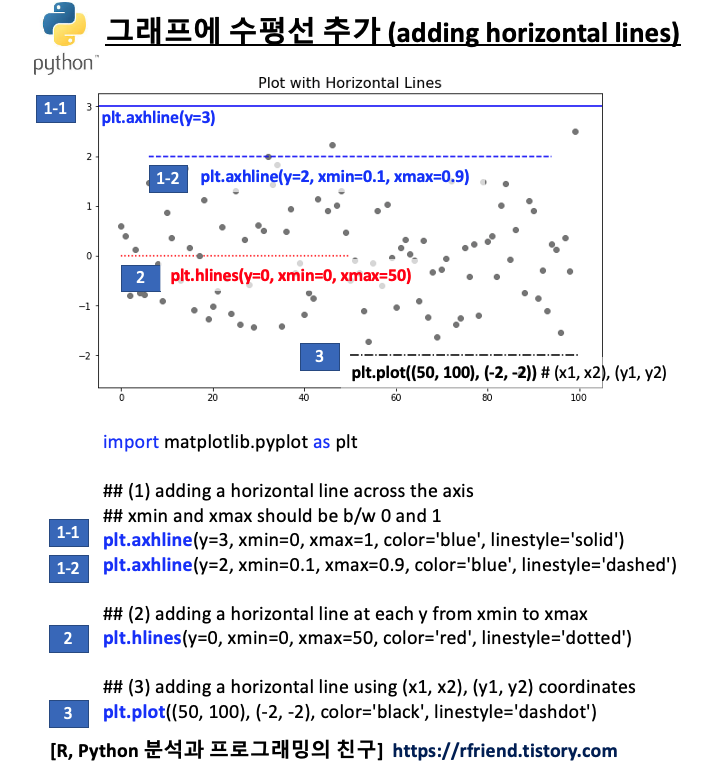
(1) 그래프에 수평선 추가하기 (adding horizontal lines)
(a) plt.axhline(y, xmin, xmax) : 축을 따라서 수평선을 추가, xmin 과 xmax 는 0~1 사이의 값을 가짐
(b) plt.hlines(y, xmin, xmax) : xmin ~ xmax 까지 각 y 값의 수평선을 추가
(c) plt.plot((x1, x2), (y1, y2)) : (x1, x2), (y1, y2) 좌표를 연결하는 선 추가
(a) 번의 plt.axhline() 은 y축에서 부터 수평선이 시작하고, xmin~xmax 로 0~1 사이의 비율 값을 가지는 반면에, (b)번의 plt.hlines() 는 xmin 값 위치에서 부터 수평선이 시작하고, xmin~xmax 값으로 좌표값을 받는다는 차이점이 있습니다.
(c) 번의 plt.plot() 은 단지 수평선, 수직선 뿐만이 아니라 범용적으로 두 좌표를 연결하는 선을 추가할 수 있습니다.
plt.figure(figsize = (10, 6))
plt.plot(x, linestyle='none', marker='o', color='gray')
plt.title("Plot with Horizontal Lines", fontsize=16)
## (1) adding a horizontal line across the axis
## xmin and xmax should be b/w 0 and 1
plt.axhline(y=3, xmin=0, xmax=1, color='blue', linestyle='solid')
plt.axhline(y=2, xmin=0.1, xmax=0.9, color='blue', linestyle='dashed')
## (2) adding a horizontal line at each y from xmin to xmax
plt.hlines(y=0, xmin=0, xmax=50, color='red', linestyle='dotted')
## (3) adding a horizontal line using (x1, x2), (y1, y2) coordinates
plt.plot((50, 100), (-2, -2), color='black', linestyle='dashdot')
plt.show()
horizontal lines using matplotlib
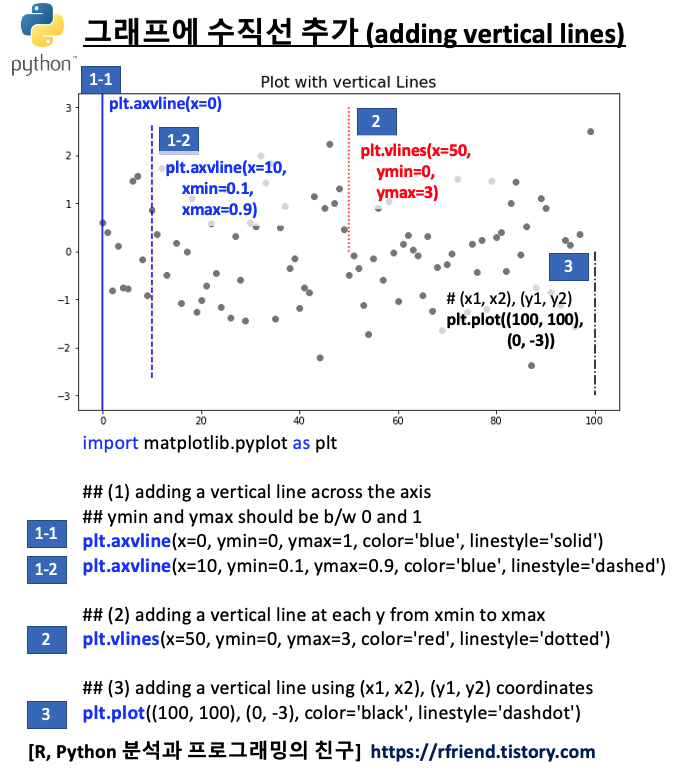
(2) 그래프에 수직선 추가하기 (adding vertical lines)
(a) plt.axvline(x, ymin, ymax) : 축을 따라서 수직선을 추가, ymin 과 ymax 는 0~1 사이의 값을 가짐
(b) plt.vlines(x, ymin, ymax) : ymin ~ ymax 까지 각 x 값의 수평선을 추가
(c) plt.plot((x1, x2), (y1, y2)) : (x1, x2), (y1, y2) 좌표를 연결하는 선 추가
(a) 번의 plt.axvline() 은 x축에서 부터 수평선이 시작하고, ymin~ymax 로 0~1 사이의 비율 값을 가지는 반면에, (b)번의 plt.vlines() 는 ymin 값 위치에서 부터 수평선이 시작하고, ymin~ymax 값으로 좌표값을 받는다는 차이점이 있습니다.
(c) 번의 plt.plot() 은 단지 수평선, 수직선 뿐만이 아니라 범용적으로 두 좌표를 연결하는 선을 추가할 수 있습니다.
plt.figure(figsize = (10, 6))
plt.plot(x, linestyle='none', marker='o', color='gray')
plt.title("Plot with vertical Lines", fontsize=16)
## (1) adding a vertical line across the axis
## ymin and ymax should be b/w 0 and 1
plt.axvline(x=0, ymin=0, ymax=1, color='blue', linestyle='solid')
plt.axvline(x=10, ymin=0.1, ymax=0.9, color='blue', linestyle='dashed')
## (2) adding a vertical line at each y from xmin to xmax
plt.vlines(x=50, ymin=0, ymax=3, color='red', linestyle='dotted')
## (3) adding a vertical line using (x1, x2), (y1, y2) coordinates
plt.plot((100, 100), (0, -3), color='black', linestyle='dashdot')
plt.show()
이번 포스팅에서는 주기성을 가지는 센서 시계열 데이터, 음향 데이터, 신호 처리 데이터 등에서 많이 사용되는 스펙트럼 분석 (spectral analysis) 에 대해서 소개하겠습니다.
많은 시계열 데이터는 주기적인 패턴 (periodic behavior) 을 보입니다. 스펙트럼 분석 은 시계열 데이터에 내재되어 있는 주기성(periodicity) 을 찾아내는 분석기법으로서, spectral analysis, spectrum analysis, frequency domain analysis 등의 이름으로 불립니다.
스펙트럼 분석을 할 때 우리는 먼저 시계열 데이터를 시간 영역(time domain)에서 주파수 영역(frequency domain)로 변환을 합니다. 시계열의 공분산은 스펙트럼 확률밀도함수 (spectral density function) 로 알려진 함수로 재표현될 수 있습니다. 스펙트럼 밀도함수는 시계열과 다른 주파수의 사인/코사인 파동 간의 제곱 상관계수로 구하는 주기도(periodogram) 를 사용하여 추정할 수 있습니다. (Venables & Ripley, 2002)
아래의 그림은 시계열(time series)과 스펙트럼(spectrum, frequency) 간의 관계를 직관적으로 이해할 수 있게 도와줍니다.
