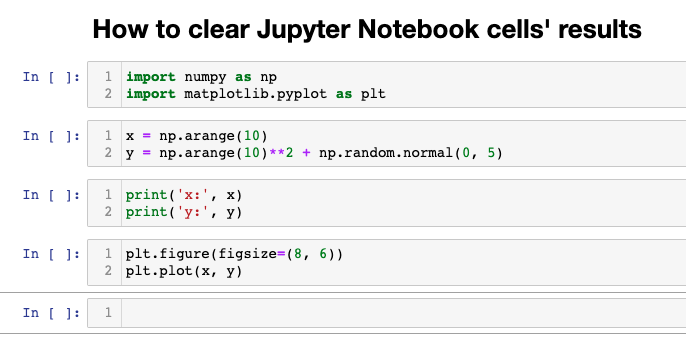
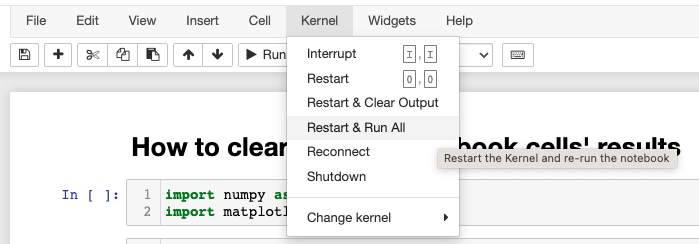
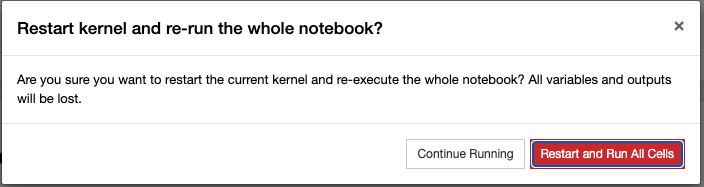
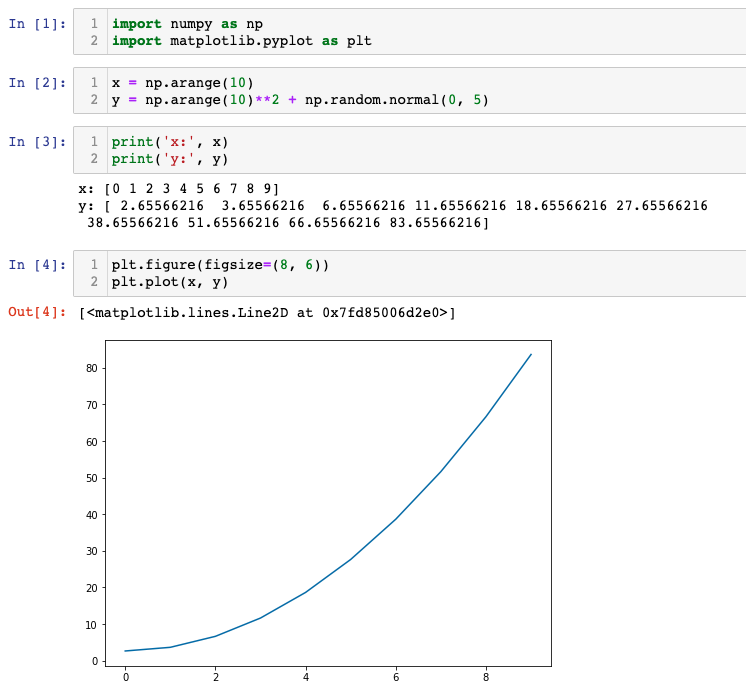
이번 포스팅에서는 Python의 List Comprehension 에 대해서 알아보겠습니다.
(번역하기가 애매해서 영어 원문 그대로 사용하겠습니다)
1. List Comprehension 이란?
Python의 List Comprehension 은 기존에 존재하는 List 에서 새로운 List 를 간결하게 생성하는 방법입니다.
List Comprehension Syntax 는 아래와 같습니다.
new_list = [expression for item in iterable if condition == True]

간단한 예를 들어서 설명해보겠습니다. 아래에 6개의 도시를 원소로 가지는 List 가 있습니다. 첫글자가 "S"로 시작하는 도시명을 원소로 가지는 새로운 List를 만든다고 했을 때, for loop 순환문과 if 조건절을 사용하는 방법이 있습니다.
city_list = ["Seoul", "New York", "London", "Shanghai", "Paris", "Tokyo"]
print(city_list)
# ['Seoul', 'New York', 'London', 'Shanghai', 'Paris', 'Tokyo']
## way 1: for loop and if conditional statement
city_s_1 = []
for city in city_list:
if "S" in city:
city_s_1.append(city)
print(city_s_1)
# ['Seoul', 'Shanghai']
첫글자가 "S"로 시작하는 도시명을 원소로 가지는 새로운 List를 만든다고 했을 때, List Comprehension 을 이용하면 아래와 같이 아주 간결하게 코드를 짤 수 있습니다.
