언어모델 평가 지표 Perplexity 란 무엇인가?
Deep Learning (TF, Keras, PyTorch)/Natural Language Processing 2024. 1. 30. 21:451. 언어모델 평가 지표 Perplexity 란 무엇인가?
Perplexity는 자연어 처리(NLP)에서 확률적 또는 통계적 모델의 품질을 평가하는 데 사용되는 척도입니다. 특히 언어 모델(Language Model)의 품질을 평가할 때 사용됩니다. Perplexity는 언어 모델이 샘플을 얼마나 잘 예측하는지를 정량화합니다. Perplexity 점수가 낮을수록 모델이 샘플을 예측하는 데 더 나은 것으로 간주됩니다.
더 기술적인 용어로, Perplexity는 모델이 예측을 할 때 얼마나 "당황"하거나 "혼란"을 겪는지를 측정합니다. 이는 모델에 따른 테스트 세트의 엔트로피(또는 평균 로그 가능도, average log-likelihood)의 지수로 계산됩니다. 언어 모델의 경우, 이는 본질적으로 모델이 다음 토큰(예: 문장에서의 단어)을 예측할 때 평균적으로 가지고 있다고 생각하는 선택의 수(the average number of choices), 분기 수 (number of branches)를 평가하는 것을 의미합니다.

- N: 총 데이터 개수
- t_nk: n개째 데이터의 k번째 값 (정답이면 1, 정답이 아니면 0)
- y_nk: 모델이 예측한 확률값 (0~1 사이의 실수 값)
만약 데이터 수가 한 개라면 언어 모델이 예측한 다음 단어의 확률의 역수 (inverse of the probability) 가 Perplexity 가 됩니다. 즉, 정답을 높은 확률로 예측을 제대로 했으면 이 확률의 역수인 Perplexity는 낮은 값을 가지고 됩니다.
언어 모델의 맥락에서, 낮은 Perplexity를 가진 모델은 테스트 데이터를 예측하는 데 더 정확하다고 간주됩니다. 이는 모델이 테스트 세트에 존재하는 언어 패턴을 더 잘 이해하고 있다는 것을 나타내며, 다른 모델을 비교하거나 모델의 성능을 향상시키기 위해 모델의 파라미터를 조정하는 데 유용한 지표가 됩니다.
2. Perplexity 예시
이 NLP 맥락에서의 Perplexity를 설명하기 위한 매우 간단한 예를 들어보겠습니다. 시퀀스에서 다음 단어를 예측하는 작업을 맡은 언어 모델이 있다고 가정해 보겠습니다. 매우 작은 테스트 세트에서 모델의 성능을 평가하는 데 Perplexity를 어떻게 사용할 수 있는지 살펴보겠습니다.
테스트 세트가 단 하나의 문장으로 구성되어 있다고 상상해 보겠습니다:
"The cat sat on the ___", 우리는 모델이 빈칸에 들어갈 단어를 예측하기를 원합니다. 간단하게 하기 위해, 모델이 빈칸을 채우기 위해 고려하는 가능한 단어가 네 개 있다고 가정합시다.
{mat, hat, cat, bat}
2-1. 성능이 우수한 언어 모델의 예
이제, 우리의 언어 모델이 이 단어들에 다음과 같은 확률을 할당한다고 가정해 보겠습니다.
- P(mat) = 0.8
- P(hat) = 0.1
- P(cat) = 0.07
- P(bat) = 0.03

이 확률을 바탕으로, 우리는 이 테스트 케이스에 대한 모델의 Perplexity를 계산할 수 있습니다. Perplexity는 exp(Cross-Entropy Loss)로 정의되며, 여기서 p(x)는 모델이 올바른 단어에 할당한 확률입니다. 간단하게 하기 위해, "mat"이 올바른 다음 단어라고 가정합시다. 이 단일 단어 예측에 대한 Perplexity는 "mat"의 확률만을 사용하여 계산될 것입니다, 왜냐하면 그것이 올바른 단어이기 때문입니다.
계산은 다음과 같습니다.
Perplexity = exp(-log(0.8)) = 1.25
올바른 단어 "mat"에 대해 모델이 0.8의 확률을 예측한 이 매우 단순화된 예제에서의 Perplexity는 대략 1.25입니다.
이는 평균적으로 모델이 1.25개의 동등하게 가능성 있는 단어 중에서 균등하게 올바르게 선택해야 하는 것처럼 혼란스러워한다는 것을 의미합니다. Perplexity가 낮을수록 더 나은 예측 성능을 나타내므로, 이 맥락에서 1.25의 Perplexity는 이 매우 단순화된 시나리오에서 다음 단어를 예측하는 데 있어 모델이 상대적으로 좋다는 것을 의미합니다.
2-2. 성능이 낮은 언어 모델의 예
아래에는 성능이 낮은 언어 모델이 "The cat sat on the ___" 다음에 나올 단어를 예측한 단어별 확률입니다.
{mat, hat, cat, bat}
- P(mat) = 0.1
- P(hat) = 0.5
- P(cat) = 0.3
- P(bat) = 0.1
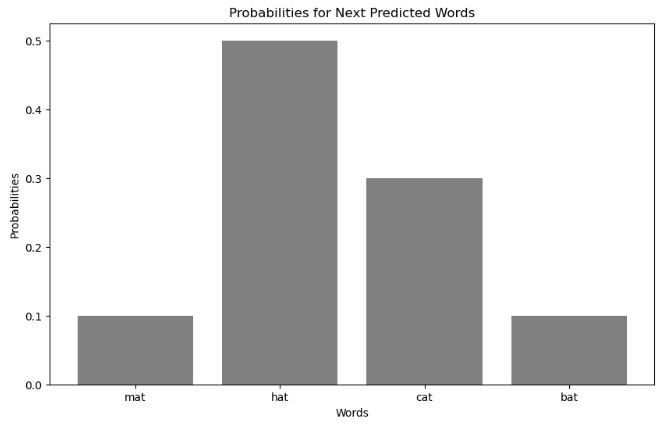
이때 정답은 mat 이라고 했을 때, 이 언어 모델의 Perplexity는
Perplexity(mat) = exp(-log(0.1)) = 10.0
이 됩니다. 즉, 위의 성능 좋은 언어 모델은 정답인 mat을 높은 확률로 예측했고 Perplexity가 1.25 였던 반면에, 이번에 성능이 낮은 언어 모델은 정답인 mat이 다음에 나올 확률을 0.1 로 매우 낮게 예측을 해서 Perplexity가 10.0 으로 높게 나왔습니다.
[ Reference ]
- Perplexity from Wikipedia: https://en.wikipedia.org/wiki/Perplexity
이번 포스팅이 많은 도움이 되었기를 바랍니다.
행복한 데이터 과학자 되세요! :-)