[ Time Series vs. Spectrum/ Frequency, Fourier Transform(FT) vs. Inverse FT ]
time-series vs. spectrum
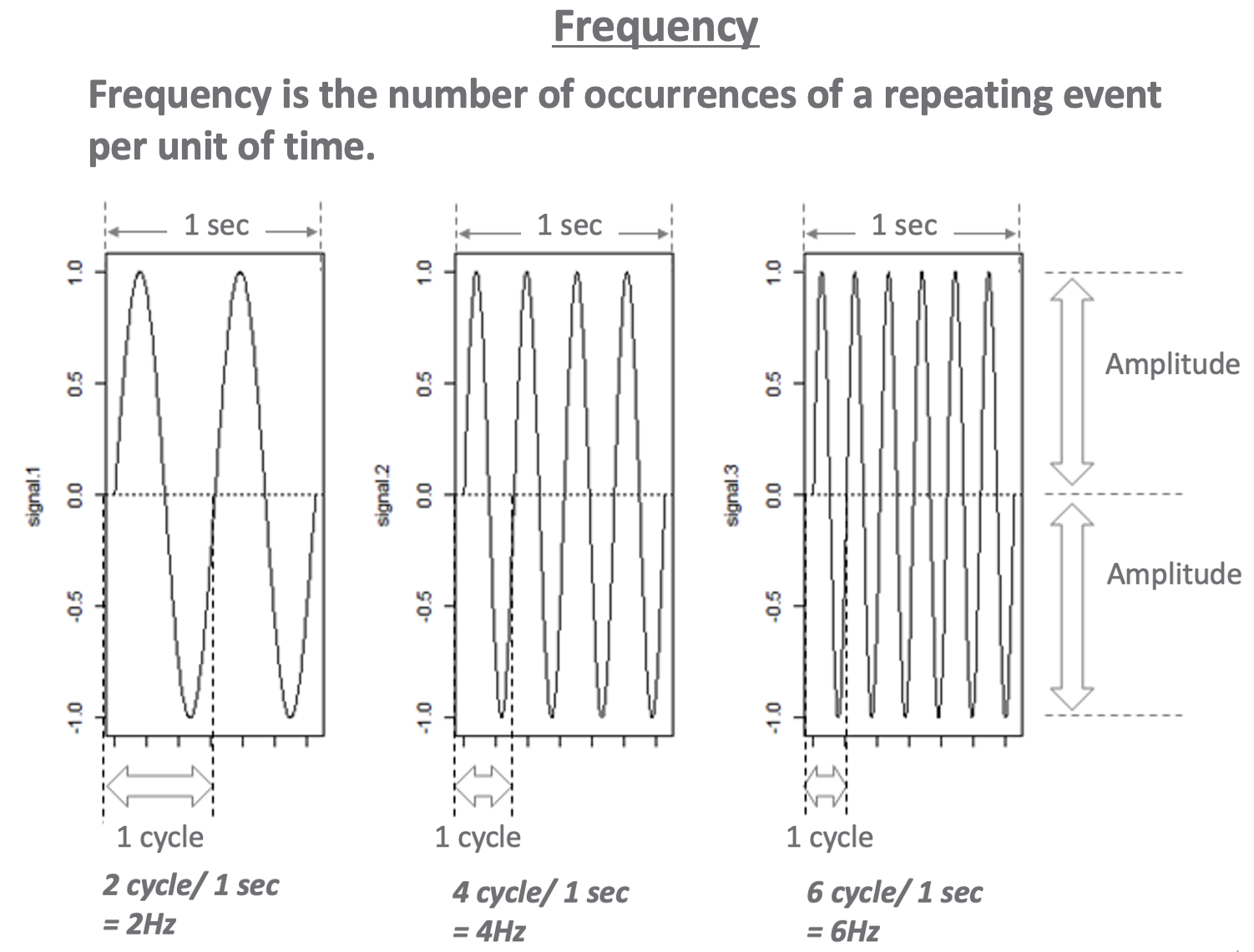
참고로, 주파수(frequency)는 단위 시간 당 반복되는 이벤트가 발생하는 회수를 의미합니다. 주파수를 측정하는데 사용되는 단위인 Hz (Hertz, 헤르쯔) 는 전자기파의 존재를 처음으로 증명한 Heinrich Rudolf Hertz 의 이름에서 따온 것인데요, 가령 2 Hz 는 1초에 2번의 반복 사이클이 발생하는 시계열의 경우, 4 Hz 는 1초에 4번의 반복 사이클이 발행하는 시계열의 주파수에 해당합니다. (아래 그림 예시 참조)
frequency (* https://rfriend.tistory.com)
주기성을 띠는 시계열 데이터나 공간 데이터로 부터 주파수 (spectrum, frequency) 를 계산하거나, 반대로 주파수로 부터 원래의 데이터로 변환할 때 고속 푸리에 변환 (Fast Fourier Transform, 줄여서 FFT) 알고리즘을 많이 사용합니다. 시계열을 주파수로 변환하는 과정 자체를 Fourier Transform 이라고 하며, 이산 푸리에 변환 (Discrete Fourier Transform, DFT) 은 시계열 값을 다른 주파수의 구성요소들로 분해함으로써 구할 수 있습니다. 지금까지 가장 널리 사용되는 고속 푸리에 변환 (FFT) 알고리즘은 Cooley-Tukey 알고리즘 입니다. 이것은 분할-정복 알고리즘 (divide-and-conqer algorithm) 으로서, 반복적으로(recursively) 원래의 시계열 데이터를 훨씬 적은 개수의 주파수로 분할합니다.
[ Fast Fourier Transform(FFT) vs. Inverse FFT]
FFT vs. Inverse FFT
이제 Python 의 spectrum 모듈을 사용해서 스펙트럼 분석을 해보겠습니다. 터미널에서 $ pip install spectrum 으로 먼저 spectrum 모듈을 설치해줍니다.
## installment of spectrum python library at a terminal
$ pip install spectrum
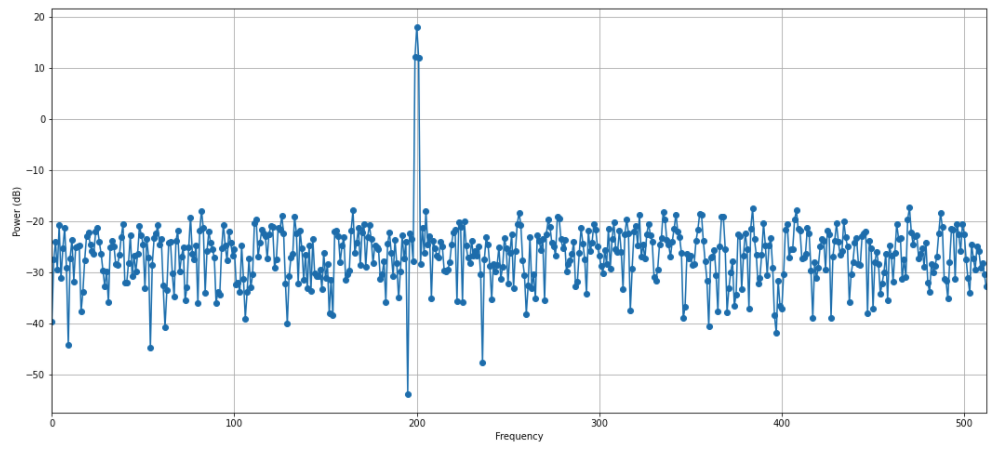
예제로 사용할 샘플데이터로서, data_cosine() 메소드를 사용해서 200 Hz 주파수 (freq=200) 의 주기성을 띠는 코사인 신호(cosine signal)에 백색 잡음 (amplitude 0.1) 도 포함되어 있는 이산형 샘플 데이터 1,024개 (N=1024, sampling=1024) 를 생성해보겠습니다.
## -- importing modules
from spectrum import Periodogram, data_cosine
## generating a toy data sets
## data contains a cosine signal with a frequency of 200Hz
## buried in white noise (amplitude 0.1).
## The data has a length of N=1024 and the sampling is 1024Hz.
data = data_cosine(N=1024, A=0.1, sampling=1024, freq=200)
## plotting the generated data
plt.rcParams['figure.figsize'] = [18, 8]
plt.plot(data)
plt.show()
위의 시계열 그래프가 1,024개 데이터 포인트가 모두 포함되다보니 코사인 신호의 주기성이 눈에 잘 안보이는데요, 앞 부분의 50개만 가져다가 시도표로 그려보면 아래처럼 코사인 파동 모양의 주기성을 띠는 데이터임을 눈으로 확인할 수 있습니다.
spectrum 모듈의 Periodogram() 메소드에 위에서 생성한 샘플 데이터를 적용해서 periodogram 객체를 만든 후에 run() 함수를 실행시켜서 스펙트럼을 추정할 수 있고, p.plot() 으로 간단하게 추정한 스펙트럼을 시각화할 수 있습니다.
## the Power Spectrum Estimation method provided in spectrum.
## creating an object Periodogram.
p = Periodogram(data, sampling=1024)
## running the spectrum estimation
p.run() # or p()
p.plot(marker='o')
스펙트럼 분석 결과 중 개수(N), 주파수의 세기 (power of spectrum dendity) 속성값을 확인할 수 있습니다.
## some information are stored and can be retrieved later on.
p.N
[Out] 1024
p.psd
# [Out] array([1.06569152e-04, 1.74100855e-03, 3.93335837e-03, 1.10485152e-03,
# 8.28499278e-03, 7.64848301e-04, 2.94332240e-03, 7.35029918e-03,
# 1.21273520e-03, 3.72342384e-05, 1.87058542e-03, 4.35817479e-03,
# 6.60803332e-04, 3.01094523e-03, 3.14914528e-03, 3.40040266e-03,
# 1.70112710e-04, 4.04579597e-04, 1.73102721e-03, 5.17048610e-03,
# 5.89537834e-03, 3.43004928e-03, 2.60894164e-03, 2.29556960e-03,
# 6.23836725e-03, 7.35588289e-03, 3.88793797e-03, 2.25691304e-03,
# ... 중간 생략함 ...
# 2.57852156e-03, 1.23483225e-03, 1.49139300e-03, 9.09082081e-04,
# 5.24999741e-04])
우리가 위에서 data_cosine(N=1024, A=0.1, sampling=1024, freq=200) 메소드를 사용해서 200 Hz 의 데이터를 생성하였기 때문에, 이 샘플 데이터로부터 주파수를 분해하면 200 Hz 가 되어야 할텐데요, 스펙트럼 분석 결과도 역시 200 Hz 에서 스파이크가 엄청 높게 튀는군요.
이번 포스팅에서는 Python의 matplotlib 모듈을 사용하여, X축의 값은 동일하지만 Y축의 값은 척도가 다르고 값이 서로 크게 차이가 나는 2개의 Y값 데이터에 대해서 이중축 그래프 (plot with 2 axes for a dataset with different scales)를 그리는 방법을 소개하겠습니다.
먼저 간단한 예제 데이터셋을 만들어보겠습니다.
* x 축은 2021-10-01 ~ 2021-10-10 일까지의 10개 날짜로 만든 index 값을 동일하게 사용하겠습니다.
* y1 값은 0~9 까지 정수에 표준정규분포 Z~N(0, 1) 로 부터 생성한 난수를 더하여 만들었습니다.
다음으로 이를 해결하기 위한 방법 중의 하나로서 matplotlib을 사용해 2중축 그래프를 그려보겠습니다.
