[PostgreSQL, Greenplum] 스펙트럼 분석 PL/Python을 활용한 병렬처리
Greenplum and PostgreSQL Database 2022. 10. 23. 23:03이전 포스팅에서 스펙트럼 분석(spectrum analysis, spectral analysis, frequency domain analysis) 에 대해서 소개하였습니다. ==> https://rfriend.tistory.com/690 참조
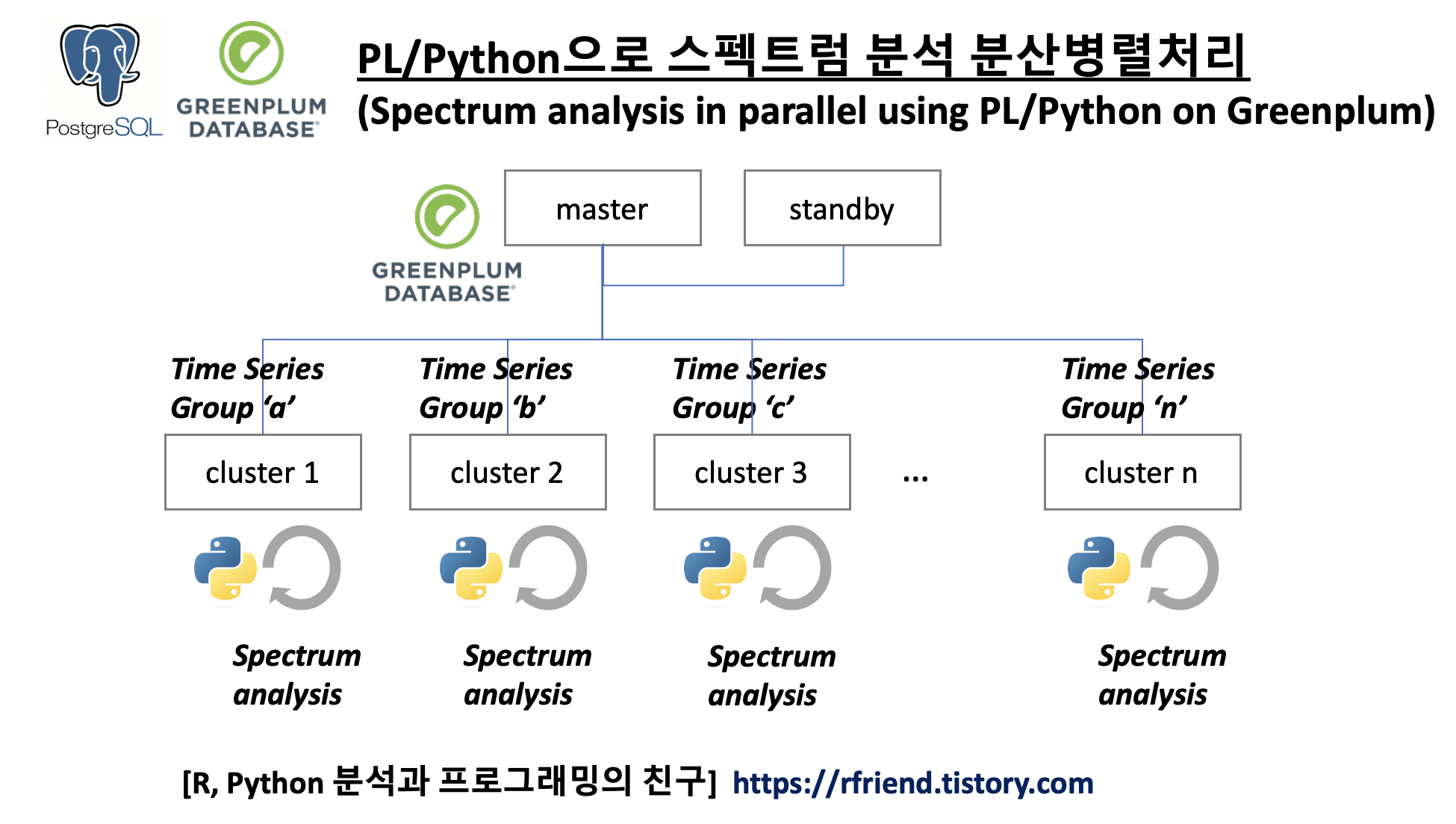
이번 포스팅에서는 Greenplum 에서 PL/Python (Procedural Language)을 활용하여 여러개 그룹의 시계열 데이터에 대해 스펙트럼 분석을 분산병렬처리하는 방법을 소개하겠습니다. (spectrum analysis in parallel using PL/Python on Greenplum database)
(1) 다른 주파수를 가진 3개 그룹의 샘플 데이터셋 생성
먼저, spectrum 모듈에서 data_cosine() 메소드를 사용하여 주파수(frequency)가 100, 200, 250 인 3개 그룹의 코사인 파동 샘플 데이터를 생성해보겠습니다. (노이즈 A=0.1 만큼이 추가된 1,024개 코사인 데이터 포인트를 가진 예제 데이터)
## generating 3 cosine signals with frequency of (100Hz, 200Hz, 250Hz) respectively
## buried in white noise (amplitude 0.1), a length of N=1024 and the sampling is 1024Hz.
from spectrum import data_cosine
data1 = data_cosine(N=1024, A=0.1, sampling=1024, freq=100)
data2 = data_cosine(N=1024, A=0.1, sampling=1024, freq=200)
data3 = data_cosine(N=1024, A=0.1, sampling=1024, freq=250)
다음으로 Python pandas 모듈을 사용해서 'grp' 라는 칼럼에 'a', 'b', 'c'의 구분자를 추가하고, 'val' 칼럼에는 위에서 생성한 각기 다른 주파수를 가지는 3개의 샘플 데이터셋을 값으로 가지는 DataFrame을 생성합니다.