## way 2: List Comprehension
## [expression for item in iterable if condition == True]
city_s_2 = [city for city in city_list if "S" in city]
print(city_s_2)
# ['Seoul', 'Shanghai']
2. 내장 range() 함수와 조건절을 사용한 List Comprehension
Python의 iterable 자료형으로 str, list, tuple, dictionary, set, range 등이 있는데요, 아래 예에서는 그중에서 내장 range() 함수로 0~9까지의 정수를 반복적으로 생성해서, if 조건절을 사용해 짝수로 구성된 새로운 List 를 만들어보겠습니다.
## range() 함수와 List Comprehension 으로 짝수 리스트 만들기
even_list = [i for i in range(10) if i%2 == 0]
print(even_list)
# [0, 2, 4, 6, 8]
3. if else 조건절을 사용해서 List Comprehension 만들기
if else 조건절을 List Comprehension 에서 사용할 때는 if else 조건절을 앞에 써주고, for loop 순환문을 뒤에 사용해줍니다. (* 위의 2번과 순서가 뒤바뀜에 주의)
## 짝수는 그대로, 홀수이면 99로 치환한 리스트
## if else 조건절이 앞에 있고, for 순환문이 뒤에 있음
if_else_list = [i if i%2 == 0 else 99 for i in range(10)]
print(if_else_list)
# [0, 99, 2, 99, 4, 99, 6, 99, 8, 99]
만약 for loop 순환문을 앞에 써주고 if else 조건절을 뒤에 써서 List Comprehension 을 시도하면 SyntaxError 가 납니다.
## SyntaxError: invalid syntax
[i for i in range(10) if i%2 == 0 else 99] #SyntaxError
4. 2D List 에 대해 중첩된 순환문(Nested for loops)을 사용해서 List Comprehension
4-1. 2D List 를 1D List 로 차원 줄이기 (flattening)
list_2d = [[11, 12],
[21, 22],
[31, 32],
[41, 42]
]
print(list_2d)
# [[11, 12], [21, 22], [31, 32], [41, 42]]
## flattening
## flattening
list_1d = [i for row in list_2d for i in row]
print(list_1d)
# [11, 12, 21, 22, 31, 32, 41, 42]
4-2. 2D List 를 전치(Transpose) 하기
## Transpose
list_transpose = [[row[i] for row in list_2d] for i in range(2)]
print(list_transpose)
# [[11, 21, 31, 41], [12, 22, 32, 42]]
5. eval() 함수에 List Comprehension 실행하기
Python의 eval() 함수는 동적으로 문자열 표현식을 평가하여 실행합니다. (참고: https://rfriend.tistory.com/798 )
eval() 함수에 List Comprehension 을 문자열 표현식으로 넣어서 실행할 수 있습니다.
## eval() 에 list comprehension 표현식(expression)사용 가능
str_list_comprehension = "[i for i in range(10) if i%2 == 0]"
eval(str_list_comprehension)
# [0, 2, 4, 6, 8]
하지만, 바로 위의 짝수 리스트를 만드는 List Comprehension 과 동일한 과업을 for loop 순환문과 if 조건절 statement 를 문자열로 만들어서 eval() 함수에 넣어 실행하려고 하면 SyntaxError 가 발생합니다. (eval() 함수는 expression 만 평가하여 실행가능하고, statement 는 평가 불가능함)
## eval()에 for loop 순환문과 if 조건절 statement 사용 불가
## SyntaxError: invalid syntax
str_for_if = """
new_list = []
for i in range(10):
if i%2 == 0:
new_list.append(i)
"""
eval(str_for_if) # SyntaxError: invalid syntax
6. List Comprehension 으로 새로운 Dict 만들기
str 자료형은 iterable 타입으로서, 아래처럼 List Comprehension 으로 각 단위문자 별로 쪼개서 새로운 List 로 만들 수 있습니다.
text = "abcde"
print([s for s in text])
# ['a', 'b', 'c', 'd', 'e']
아래의 예는 range() 함수와 text 를 iterable 하면서 zip() 으로 정수와 각 단위문자를 짝을 이루어서 for loop 순환문으로 발생시키고, 이를 {Key: Value} 로 해서 새로운 Dict 자료형을 만든 것입니다.
## list comprehension을 이용해서 dictionary 만들기
text = "abcde"
{k: v for k, v in zip(range(len(text)), text)}
# {0: 'a', 1: 'b', 2: 'c', 3: 'd', 4: 'e'}
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)

'Python 분석과 프로그래밍 > Python 설치 및 기본 사용법' 카테고리의 다른 글
| [Python] eval() 메소드: 동적으로 문자열 표현식을 평가하여 실행 (Evaluate expressions dynamically) (0) | 2023.05.21 |
|---|---|
| [Python] 유닉스 스타일 경로명 패턴 확장 glob, 파일명 패턴 매칭 fnmatch (0) | 2023.04.02 |
| [Python] 여러개의 Python 패키지, 모듈을 한꺼번에 설치하는 방법 (0) | 2023.03.12 |
| [Jupyter Notebook] 주피터 노트북의 Cell 결과 모두 지우고, 새로 시작하기 (0) | 2023.03.05 |
| [Python] 웹사이트에서 압축파일 다운받아 압축해제 후 데이터셋 합치기 (0) | 2021.10.07 |