(* 참고로, 2중축 그래프 외에 서로 다른 척도(scale)의 두개 변수의 값을 표준화(standardization, scaling) 하여 두 변수의 척도를 비교할 수 있도록 변환해준 후에 하나의 축에 두 변수를 그리는 방법도 있습니다.)
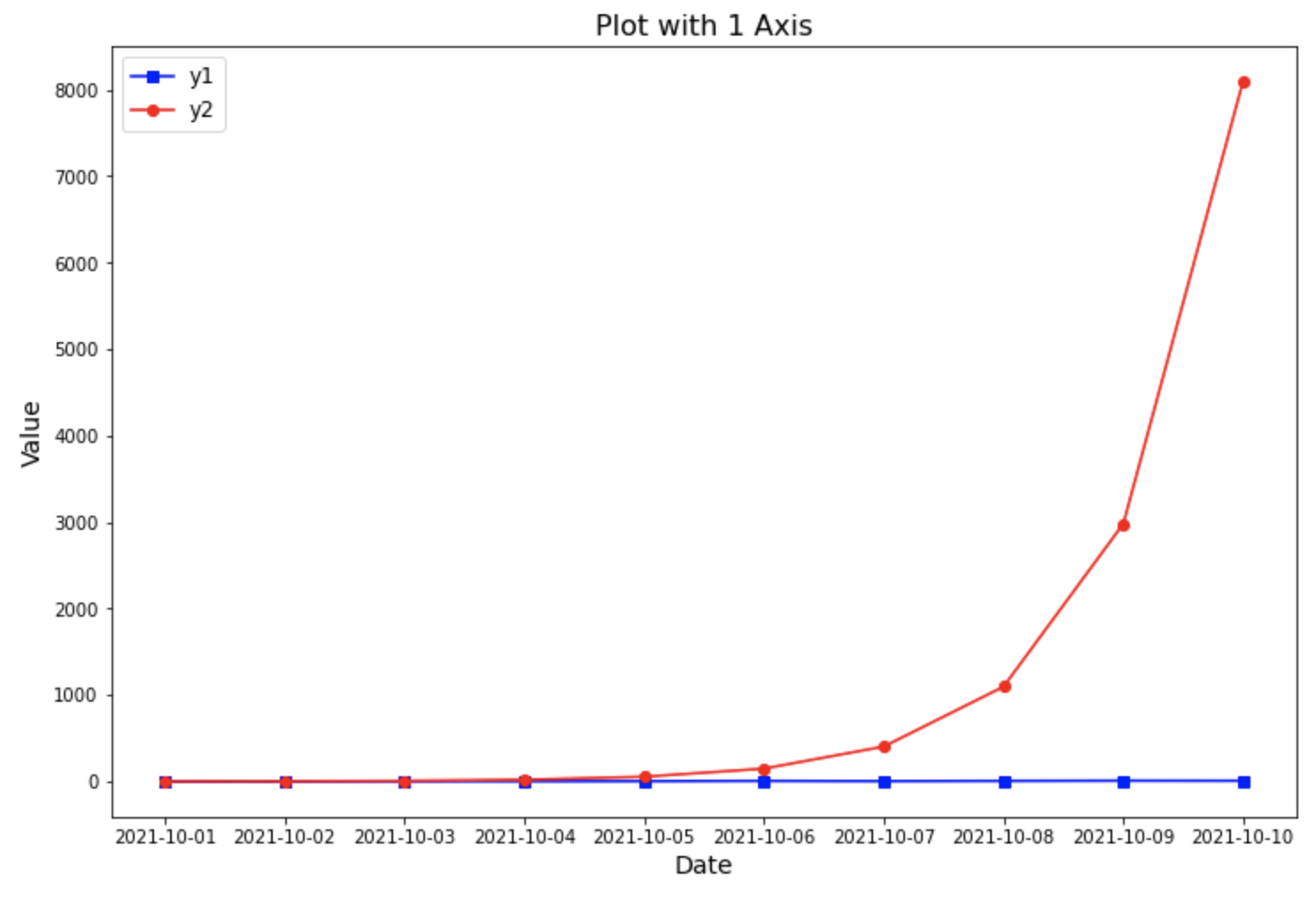
(1) 스케일이 다른 2개의 y값 변수를 1중축 그래프에 그렸을 때 문제점
==> 스케일이 작은 쪽의 y1 값이 스케일이 큰 쪽의 y2 값에 압도되어 y1 값의 패턴을 파악할 수 없음. (스케일이 작은 y1값의 시각화가 의미 없음)
## scale이 다른 데이터를 1개의 y축만을 사용해 그린 그래프
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot()
ax.plot(df.index, df.y1, marker='s', color='blue')
ax.plot(df.index, df.y2, marker='o', color='red')
plt.title('Plot with 1 Axis', fontsize=16)
plt.xlabel('Date', fontsize=14)
plt.ylabel('Value', fontsize=14)
plt.legend(['y1', 'y2'], fontsize=12, loc='best')
plt.show()
plot with 1 axis for a dataset with the different scales
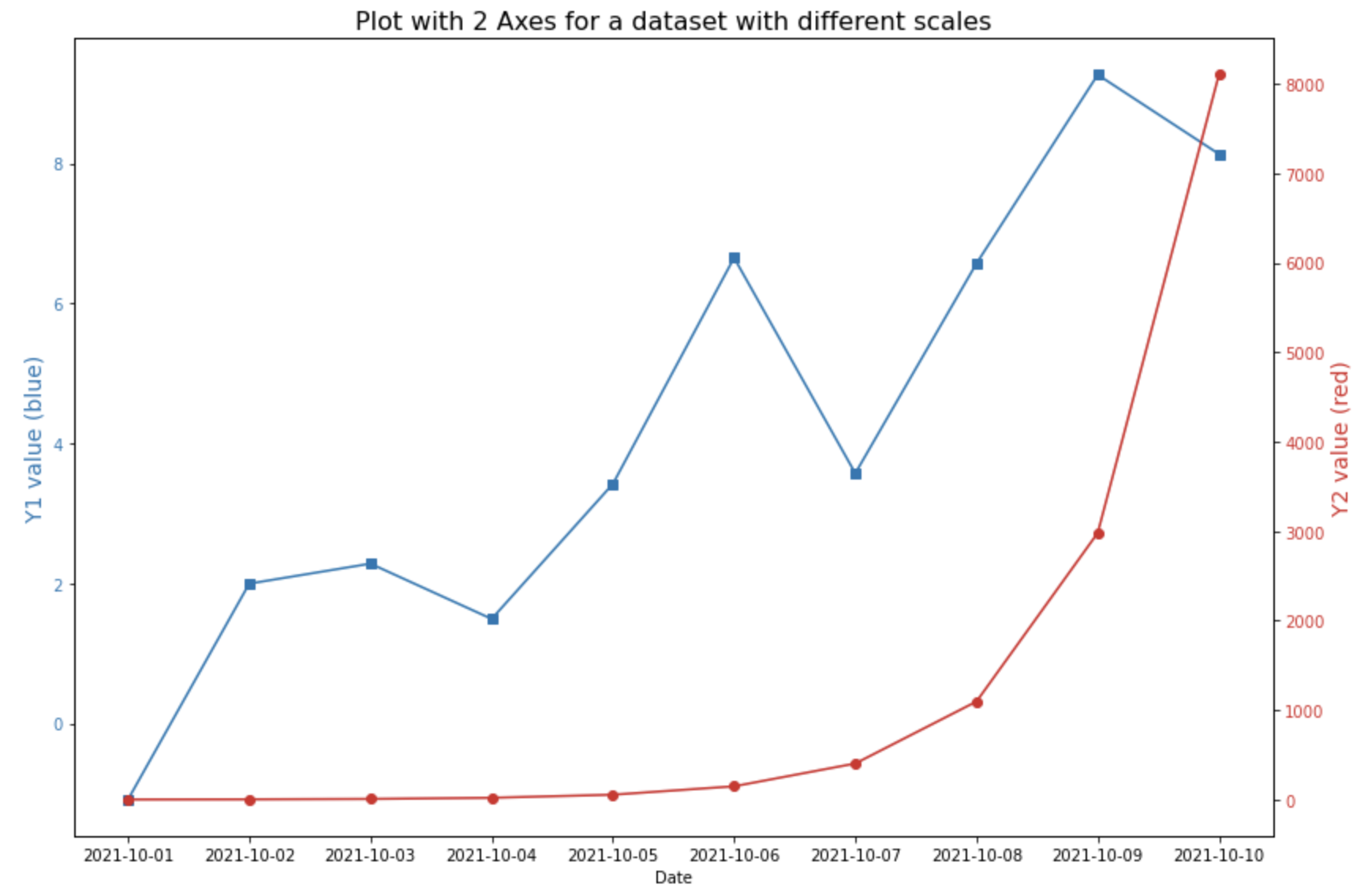
(2) 스케일이 다른 2개의 변수에 대해 2중축 그래프 그렸을 때
==> 각 y1, y2 변수별 스케일에 맞게 적절하게 Y축이 조정이 되어 두 변수 값의 패턴을 파악하기가 쉬움
이때, 가독성을 높이기 위해서 각 Y축의 색깔, Y축 tick의 색깔과 그래프의 색깔을 동일하게 지정해주었습니다. (color 옵션 사용)
## plot with 2 different axes for a dataset with different scales
# left side
fig, ax1 = plt.subplots()
color_1 = 'tab:blue'
ax1.set_title('Plot with 2 Axes for a dataset with different scales', fontsize=16)
ax1.set_xlabel('Date')
ax1.set_ylabel('Y1 value (blue)', fontsize=14, color=color_1)
ax1.plot(df.index, df.y1, marker='s', color=color_1)
ax1.tick_params(axis='y', labelcolor=color_1)
# right side with different scale
ax2 = ax1.twinx() # instantiate a second axes that shares the same x-axis
color_2 = 'tab:red'
ax2.set_ylabel('Y2 value (red)', fontsize=14, color=color_2)
ax2.plot(df.index, df.y2, marker='o', color=color_2)
ax2.tick_params(axis='y', labelcolor=color_2)
fig.tight_layout()
plt.show()
plot with 2 axes for a dataset with different scales
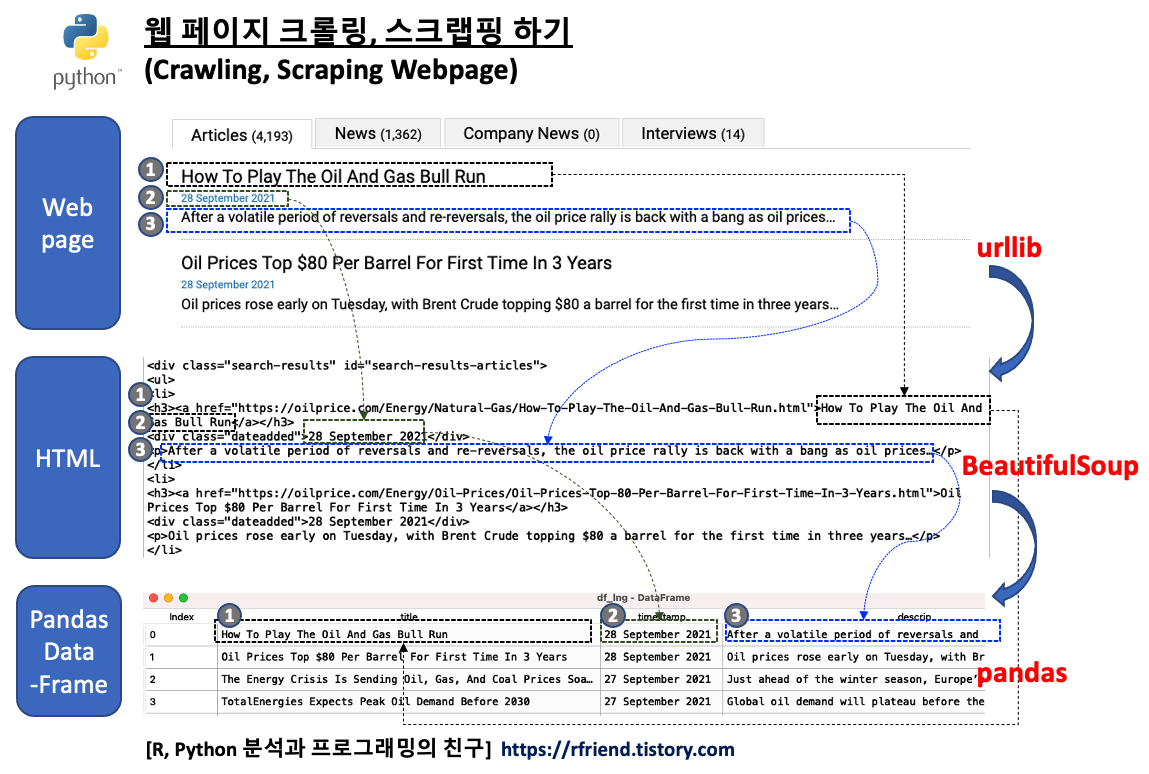
이번 포스팅에서는 Python의 urllib 과 BeautifulSoup 모듈을 사용해서 웹 페이지의 내용을 파싱하여 필요한 데이터만 크롤링, 스크래핑하는 방법을 소개하겠습니다.
urllilb 모듈은 웹페이지 URL 을 다룰 때 사용하는 Python 라이브러리입니다. 가령, urllib.request 는 URL을 열고 읽을 때 사용하며, urllib.parse 는 URL을 파싱할 때 사용합니다.
BeautifulSoup 모듈은 HTML 과 XML 파일로부터 데이터를 가져올 때 사용하는 Python 라이브러리입니다. 이 모듈은 사용자가 선호하는 파서(parser)와 잘 작동하여, parse tree 를 조회하고 검색하고 수정하는 자연스러운 방법을 제공합니다.
python urllib, BeautifulSoup module for web scraping
이번 예제에서는
(1) urllib.request 의 urlopen 메소드로 https://oilprice.com/ 웹페이지에서 'lng' 라는 키워드로 검색했을 때 나오는 총 20개의 페이지를 열어서 읽은 후
(2) BeautifulSoup 모듈을 사용해 기사들의 각 페이지내에 있는 20개의 개별 기사들의 '제목(title)', '기사 게재일(timestamp)', '기사에 대한 설명 (description)' 의 데이터를 파싱하고 수집하고,
(3) 이들 데이터를 모아서 pandas DataFrame 으로 만들어보겠습니다. (총 20개 페이지 * 각 페이지별 20개 기사 = 총 400 개 기사 스크랩핑)