## making a pandas DataFrame with a group name
import pandas as pd
df1 = pd.DataFrame({'grp': 'a', 'val': data1})
df2 = pd.DataFrame({'grp': 'b', 'val': data2})
df3 = pd.DataFrame({'grp': 'c', 'val': data3})
df = pd.concat([df1, df2, df3])
df.shape
# (3072, 2)
df.head()
# grp val
# 0 a 1.056002
# 1 a 0.863020
# 2 a 0.463375
# 3 a -0.311347
# 4 a -0.756723
sqlalchemy 모듈의 create_engine("driver://user:password@host:port/database") 메소드를 사용해서 Greenplum 데이터베이스에 접속한 후에 pandas의 DataFrame.to_sql() 메소드를 사용해서 위에서 만든 pandas DataFrame을 Greenplum DB에 import 하도록 하겠습니다.
이때 index = True, indx_label = 'id' 를 꼭 설정해주어야만 합니다. 그렇지 않을 경우 Greenplum DB에 데이터가 import 될 때 시계열 데이터의 특성이 sequence 가 없이 순서가 뒤죽박죽이 되어서, 이후에 스펙트럼 분석을 할 수 없게 됩니다.
## importing data to Greenplum using pandas
import sqlalchemy
from sqlalchemy import create_engine
# engine = sqlalchemy.create_engine("postgresql://user:password@host:port/database")
engine = create_engine("postgresql://user:password@ip:5432/database") # set with yours
df.to_sql(name = 'data_cosine',
con = engine,
schema = 'public',
if_exists = 'replace', # {'fail', 'replace', 'append'), default to 'fail'
index = True,
index_label = 'id',
chunksize = 100,
dtype = {
'id': sqlalchemy.types.INTEGER(),
'grp': sqlalchemy.types.TEXT(),
'val': sqlalchemy.types.Float(precision=6)
})
SELECT * FROM data_cosine order by grp, id LIMIT 5;
# id grp val
# 0 a 1.056
# 1 a 0.86302
# 2 a 0.463375
# 3 a -0.311347
# 4 a -0.756723
SELECT count(1) AS cnt FROM data_cosine;
# cnt
# 3072
(2) 스펙트럼 분석을 분산병렬처리하는 PL/Python 사용자 정의 함수 정의 (UDF definition)
아래의 스펙트럼 분석은 Python scipy 모듈의 signal() 메소드를 사용하였습니다. (spectrum 모듈의 Periodogram() 메소드를 사용해도 동일합니다. https://rfriend.tistory.com/690 참조)
(Greenplum database의 master node와 segment nodes 에는 numpy와 scipy 모듈이 각각 미리 설치되어 있어야 합니다.)
사용자 정의함수의 인풋으로는 (a) 시계열 데이터 array 와 (b) sampling frequency 를 받으며, 아웃풋으로는 스펙트럼 분석을 통해 추출한 주파수(frequency, spectrum)를 텍스트(혹은 int)로 반환하도록 하였습니다.
DROP FUNCTION IF EXISTS spectrum_func(float8[], int);
CREATE OR REPLACE FUNCTION spectrum_func(x float8[], fs int)
RETURNS text
AS $$
from scipy import signal
import numpy as np
# x: Time series of measurement values
# fs: Sampling frequency of the x time series. Defaults to 1.0.
f, PSD = signal.periodogram(x, fs=fs)
freq = np.argmax(PSD)
return freq
$$ LANGUAGE 'plpythonu';
(3) 스펙트럼 분석을 분산병렬처리하는 PL/Python 사용자 정의함수 실행
(Execution of Spectrum Analysis in parallel on Greenplum)
위의 (2)번에서 정의한 스펙트럼 분석 PL/Python 사용자 정의함수 spectrum_func(x, fs) 를 Select 문으로 호출하여 실행합니다. FROM 절에는 sub query로 input에 해당하는 시계열 데이터를 ARRAY_AGG() 함수를 사용해 array 로 묶어주는데요, 이때 ARRAY_AGG(val::float8 ORDER BY id) 로 id 기준으로 반드시 시간의 순서에 맞게 정렬을 해주어야 제대로 스펙트럼 분석이 진행이 됩니다.
SELECT
grp
, spectrum_func(val_agg, 1024)::int AS freq
FROM (
SELECT
grp
, ARRAY_AGG(val::float8 ORDER BY id) AS val_agg
FROM data_cosine
GROUP BY grp
) a
ORDER BY grp;
# grp freq
# a 100
# b 200
# c 250
우리가 (1)번에서 주파수가 각 100, 200, 250인 샘플 데이터셋을 만들었는데요, 스펙트럼 분석을 해보니 정확하게 주파수를 도출해 내었네요!.
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)

'Greenplum and PostgreSQL Database' 카테고리의 다른 글
| [PostgreSQL, Greenplum] 차원이 다른 Array를 2D Array로 aggregation 하기 (0) | 2023.03.05 |
|---|---|
| [Greenplum] PL/Python을 이용해서 병렬로 시계열 데이터 결측값 보간하기 (interpolation in parallel using PL/Python on Greenplum) (0) | 2023.01.23 |
| [PostgreSQL/ Greenplum] 정규분포에서 난수를 생성하여 샘플 테이블 만들기 (0) | 2022.09.04 |
| [PostgreSQL, Greenplum] 여러개의 문자열 매칭 SQL (0) | 2022.06.26 |
| [PostgreSQL, Greenplum] Window Functions, 윈도우 함수 (0) | 2022.02.13 |