webpage crawling, scraping using python urllib, BeautifulSoup, pandas
아래의 예시 코드는 파송송님께서 짜신 것이구요, 각 검색 페이지에 20개씩의 기사가 있는데 제일 위에 1개만 크롤링이 되는 문제를 해결하는 방법을 문의해주셔서, 그 문제를 해결한 후의 코드입니다.
##-- How to Scrape Data on the Web with BeautifulSoup and urllib
from bs4 import BeautifulSoup
from urllib.request import urlopen
import pandas as pd
from datetime import datetime
col_name = ['title', 'timestamp', 'descrip']
df_lng = pd.DataFrame(columns = col_name)
for j in range(20):
## open and read web page
url = 'https://oilprice.com/search/tab/articles/lng/Page-' + str(j+1) + '.html'
with urlopen(url) as response:
soup = BeautifulSoup(response, 'html.parser')
headlines = soup.find_all(
'div',
{'id':'search-results-articles'}
)[0]
## getting all 20 titles, timestamps, descriptions on each page
title = headlines.find_all('a')
timestamp = headlines.find_all(
'div',
{'class':'dateadded'}
)
descrip = headlines.find_all('p')
## getting data from each article in a page
for i in range(len(title)):
title_i = title[i].text
timestamp_i = timestamp[i].text
descrip_i = descrip[i].text
# appending to DataFrame
df_lng = df_lng.append({
'title': title_i,
'timestamp': timestamp_i,
'descrip': descrip_i},
ignore_index=True)
if j%10 == 0:
print(str(datetime.now()) + " now processing : j = " + str(j))
# remove temp variables
del [col_name, url, response, title, title_i, timestamp, timestamp_i, descrip, descrip_i, i, j]
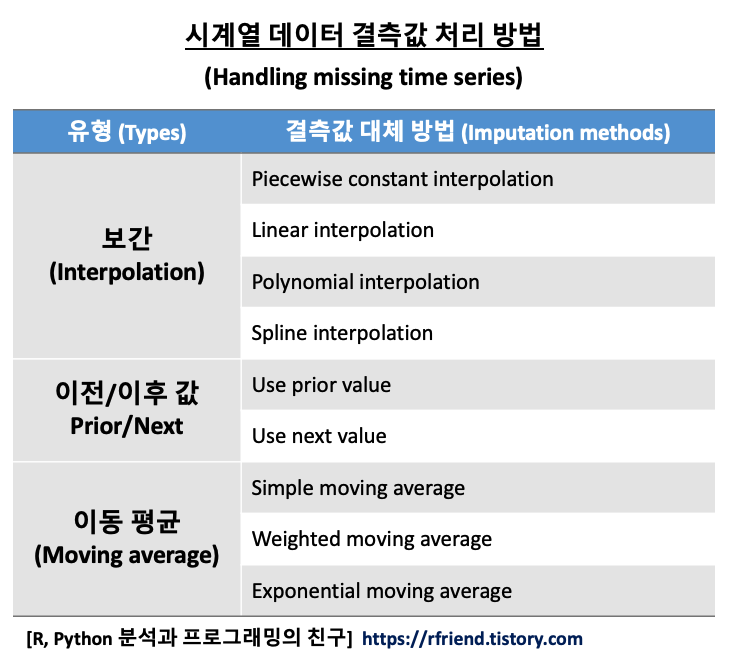
시계열 데이터를 분석할 때 꼭 확인하고 처리해야 하게 있는데요, 바로 결측값 여부 확인과 결측값 처리입니다.
시계열 데이터의 결측값을 처리하는 방법에는
(1) 보간 (Interpolation)
(2) 이전 값 또는 다음 값 이용 (previous/next value)
(3) 이동 평균 (Moving average)
등의 여러가지 방법이 있습니다.
[ 시계열 데이터 결측값 처리 방법 (How to handle the time series missing data) ]
아래의 보간(Interpolation)에 대한 내용은 Wikipedia 의 내용을 번역하여 소개합니다.
데이터 분석의 수학 분야에서는 "보간법(Interpolation)을 이미 알려진 데이터 포인트들의 이산형 집합의 범위에 기반해서 새로운 데이터 포인트들을 만들거나 찾는 추정(estimation)의 한 유형"으로 봅니다.
공학과 과학 분야에서는 종종 샘플링이나 실험을 통해서 많은 수의 데이터 포인트들을 획득하는데요, 이들 데이터는 어떤 함수(a function)의 값이나 독립변수(independent variable)의 제한적인 수의 값을 표현한 것입니다. 종종 독립변수의 중간 사이의 값을 위한 함수의 값을 추정(estimate the value of that function for an intermediat value of the independent variable)하는 보간이 필요합니다.
밀접하게 관련된 문제로서 복잡한 함수를 간단한 함수로 근사하게 추정(the approximation of a complicated function by a simple function)하는 것이 있습니다. 어떤 주어진 함수의 공식이 알려져있지만, 너무 복잡해서 효율적으로 평가하기가 어렵다고 가정해봅시다. 원래의 함수로부터 적은 수의 새로운 데이터 포인트는 원래의 값과 상당히 근접한 간단한 함수를 생성해서 보간할 수 있습니다. 단순성(simplicity)으로부터 얻을 수 있는 이득이 보간에 의한 오차라는 손실보다 크고, 연산 프로세스면서도 더 좋은 성능(better performance in calculation process)을 낼 수도 있습니다.
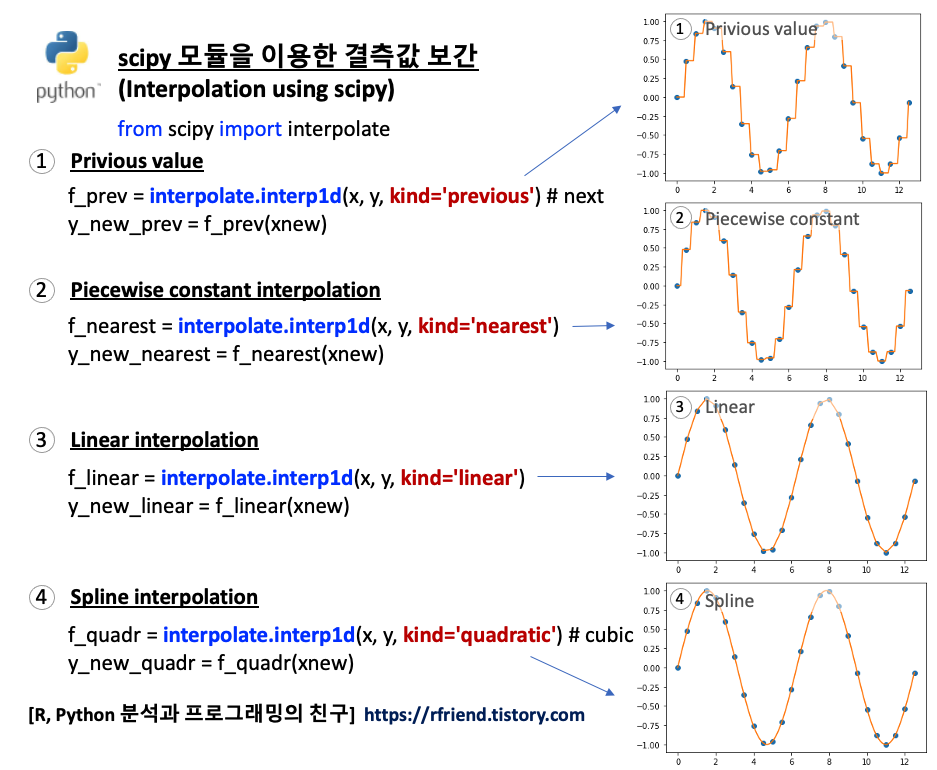
이번 포스팅에서는 Python scipy 모듈을 이용해서 시계열 데이터 결측값을 보간(Interpolation)하는 방법을 소개하겠습니다.
1. 이전 값/ 이후 값을 이용하여 결측값 채우기 (Imputation using the previous/next values)
2. Piecewise Constant Interpolation
3. 선형 보간법 (Linear Interpolation)
4. 스플라인 보간법 (Spline Interpolation)
[ Python scipy 모듈을 이용한 결측값 보간 (Interpolation using Python scipy module) ]
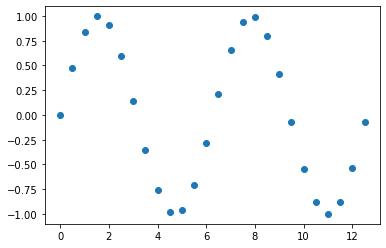
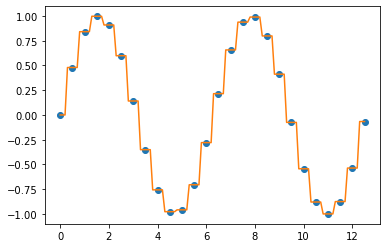
먼저 '0.5'로 동일한 간격을 가지는 x 값들에 대한 사인 함수 (sine function) 의 y값을 계산해서 예제 데이터로 사용하겠습니다. 아래 예졔의 점과 점 사이의 값들이 비어있는 결측값이라고 간주하고, 이들 값을 채워보겠습니다.
import numpy as np
from scipy import interpolate
import matplotlib.pyplot as plt
## generating the original data with missing values
x = np.arange(0, 4*np.pi, 0.5)
y = np.sin(x)
plt.plot(x, y, "o")
plt.show()
original data with missing values
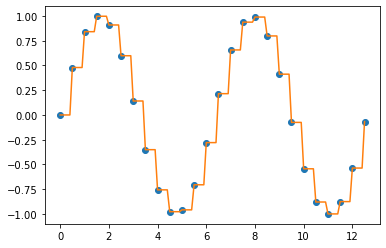
1. 이전 값/ 다음 값을 이용하여 결측값 채우기 (Imputation using the previous/next values)
데이터 포인트 사이의 값을 채우는 가장 간단한 방법은 이전 값(previous value) 나 또는 다음 값(next value)을 이용하는 것입니다. 함수를 추정하는 절차가 필요없으므로 연산 상 부담이 적지만, 데이터 추정 오차는 단점이 될 수 있습니다.
## Interpolation using the previous value
f_prev = interpolate.interp1d(
x, y, kind='previous') # next
y_new_prev = f_prev(xnew)
plt.plot(x, y, "o", xnew, y_new_prev, '-')
plt.show()
interpolation using the previous value
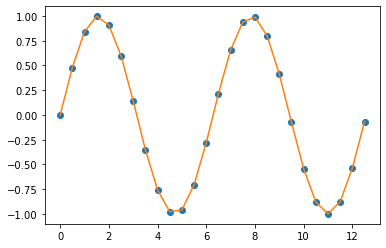
2. Piecewise Constant Interpolation
위 1번의 이전 값 또는 다음 값을 이용한 사이값 채우기를 합쳐놓은 방법입니다. Piecewise Constant Interpolation은 특정 데이터 포인트를 기준으로 가장 가까운 값 (nearest value) 을 가져다가 사이값을 보간합니다. ("최근접 이웃 보간"이라고도 함)
간단한 문제에서는 아래 3번에서 소개하는 Linear Interpolation 이 주로 사용되고, Piecewise Constant Interpolation 은 잘 사용되지 않는 편입니다. 하지만 다차원의 다변량 보간 (in higher-dimensional multivariate interpolation)의 경우, 속도와 단순성(speed and simplicity) 측면에서 선호하는 선택이 될 수 있습니다.
## Piecewise Constant Interpolation
f_nearest = interpolate.interp1d(
x, y, kind='nearest')
y_new_nearest = f_nearest(xnew)
plt.plot(x, y, "o", xnew, y_new_nearest)
plt.show()
Piecewise constant interpolation
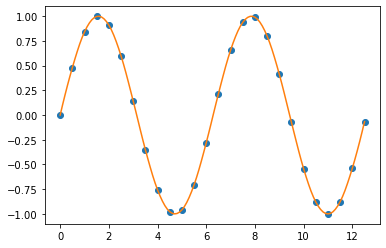
3. Linear Interpolation
선형 보간법은 가장 쉬운 보간법 중의 하나로서, 연산이 빠르고 쉽습니다. 하지만 추정값이 정확한 편은 아니며, 데이터 포인트 Xk 에서 미분 가능하지 않다는 단점도 있습니다.
일반적으로, 선형 보간법은 두 개의 데이터 포인트, 가령 (Xa, Ya)와 (Xb, Yb), 를 사용해서 다음의 공식으로 두 값 사이의 값을 보간합니다.
Y = Ya + (Yb - Ya) * (X - Xa) / (Xb- Xa) at the point (x, y)
## Linear Interpolation
f_linear = interpolate.interp1d(
x, y, kind='linear')
y_new_linear = f_linear(xnew)
plt.plot(x, y, "o", xnew, y_new_linear, '-')
plt.show()
Linear interpolation
4. Spline Interpolation
다항식 보간법(Polynomial Interpolation)은 선형 보간법을 일반화(generalization of linear interpolation)한 것입니다. 선형 보간법에서는 선형 함수를 사용했다면, 다항식 보간법에서는 더 높은 차수의 다항식 함수를 사용해서 보간하는 것으로 대체한 것입니다.
일반적으로, 만약 우리가 n개의 데이터 포인트를 가지고 있다면 모든 데이터 포인트를 통과하는 n-1 차수의 다차항 함수가 존재합니다. 보간 오차는 데이터 포인트 간의 거리의 n 차승에 비례(interpolation error is proportional to the distance between the data points to the power n)하며, 다차항 함수는 미분가능합니다. 따라서 선형 보간법의 대부분의 문제를 다항식 보간법은 극복합니다. 하지만 다항식 보간법은 선형 보간법에 비해 복잡하고 연산에 많은 비용이 소요됩니다. 그리고 끝 점(end point) 에서는 진동하면서 변동성이 큰 값을 추정하는 문제가 있습니다.
스플라인 보간법은 각 데이터 포인트 구간별로 낮은 수준의 다항식 보간을 사용 (Spline interpolation uses low-degree polynomials in each of the intervals) 합니다. 그리고 이들이 함께 부드럽게 연결되어서 적합될 수 있도록 다항식 항목을 선택(, and chooses the polynomial pieces such that they fit smoothly together)합니다. 이렇게 적합된 함수를 스플라인(Spline) 이라고 합니다.
스플라인 보간법(Spline Interpolation)은 다항식 보간법의 장점은 살리고 단점은 피해간 보간법입니다. 스플라인 보간법은 다항식 보간법처럼 선형 보간법보다 보간 오차가 더 작은 반면에, 고차항의 다항식 보간법보다는 보간 함수가 부드럽고 평가하기가 쉽습니다.
## Spline Interpolation
f_quadr = interpolate.interp1d(
x, y, kind='quadratic') # cubic
y_new_quadr = f_quadr(xnew)
plt.plot(x, y, "o", xnew, y_new_quadr)
plt.show()
이번 포스팅에서는 시계열 자료 예측 모형의 성능, 모델 적합도 (goodness-of-fit of the time series model) 를 평가할 수 있는 지표, 통계량을 알아보겠습니다.
아래의 모델 적합도 평가 지표들의 리스트를 살펴보시면 선형회귀모형의 모델 적합도 평가 지표와 유사하다는 것을 알 수 있습니다.(실제값과 예측값의 차이 또는 설명비율에 기반한 성능 평가라는 측면에서는 동일하며, 회귀모형은 종속변수와 독립변수간 상관관계에 기반한 반면에 시계열 모형은 종속변수와 자기자신의 과거 데이터와의 자기상관관계에 기반한 다는것이 다른점 입니다.)
아래 평가지표들 중에서 전체 분산 중에서 모델이 설명할 수 있는 비율을 나타내는 수정결정계수는 통계량 값이 높을 수록 좋은 모델이며, 나머지 오차에 기반한 평가 지표(통계량)들은 값이 낮을 수록 상대적으로 더 좋은 모델이라고 평가를 합니다. (단, SST는 제외)
이들 각 지표별로 좋은 모델 여부를 평가하는 절대 기준값(threshold)이 있는 것은 아니며, 여러개의 모델 간 성능을 상대적으로 비교 평가할 때 사용합니다.
- 전체제곱합 (SST, total sum of square)
- 오차제곱합 (SSE, error sum of square)
- 평균오차제곱합 (MSE, mean square error)
- 제곱근 평균오차제곱합 (RMSE, root mean square error)
- 평균오차 (ME, mean error)
- 평균절대오차 (MAE, mean absolute error)
- 평균비율오차 (MPE, mean percentage error)
- 평균절대비율오차 (MAPE, mean absolute percentage error)
- 수정결정계수 (Adj. R-square)
- AIC (Akaike's Information Criterion)
- SBC (Schwarz's Bayesian Criterion)
- APC (Amemiya's Prediction Criterion)
[ 시계열 데이터 예측 모형 적합도 평가 지표 (goodness-of-fit measures for time series prediction models) ]
goodness-of-fit measures for time series models
1. 전체제곱합 (SST, total sum of square)
total sum of square, SST
SST는 시계열 값에서 시계열의 전체 평균 값을 뺀 값으로, 시계열 예측 모델을 사용하지 않았을 때 (모든 모수들이 '0' 일 때) 의 오차 제곱 합입니다. 나중에 결정계수(R2), 수정결정계수(Adj. R2)를 계산할 때 사용됩니다. (SST 는 모델 성능 평가에서는 제외)
2. 오차제곱합 (SSE, error sum of square)
error sum of square, SSE
3. 평균오차제곱합 (MSE, mean square error), 제곱근 평균오차제곱합 (RMSE, root mean square error)
root mean squared error
MSE는 많은 통계 분석 패키지, 라이브러리에서 모델 훈련 시 비용함수(cost function) 또는 모델 성능 평가시 기본 설정 통계량으로 많이 사용합니다.
RMSE (Root Mean Square Error) 는 MSE에 제곱근을 취해준 값으로서, SSE를 제곱해서 구한 MSE에 역으로 제곱근을 취해주어 척도를 원래 값의 단위로 맞추어 준 값입니다.
4. 평균오차 (ME, mean error)
mean error
ME(Mean Error) 는 MAE(Mean Absolute Error)와 함께 해석하는 것이 필요합니다. 왜냐하면 큰 오차 값들이 존재한다고 하더라도 ME 값만 볼 경우 + 와 - 값이 서로 상쇄되어 매우 작은 값이 나올 수도 있기 때문입니다. 따라서 MAE 값을 통해 실제값과 예측값 간에 오차가 평균적으로 얼마나 큰지를 확인하고, ME 값의 부호를 통해 평균적으로 과다예측(부호가 '+'인 경우) 혹은 과소예측(부호가 '-'인 경우) 인지를 가늠해 볼 수 있습니다.
5. 평균절대오차 (MAE, mean absolute error)
mean absolute error
6. 평균비율오차 (MPE, mean percentage error)
mean percentage error
위의 ME와 MAE 는 척도 문제 (scale problem) 을 가지고 있습니다. 반면에 MPE (Mean Percentage Error)와 MAPE (Mean Absolute Percentage Error) 는 0~100%로 표준화를 해주어서 척도 문제가 없다는 특징, 장점이 있습니다. 역시 MAE 와 MAPE 값을 함께 확인해서 해석하는 것이 필요합니다. 0에 근접할 수록 시계열 예측모델이 잘 적합되었다고 평가할 수 있으며, MAE의 부호(+, -)로 과대 혹은 과소예측의 방향을 파악할 수 있습니다.
7. 평균절대비율오차 (MAPE, mean absolute percentage error)
mean absolute percentage error
8. 수정결정계수 (Adj. R-square)
adjusted R2
결정계수 R2 는 SST 에서 예측 모델이 설명하는 부분의 비율(R2 = SSR/SST=1-SSE/SST)을 의미합니다. 그런데 결정계수 R2는 모수의 개수가 증가할 수록 이에 비례하여 증가하는 경향이 있습니다. 이러한 문제점을 바로잡기 위해 예측에 기여하지 못하는 모수가 포함될 경우 패널티를 부여해서 결정계수의 값을 낮추어주게 수정한 것이 바로 수정결정계수(Adjusted R2) 입니다. (위의 식에서 k 는 모델에 포함된 모수의 개수를 의미합니다.)
위의 2~7번의 통계량들은 SSE(Error Sum of Square)를 기반으로 하다보니 값이 작을 수록 좋은 모델을 의미하였다면, 8번의 수정결정계수(Adj. R2)는 예측모델이 설명력과 관련된 지표로서 값이 클 수록 더 좋은 모델을 의미합니다.(1에 가까울 수록 우수)
9. AIC, SBC, APC
AIC (Akaike's Information Criterion),
SBC (Schwarz's Bayesian Criterion),
APC (Amemiya's Prediction Criterion)
AIC, SBC, APC
위의 AIC, SBC, APC 지표들도 SSE(Error Sum of Square) 에 기반한 지표들로서, 값이 작을 수록 더 잘 적합된 모델을 의미합니다. 이들 지표 역시 SSE 를 기본으로 해서 여기에 모델에서 사용한 모수의 개수(k, 패널티로 사용됨), 관측치의 개수(T, 관측치가 많을 수록 리워드로 사용됨)를 추가하여 조금씩 변형을 한 통계량들입니다.
다음번 포스팅에서는 이들 지표를 사용해서 Python으로 하나의 시계열 자료에 대해 여러 개의 지수 평활법 기법들을 적용해서 가장 모형 적합도가 높은 모델을 찾아보겠습니다.(https://rfriend.tistory.com/671)
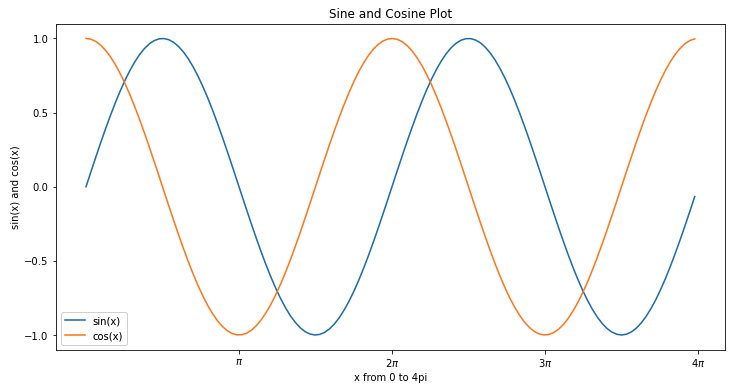
이번 포스팅에서는 Python 의 matplotlib 라이브러리를 사용해서 사인 곡선, 코사인 곡선을 그려보겠습니다.
(1) matplotlib, numpy 라이브러리를 사용해서 사인 곡선, 코사인 곡선 그리기
(Plotting sine, cosine curve using python matplotlib, numpy)
(2) x축과 y축의 눈금값(xticks, yticks), 범례(legend) 를 설정하기
(3) 그래프에 가로, 세로 그리드 선 추가하기 (adding grid lines)
이번 포스팅은 그리 어렵지는 않은데요, 눈금값, 범례, 그리드 선 추가와 같은 소소한 팁들이 필요할 때 참고하라고 정리해 놓습니다.
(1) matplotlib, numpy 라이브러리를 사용해서 사인 곡선, 코사인 곡선 그리기
(Plotting sine, cosine curve using python matplotlib, numpy)
numpy 로 0부터 4 pi 까지 0.1씩 증가하는 배열의 x축 값을 만들고, 이들 값들을 대입하여서 사인 y값, 코사인 z값을 생성하였습니다.
이들 x 값들에 대한 사인 y값, 코사인 z값을 가장 간단하게 matplotlib 으로 시각화하면 아래와 같습니다.
import numpy as np
import matplotlib.pyplot as plt
# using Jupyter Notebook
%matplotlib inline
## generating x from 0 to 4pi and y using numpy library
x = np.arange(0, 4*np.pi, 0.1) # start, stop, step
y = np.sin(x)
z = np.cos(x)
## ploting sine and cosine curve using matplotlb
plt.plot(x, y, x, z)
plt.show()
(2) x축과 y축의 눈금값(xticks, yticks), 범례(legend) 를 설정하기
위의 (1)번 사인 곡선, 코사인 곡선을 보면 그래프 크기가 작고, x축 눈금값과 y축 눈금값이 정수로 되어있으며, x축과 y축의 라벨도 없고, 범례가 없다보니 사인 곡선과 코사인 곡선을 구분하려면 신경을 좀 써야 합니다.
지난번 포스팅에서는 샘플 크기가 다른 2개 이상의 집단에 대해 평균의 차이가 존재하는지를 검정하는 일원분산분석(one-way ANOVA)에 대해 scipy 모듈의 scipy.stats.f_oneway() 메소드를 사용해서 분석하는 방법(rfriend.tistory.com/638)을 소개하였습니다.
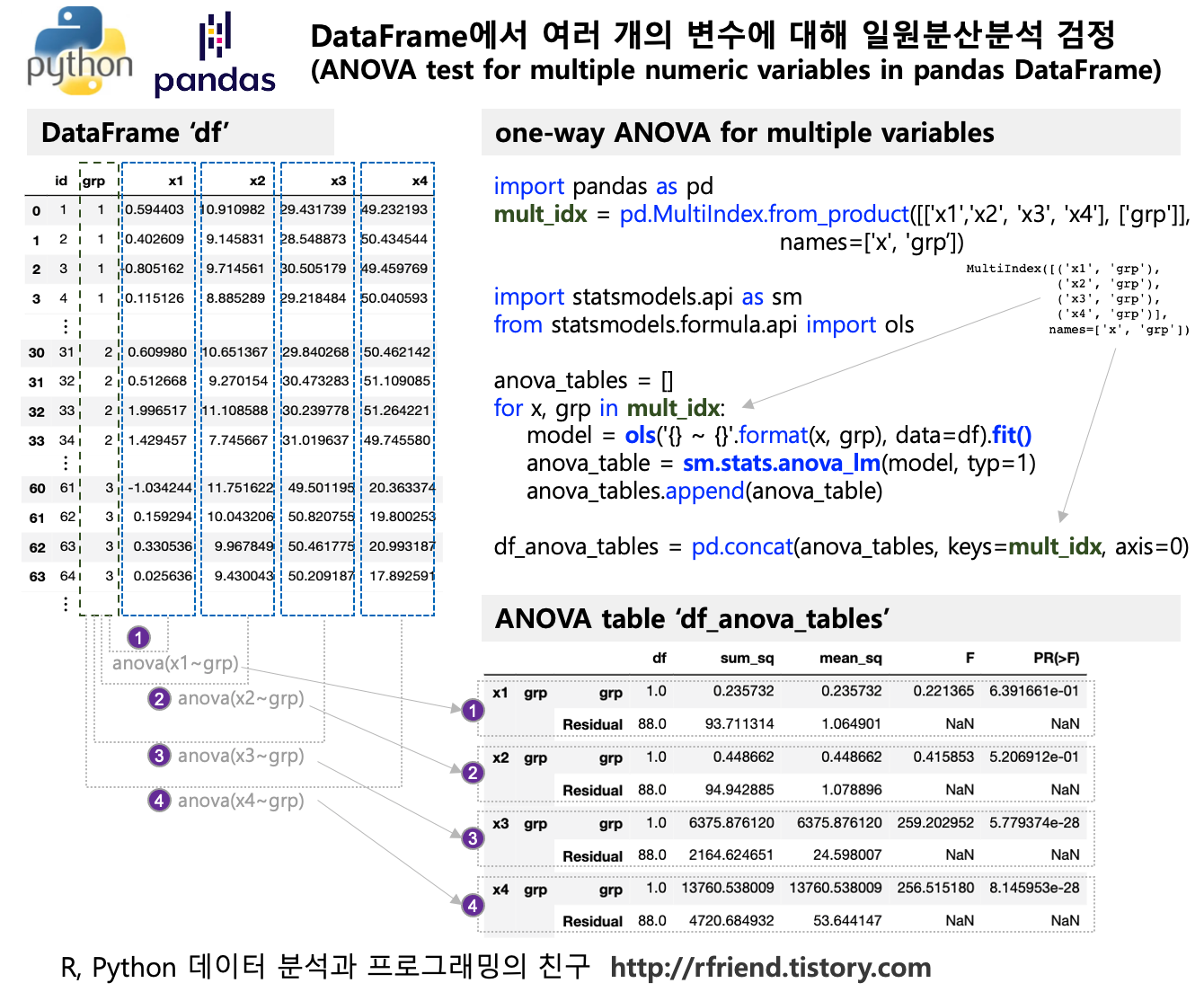
이번 포스팅에서는 2개 이상의 집단에 대해 pandas DataFrame에 들어있는 여러 개의 숫자형 변수(one-way ANOVA for multiple numeric variables in pandas DataFrame) 별로 일원분산분석 검정(one-way ANOVA test)을 하는 방법을 소개하겠습니다.
숫자형 변수와 집단 변수의 모든 가능한 조합을 MultiIndex 로 만들어서 statsmodels.api 모듈의 stats.anova_lm() 메소드의 모델에 for loop 순환문으로 변수를 바꾸어 가면서 ANOVA 검정을 하도록 작성하였습니다.
먼저, 3개의 집단('grp 1', 'grp 2', 'grp 3')을 별로 'x1', 'x2', 'x3, 'x4' 의 4개의 숫자형 변수를 각각 30개씩 가지는 가상의 pandas DataFrame을 만들어보겠습니다. 이때 숫자형 변수는 모두 정규분포로 부터 난수를 발생시켜 생성하였으며, 'x3'와 'x4'에 대해서는 집단3 ('grp 3') 의 평균이 다른 2개 집단의 평균과는 다른 정규분포로 부터 난수를 발생시켜 생성하였습니다.
아래의 가상 데이터셋은 결측값이 없이 만들었습니다만, 실제 기업에서 쓰는 데이터셋에는 혹시 결측값이 존재할 수도 있으므로 결측값을 없애거나 또는 결측값을 그룹 별 평균으로 대체한 후에 one-way ANOVA 를 실행하기 바랍니다.
## Creating sample dataset
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# generate 90 IDs
id = np.arange(90) + 1
# Create 3 groups with 30 observations in each group.
from itertools import chain, repeat
grp = list(chain.from_iterable((repeat(number, 30) for number in [1, 2, 3])))
# generate random numbers per each groups from normal distribution
np.random.seed(1004)
# for 'x1' from group 1, 2 and 3
x1_g1 = np.random.normal(0, 1, 30)
x1_g2 = np.random.normal(0, 1, 30)
x1_g3 = np.random.normal(0, 1, 30)
# for 'x2' from group 1, 2 and 3
x2_g1 = np.random.normal(10, 1, 30)
x2_g2 = np.random.normal(10, 1, 30)
x2_g3 = np.random.normal(10, 1, 30)
# for 'x3' from group 1, 2 and 3
x3_g1 = np.random.normal(30, 1, 30)
x3_g2 = np.random.normal(30, 1, 30)
x3_g3 = np.random.normal(50, 1, 30) # different mean
x4_g1 = np.random.normal(50, 1, 30)
x4_g2 = np.random.normal(50, 1, 30)
x4_g3 = np.random.normal(20, 1, 30) # different mean
# make a DataFrame with all together
df = pd.DataFrame({'id': id,
'grp': grp,
'x1': np.concatenate([x1_g1, x1_g2, x1_g3]),
'x2': np.concatenate([x2_g1, x2_g2, x2_g3]),
'x3': np.concatenate([x3_g1, x3_g2, x3_g3]),
'x4': np.concatenate([x4_g1, x4_g2, x4_g3])})
df.head()
[Out]
id grp x1 x2 x3 x4
0 1 1 0.594403 10.910982 29.431739 49.232193
1 2 1 0.402609 9.145831 28.548873 50.434544
2 3 1 -0.805162 9.714561 30.505179 49.459769
3 4 1 0.115126 8.885289 29.218484 50.040593
4 5 1 -0.753065 10.230208 30.072990 49.601211
df[df['grp'] == 3].head()
[Out]
id grp x1 x2 x3 x4
60 61 3 -1.034244 11.751622 49.501195 20.363374
61 62 3 0.159294 10.043206 50.820755 19.800253
62 63 3 0.330536 9.967849 50.461775 20.993187
63 64 3 0.025636 9.430043 50.209187 17.892591
64 65 3 -0.092139 12.543271 51.795920 18.883919
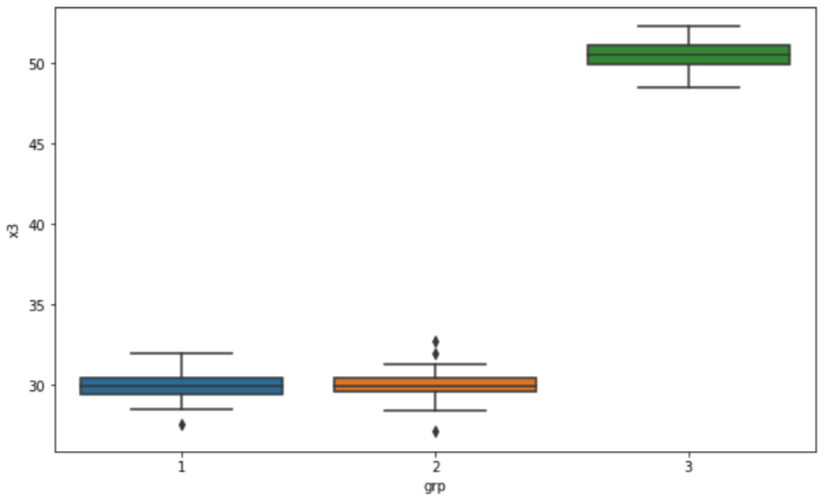
가령, 'x3' 변수에 대해 집단별로 상자 그래프 (Box plot for 'x3' by groups) 를 그려보면, 아래와 같이 집단1과 집단2는 유사한 반면에 집단3은 평균이 차이가 많이 나게 가상의 샘플 데이터가 생성되었음을 알 수 있습니다.
## Boxplot for 'x3' by 'grp'
plt.rcParams['figure.figsize'] = [10, 6]
sns.boxplot(x='grp', y='x3', data=df)
plt.show()
여러개의 변수에 대해 일원분산분석을 하기 전에, 먼저 이해를 돕기 위해 Python의 statsmodels.api 모듈의 stats.anova_lm() 메소드를 사용해서 'x1' 변수에 대해 집단(집단 1/2/3)별로 평균이 같은지 일원분산분석으로 검정을 해보겠습니다.
- 귀무가설(H0) : 집단1의 x1 평균 = 집단2의 x1 평균 = 집단3의 x1 평균
- 대립가설(H1) : 적어도 1개 이상의 집단의 x1 평균이 다른 집단의 평균과 다르다. (Not H0)
# ANOVA for x1 and grp
import statsmodels.api as sm
from statsmodels.formula.api import ols
model = ols('x1 ~ grp', data=df).fit()
sm.stats.anova_lm(model, typ=1)
[Out]
df sum_sq mean_sq F PR(>F)
grp 1.0 0.235732 0.235732 0.221365 0.639166
Residual 88.0 93.711314 1.064901 NaN NaN
일원분산분석 결과 F 통계량이 0.221365, p-value가 0.639 로서 유의수준 5% 하에서 귀무가설을 채택합니다. 즉, 3개 집단 간 x1의 평균의 차이는 없다고 판단할 수 있습니다. (정규분포 X ~ N(0, 1) 를 따르는 모집단으로 부터 무작위로 3개 집단의 샘플을 추출했으므로 차이가 없게 나오는게 맞겠습니다.)
한개의 변수에 대한 일원분산분석하는 방법을 알아보았으니, 다음으로는 3개 집단별로 여러개의 연속형 변수인 'x1', 'x2', 'x3', 'x4' 에 대해서 for loop 순환문으로 돌아가면서 일원분산분석을 하고, 그 결과를 하나의 DataFrame에 모아보도록 하겠습니다.
(1) 먼저, 일원분산분석을 하려는 모든 숫자형 변수와 집단 변수에 대한 가능한 조합의 MultiIndex 를 생성해줍니다.
# make a multiindex for possible combinations of Xs and Group
num_col = ['x1','x2', 'x3', 'x4']
cat_col = ['grp']
mult_idx = pd.MultiIndex.from_product([num_col, cat_col],
names=['x', 'grp'])
print(mult_idx)
[Out]
MultiIndex([('x1', 'grp'),
('x2', 'grp'),
('x3', 'grp'),
('x4', 'grp')],
names=['x', 'grp'])
(2) for loop 순환문(for x, grp in mult_idx:)으로 model = ols('{} ~ {}'.format(x, grp) 의 선형모델의 y, x 부분의 변수 이름을 바꾸어가면서 sm.stats.anova_lm(model, typ=1) 로 일원분산분석을 수행합니다. 이렇게 해서 나온 일원분산분석 결과 테이블을 anova_tables.append(anova_table) 로 순차적으로 append 해나가면 됩니다.
# ANOVA test for multiple combinations of X and Group
import statsmodels.api as sm
from statsmodels.formula.api import ols
anova_tables = []
for x, grp in mult_idx:
model = ols('{} ~ {}'.format(x, grp), data=df).fit()
anova_table = sm.stats.anova_lm(model, typ=1)
anova_tables.append(anova_table)
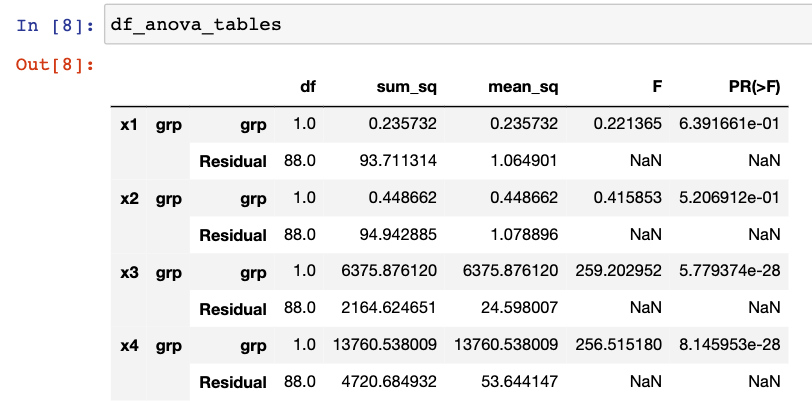
df_anova_tables = pd.concat(anova_tables, keys=mult_idx, axis=0)
df_anova_tables
[Out]
df sum_sq mean_sq F PR(>F)
x1 grp grp 1.0 0.235732 0.235732 0.221365 6.391661e-01
Residual 88.0 93.711314 1.064901 NaN NaN
x2 grp grp 1.0 0.448662 0.448662 0.415853 5.206912e-01
Residual 88.0 94.942885 1.078896 NaN NaN
x3 grp grp 1.0 6375.876120 6375.876120 259.202952 5.779374e-28
Residual 88.0 2164.624651 24.598007 NaN NaN
x4 grp grp 1.0 13760.538009 13760.538009 256.515180 8.145953e-28
Residual 88.0 4720.684932 53.644147 NaN NaN
anova tables
만약 특정 변수에 대한 일원분산분석 결과만을 조회하고 싶다면, 아래처럼 DataFrame의 MultiIndex 에 대해 인덱싱을 해오면 됩니다. 가령, 'x3' 에 대한 집단별 평균 차이 여부를 검정한 결과는 아래처럼 인덱싱해오면 됩니다.
## Getting values of 'x3' from ANOVA tables
df_anova_tables.loc[('x3', 'grp', 'grp')]
[Out]
df 1.000000e+00
sum_sq 6.375876e+03
mean_sq 6.375876e+03
F 2.592030e+02
PR(>F) 5.779374e-28
Name: (x3, grp, grp), dtype: float64
F 통계량과 p-value 에 대해서 조회하고 싶으면 위의 결과에서 DataFrame 의 칼럼 이름으로 선택해오면 됩니다.
Greenplum DB에서 PL/Python (또는 PL/R)을 사용하여 여러개의 숫자형 변수에 대해 일원분산분석을 분산병렬처리하는 방법(one-way ANOVA in parallel using PL/Python on Greenplum DB)은 rfriend.tistory.com/640 를 참고하세요.
2개의 모집단에 대한 평균을 비교, 분석하는 통계적 기법으로 t-Test를 활용하였다면, 비교하고자 하는 집단이 2개 이상일 경우에는분산분석 (ANOVA : Analysis Of Variance)를 이용합니다.
설명변수는 범주형 자료(categorical data)이어야 하며, 종속변수는 연속형 자료(continuous data) 일 때 2개 이상집단 간 평균 비교분석에 분산분석(ANOVA) 을 사용하게 됩니다.
분산분석(ANOVA)은 기본적으로분산의 개념을 이용하여 분석하는 방법으로서, 분산을 계산할 때처럼 편차의 각각의 제곱합을 해당 자유도로 나누어서 얻게 되는 값을 이용하여 수준평균들간의 차이가 존재하는 지를 판단하게 됩니다. 이론적인 부분에 대한 좀더 자세한 내용은 https://rfriend.tistory.com/131 를 참고하세요.
one-way ANOVA 일원분산분석
이번 포스팅에서는 Python의 scipy 모듈의 stats.f_oneway() 메소드를 사용하여 샘플의 크기가 서로 다른 3개 그룹 간 평균에 차이가 존재하는지 여부를 일원분산분석(one-way ANOVA)으로 분석하는 방법을 소개하겠습니다.
분산분석(Analysis Of Variance) 검정의 3가지 가정사항을 고려해서, 샘플 크기가 서로 다른 가상의 3개 그룹의 예제 데이터셋을 만들어보겠습니다.
[ 분산분석 검정의 가정사항 (assumptions of ANOVA test) ]
(1) 독립성: 각 샘플 데이터는 서로 독립이다. (2) 정규성: 각 샘플 데이터는 정규분포를 따르는 모집단으로 부터 추출되었다. (3) 등분산성: 그룹들의 모집단의 분산은 모두 동일하다.
먼저, 아래의 예제 샘플 데이터셋은 그룹1과 그룹2의 평균은 '0'으로 같고, 그룹3의 평균은 '5'로서 나머지 두 그룹과 다르게 난수를 발생시켜 가상으로 만든 것입니다.
이제 scipy 모듈의 scipy.stats.f_oneway() 메소드를 사용해서 서로 다른 개수의 샘플을 가진 3개 집단에 대해 평균의 차이가 존재하는지 여부를 일원분산분석을 통해 검정을 해보겠습니다.
- 귀무가설(H0): 3 집단의 평균은 모두 같다. (mu1 = mu2 = m3)
- 대립가설(H1): 3 집단의 평균은 같지 않다.(적어도 1개 집단의 평균은 같지 않다) (Not H0)
F통계량은 매우 큰 값이고 p-value가 매우 작은 값이 나왔으므로 유의수준 5% 하에서 귀무가설을 기각하고 대립가설을 채택합니다. 즉, 3개 집단 간 평균의 차이가 존재한다고 평가할 수 있습니다.
# ANOVA with different sized samples using scipy
from scipy import stats
stats.f_oneway(data1, data2, data3)
[Out]
F_onewayResult(statistic=262.7129127080777, pvalue=5.385523527223916e-44)
scipy 모듈의 stats.f_oneway() 메소드를 사용할 때 만약 데이터에 결측값(NAN)이 포함되어 있으면 'NAN'을 반환합니다. 위에서 만들었던 'data1' numpy array 의 첫번째 값을 np.nan 으로 대체한 후에 scipy.stats.f_oneway() 로 일원분산분석 검정을 해보면 'NAN'(Not A Number)을 반환한 것을 볼 수 있습니다.
샘플 데이터에 결측값이 포함되어 있는 경우, 결측값을 먼저 제거해주고 일원분산분석 검정을 실시해주시기 바랍니다.
# get rid of the missing values before applying ANOVA test
stats.f_oneway(data1[~np.isnan(data1)], data2, data3)
[Out]
F_onewayResult(statistic=260.766426640122, pvalue=1.1951277551195217e-43)
위의 일원분산분석(one-way ANOVA) 는 2개 이상의 그룹 간 평균의 차이가 존재하는지만을 검정할 뿐이며, 집단 간 평균의 차이가 존재한다는 대립가설을 채택하게 된 경우 어느 그룹 간 차이가 존재하는지는 사후검정 다중비교(post-hoc pair-wise multiple comparisons)를 통해서 알 수 있습니다. (rfriend.tistory.com/133)
pandas DataFrame 데이터셋에서 여러개의 숫자형 변수에 대해 for loop 순환문을 사용하여 집단 간 평균 차이 여부를 검정하는 방법은 rfriend.tistory.com/639 포스팅을 참고하세요.